简单来说,正则表达式是根据一定的语法规则组合而成的用来匹配具有某种模式的文本的字符串。
维基百科定义如下:
正则表达式,又称正规表示式、正规表示法、正规运算式、规则运算式、常规表示法(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
正则表达式在台湾又译作正规表达式,英文名称表示 “某种规则的表达式” 的意思,目前主流的文本编辑器(source insight/sublimtext/ultra edit/emacs/notepad++/vim) 和主流计算机语言(perl/python/PHP/java/.NET/tcl/c/c++)都支持正则表达式。它简单,优美,功能强大,妙用无穷。大数据时代的到来,因其快捷强大的文本处理能力必然在数据挖掘处理中发挥越来越重要的作用。
正则表达式由一般字符和特殊字符组成,一般字符指常见的字符本身,比如123Aaf0=;~#@%这些简单字符。通过简单地排列组合这些字符可以实现对复杂字符串的精确匹配。先放一张 python 的正则字符列表,下面逐一介绍。
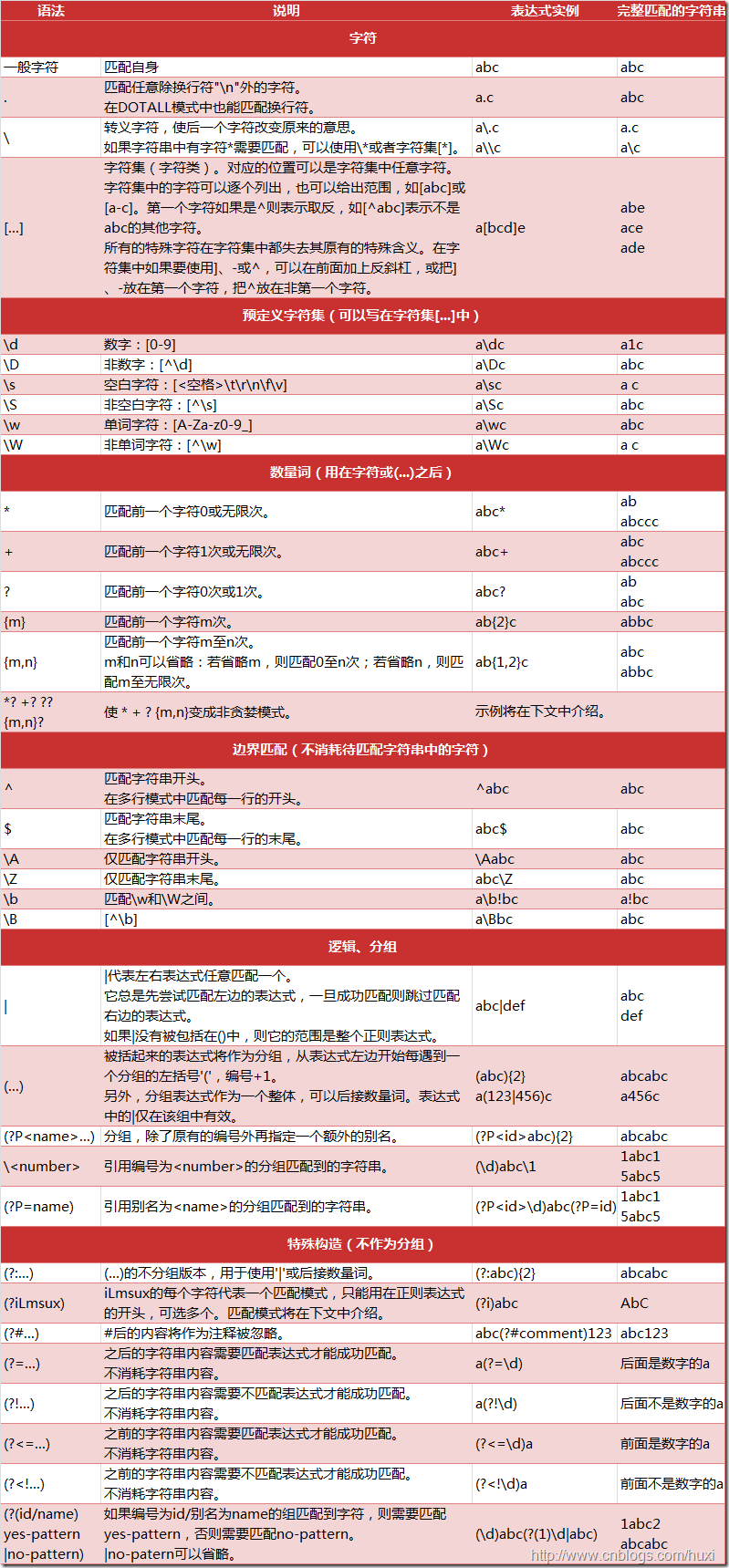
元字符
除了一般字符之外,python 规定了.^$*+?{}[]()\|这 14 个元字符,它们分别具有特殊的含义,有的代表量词,有的代表分组,有的代表逻辑等等(具体可参见上表)。正则表达式使用\作为转义字符,例如 \ s 代表空格,使用 \ t 代表 tab 等,我们将转义字符与其组合归类到一般字符。
注意字符集[],它匹配内容是括号中的任何一个字符,比如[a0d]表示匹配 a 或者 0 或者 d,而不是匹配a0,0d或者a0d。关于字符集需要注意如下两点:
[a\.0]匹配dlkll\fd,因为其中有\;^表示不匹配字符集中的任意字符,比如[^\da-f]表示不匹配数字及字母 a~f 中的任意字符。与 python 原生的字符串方法不同的是,正则表达式可以使用量词,位置匹配,字符组合,分组捕获等更强大的功能实现更复杂的字符处理功能。
量词
特殊字符中的+*?三个字符是量词字符,描述在它们之前紧挨着它们的字符连续重复的数量。比如量词a{100}就代表 a 连续重复 100 次,而a+表示 a 出现至少一次,其他的具体的内容可参见表格。
位置字符
正则表达式不仅可以匹配字符也可以匹配位置,这些字符包括^$\b\A\Z\B,比如匹配以 Atom 开头的行,就是^Atom,其他字符的具体含义可以参见表格。
逻辑
|表示或,所有的字符中优先级最低,比如girl|boy表示匹配 girl 或者 boy,而不是girloy或者girboy。
有了以上的基础知识,就可以完成大部分简单的正则表达式了,比如官方文档中的例子,尝试用正则表达式a[bcd]*b去匹配abcbd。具体的匹配步骤如下表所示
| Step | Matched | Explanation |
|---|---|---|
| 1 | a |
