在redis3.0版本中支持了cluster集群部署的方式,这种集群部署的方式能自动将数据进行分片,每个master上放一部分数据,提供了内置的高可用服务,即使某个master挂了,服务还可以正常地提供,我们先来看张图:
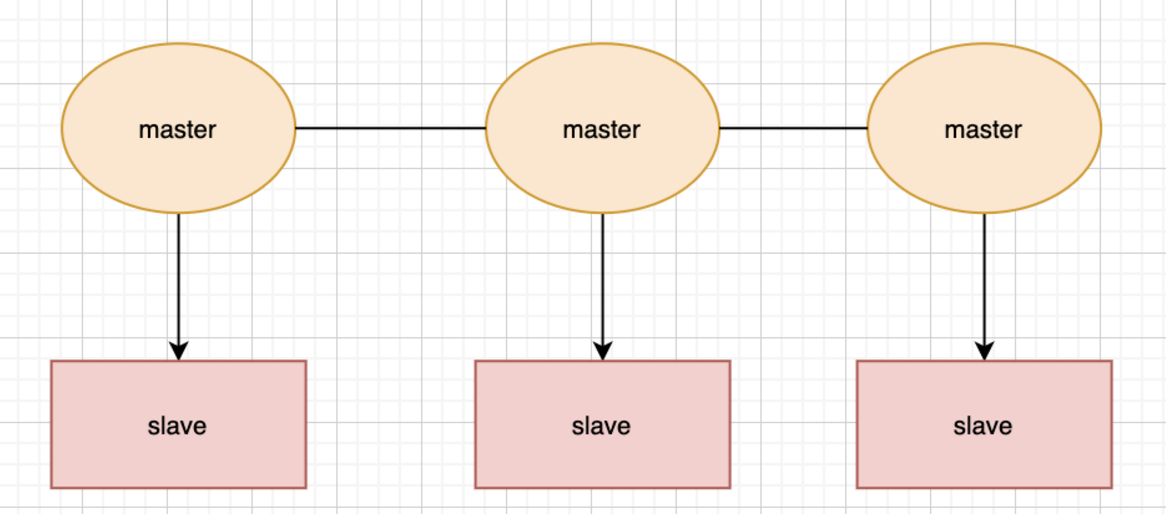
使用cluster集群模式,只需要将每个数据库节点的cluster-enabled配置选项打开即可,但是每个cluster集群至少要保证有3个主数据库才能正常运行。
一个cluster集群中总共有16384个节点,集群会将这16384个节点平均分配给每个节点,当然,我这里的节点指的是每个主节点,就如同下图:
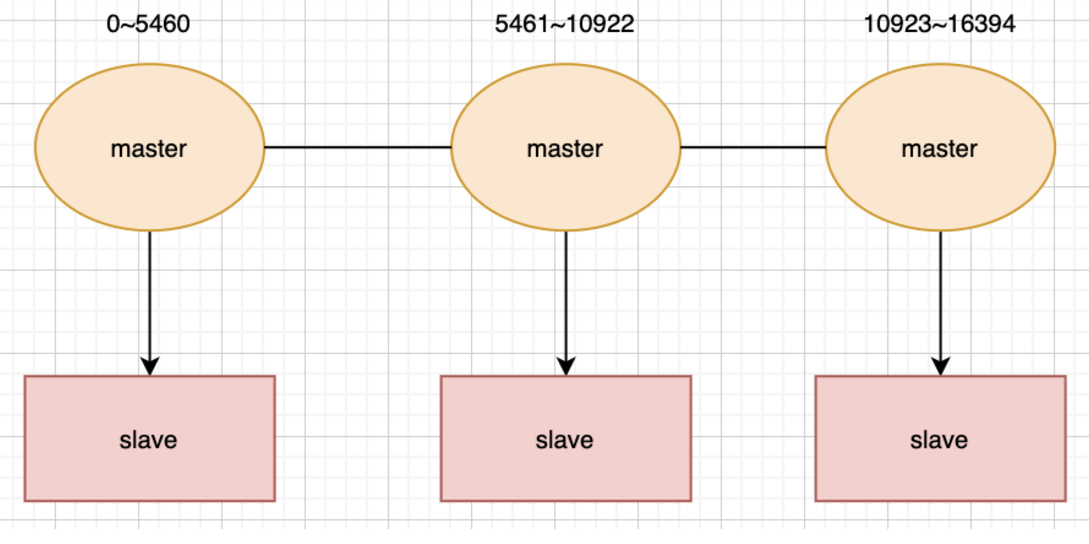
redis将每个redis的键的键名有效部分使用CRC16算法计算出散列值,然后与16384取余数,这样的就可以使每个键能够尽量的均匀分布在16384个插槽中。
第一种情况可以通过cluster add slot s 命令来实现
第二种情况的原理相对麻烦一点,但是redis也提供的便捷的方式去操作,我们可以使用redis-trib.rb去实现
当客户端向redis集群中的任意一个节点发送命令后,该节点都会判断当前键的信息是否存在于当前节点:
如果存在,那么就会像单机的reids一样执行命令。
