相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库中。每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而别的某些行又切分到其他的数据库中。
1.选择要拆分的表
Mysql单表存储数据条数是有瓶颈的,单表达到1000万条数据时就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表)进行优化。
列如:当orders 和 orders_detail都达到600万行数据,需要进行分表优化。
2.分表字段
以orders 表为列,可以根据不同字段进行分表
| 编号 | 分表字段 | 效果 |
|---|---|---|
| 1 | id(主键、或创建时间) | 查询订单注重时效,历史订单被查询的次数少,如此会形成一个节点访问多,一个节点访问少。 |
| 2 | customer_id(客户id) |
3.修改配置文件schema.xml
#为orders 表设置数据节点dn1,dn2,并指定分片规则mod_rule(自定义的名字) <table name="orders" dataNode="dn1,dn2" rule="mod_rule"></table>

4.修改配置文件rule.xml
#在rule 配置文件里面新增分片规则mod_rule,并指定规则适用字段为customer_id #还有选择分片算法mod-long(对字段取模运算),customer_id对两个节点取模,根据结果分片 #配置算法mod-long参数count为2,两个节点 <tableRule name="mod_rule"> <rule> <columns>customer_id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule>
往下找到算法的具体实现

6.重启mycat。
7.访问mycat实现分片
insert into orders(id,order_type,customer_id,amount)values(1,1,1,1000.00); insert into orders(id,order_type,customer_id,amount)values(2,1,2,1000.00); insert into orders(id,order_type,customer_id,amount)values(3,1,3,1000.00); insert into orders(id,order_type,customer_id,amount)values(4,1,4,1000.00); insert into orders(id,order_type,customer_id,amount)values(5,1,5,1000.00); insert into orders(id,order_type,customer_id,amount)values(6,1,6,1000.00);
查询mycat:
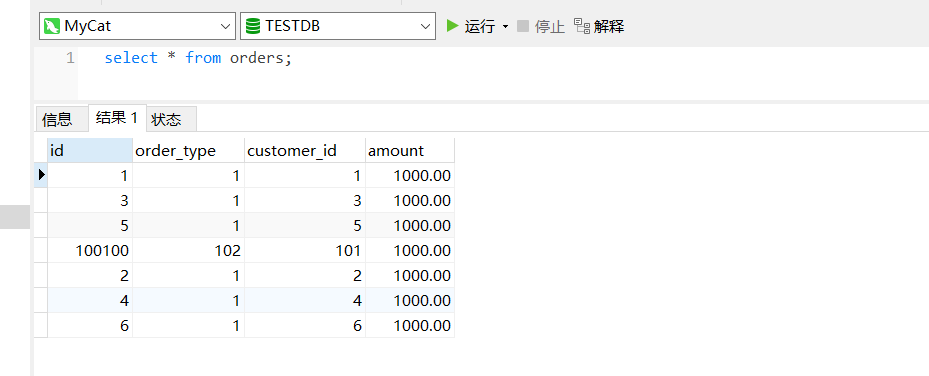
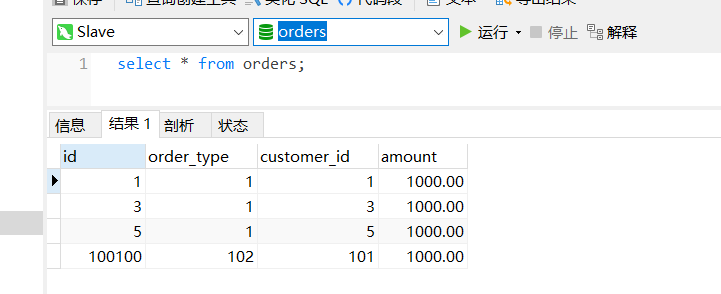
dn1:
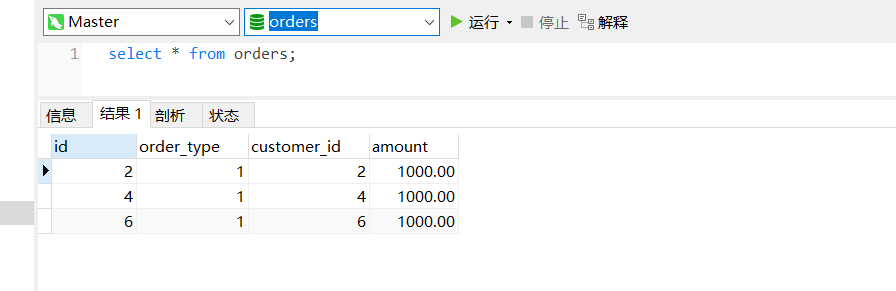
dn2:
原文:https://www.cnblogs.com/chenjiahao9527/p/14210334.html