
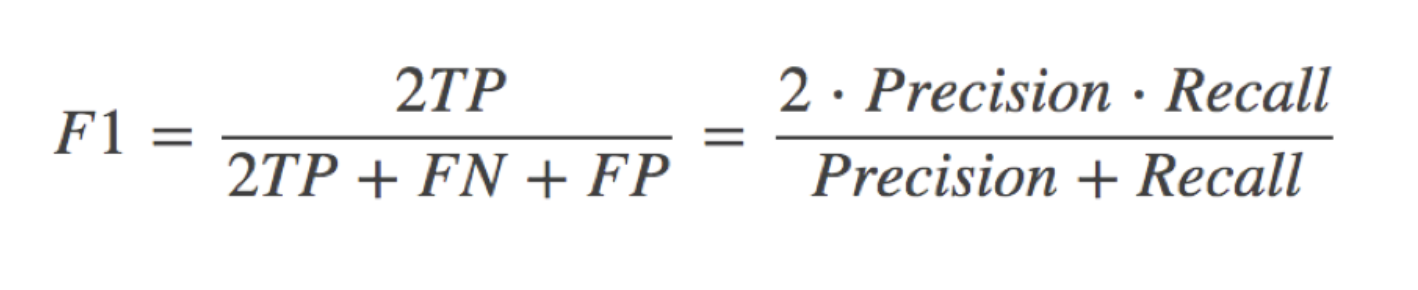
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,roc_auc_score
# 1.获取数据
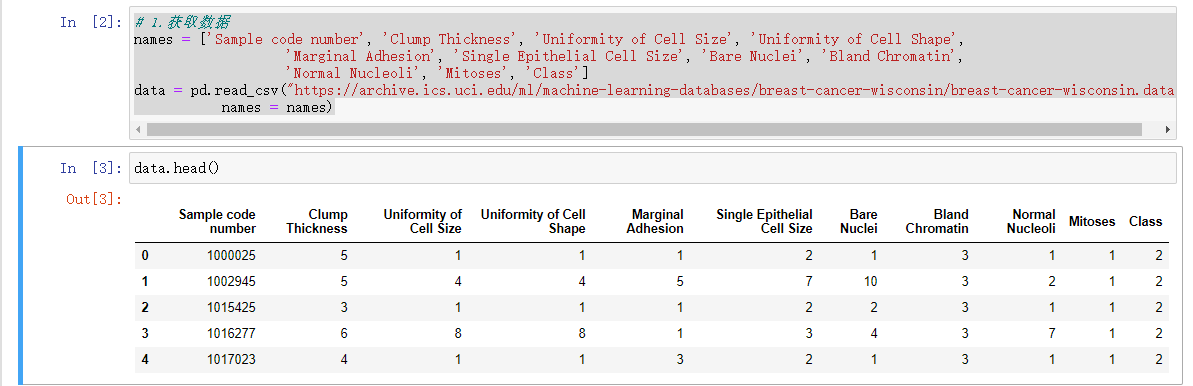
names = [‘Sample code number‘, ‘Clump Thickness‘, ‘Uniformity of Cell Size‘, ‘Uniformity of Cell Shape‘,
‘Marginal Adhesion‘, ‘Single Epithelial Cell Size‘, ‘Bare Nuclei‘, ‘Bland Chromatin‘,
‘Normal Nucleoli‘, ‘Mitoses‘, ‘Class‘]
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names = names)
# 2.1 缺失值处理
data = data.replace(to_replace="?",value=np.nan)
data = data.dropna()
# 2.2 确定特征值,目标值
x = data.iloc[:,1:-1]
x.head()
y = data["Class"]
y.head()
# 2.3 分割数据
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=22,test_size=0.2)
# 3.特征工程(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习(逻辑回归)
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
# 模型评估
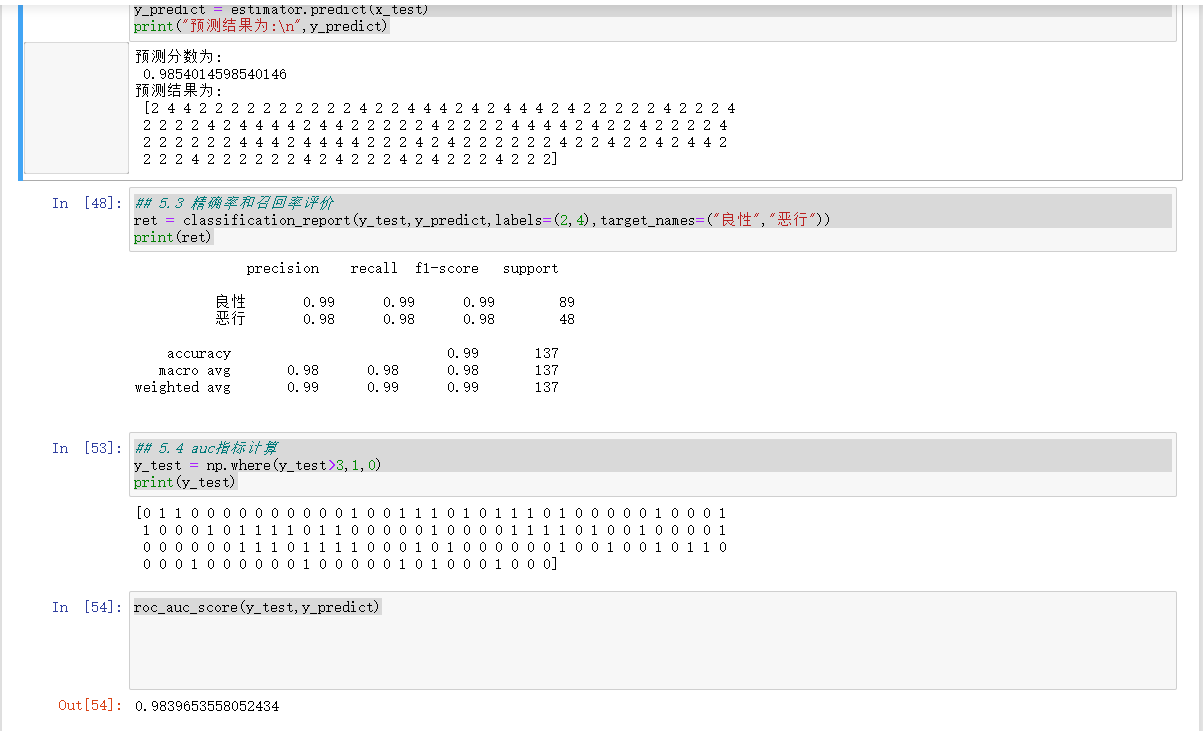
# 5.1 打印分数
score = estimator.score(x_test,y_test)
print("预测分数为:\n",score)
# 5.2 打印预测结果
y_predict = estimator.predict(x_test)
print("预测结果为:\n",y_predict)
## 5.3 精确率和召回率评价
ret = classification_report(y_test,y_predict,labels=(2,4),target_names=("良性","恶行"))
print(ret)
## 5.4 auc指标计算
y_test = np.where(y_test>3,1,0)
print(y_test)
roc_auc_score(y_test,y_predict)
原文:https://www.cnblogs.com/yangxiao-/p/14290292.html