如果不存在,就会返回一个move重定向请求,告诉客户端负责该数据的节点是哪一个,然后客户端会向该节点发送命令再次请求获取数据
需要通过cluster meet命令来实现:
cluster meet ip port
ip port 是我们已运行的redis集群中任意一个节点的地址和端口号,新节点在客户端输入命令后,会与命令中的节点进行握手,握手后,命令中的集群节点会将这个新节点的信息分享给集群中的每一个节点。
判断故障的逻辑其实与哨兵模式有点类似,在集群中,每个节点都会定期的向其他节点发送ping命令,通过有没有收到回复来判断其他节点是否已经下线。
如果长时间没有回复,那么发起ping命令的节点就会认为目标节点疑似下线,也可以和哨兵一样称作主观下线,当然也需要集群中一定数量的节点都认为该节点下线才可以,我们来说说具体过程:
这个问题也是我们之前抛出来的问题,我们放一张图大家就会很容易明白了:
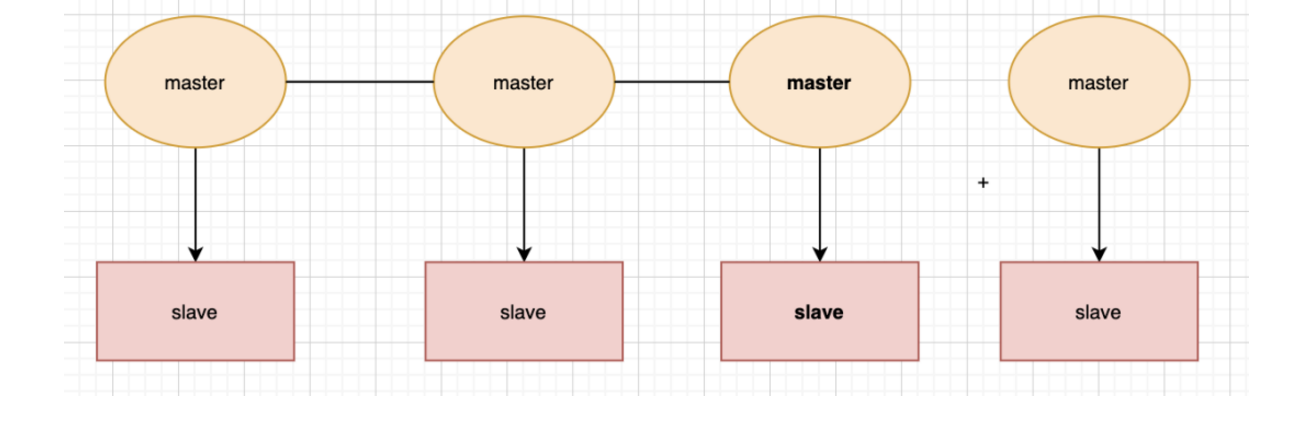
提高写能力只需要横向扩容master
提高读能力只需要横向扩容slave
关于这三种部署的方式,基本上在我知道的公司都毫无疑问直接选择cluster模式,当然具体的选择还是要看公司的规模了,毕竟技术服务于业务,选择合适于当前业务的,就是最好的。
原文:https://www.cnblogs.com/Elaborate/p/14245497.html