将代码repeat_anova.R放入E盘主目录
setwd("E:\\")
source("repeat_anova.R")
数据格式如下(第一列为分组,后面为各时间点顺序):
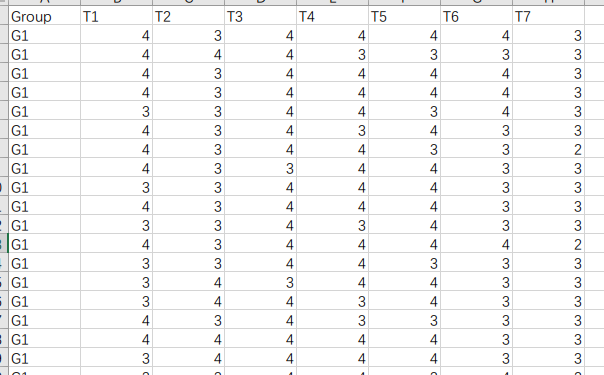
若数据在此目录下 , 则输入
, 则输入
setwd("E:\\我的坚果云\\work")
data = read.csv("data1.csv", header = T, sep=‘,‘)
# > head(data)
# X T1 T2 T3 T4 T5 T6 T7
# 1 G1 4 3 4 4 4 4 3
# 2 G1 4 4 4 3 3 3 3
# 3 G1 4 3 4 4 4 4 3
# 4 G1 4 3 4 4 4 4 3
# 5 G1 3 3 4 4 3 4 3
# 6 G1 4 3 4 3 4 3 3
输入数据信息,n.g为分组个数,n.t为时间点个数,N代表样本量
RES = repeat.anova(data,n.g = 5,n.t = 7,N = 150)
res = RES$res # res为主要结果
write.csv(res,"result1.csv")
RES$effect # effect是重复测量的分组效应,时间效应和交互效应
RES$note # 结果注释
原文:https://www.cnblogs.com/biostat-yu/p/14295859.html