正则表达式中的 a |
| 2 | abcbd |
引擎匹配 [bcd]*,匹配尽可能多的字符直到目标字符串结尾 |
| 3 | 失败 | 引擎尝试匹配 b,但是目前已经到了字符串结尾,所以无字符匹配,失败 / |
| 4 | abcb |
回溯一个字符(即d),因此 [bcd]* 少匹配一个字符 |
| 5 | 失败 | 再次尝试匹配 b ,但是当前未匹配字符只有 ‘d‘,再次失败 |
| 6 | abc |
再次回溯一个字符(即b), 因而 [bcd]*仅仅匹配bc |
| 6 | abcb |
再次尝试匹配 b 。 这次未匹配字符当前位置就是 ‘b‘,因此成功 |
从以上的匹配过程可以看到,正则表达式匹配过程就是引擎从左到右逐个搜索目标字符串,匹配正则表达式中所有字符代表的模式,如果搜索完整个字符串仍然没有找到就失败。推荐使用网站 regex101.com 选择 python 语言,练习正则表达式。网站截图如下所示,它用蓝色底块标识了表达式匹配的内容,直观好用。
上面的例子里的第二步,*会尽可能地匹配符合表达式的所有字符,引擎就像一个贪婪的胖子,一口气吞下所有可以吞下去的东西,这就是正则表达式的贪婪模式。构造正则表达式时需要特别小心地处理具有相同属性的量词字符?{m,n}+,不然往往会产生意想不到的结果。
比如使用正则表达式<.*>尝试匹配<a>b<c>的中的<a>,却匹配了整个表达式。为了仅仅匹配<a>,需要在*后加上?,即使用<.*?>就能成功。二者的具体的区别如下表所示
| 表达式 | 步骤 |
|---|---|
<.*> |
先匹配<,再匹配.*,此时吞下所有的符号,最后从最后一个字符开始,吐一个字符匹配一次>,直到成功为止 |
<.*?> |
先匹配<,再匹配.*?,此时一个字符一个字符吞,每吞一个字符就立马匹配>,直到成功为止 |
在量词之后加上?表示非贪婪模式或者最小模式,吐到第三个字符为止,因此它找到了最小的<.*>的模式。
正则表达式中字符\b^$\A\Z\B|不占有任何字符,但是定义字符的边界,它们都是零宽 (zero-width) 字符。比如\b\w+\b表示匹配一个单词,而其中的\b表示单词的边界。
字符处理不仅仅需要判断是否匹配,我们常常希望提取相关模式的字符串,获得对应的信息,比如从网页源代码中提取邮件地址。此时就可以利用正则表达式的分组功能捕获字符,上面表中的的 group 就可以抓取不同的分组字符。比如,需要从下面字符中提取邮件的发件人信息
From: author@example.com
User-Agent: Thunderbird 1.5.0.9 (X11/20061227)
MIME-Version: 1.0
To: editor@example.com
使用^From:\s*([\w@.]+)抓取信息,其中有 2 个括号,就是分别分组捕获发件人和日期。从左到右以(的出现顺序为序,分别是第 1 个分组第 2 个分组依次类推,使用编号就可以重复对应括号分组的模式。
举个例子,匹配类似abba的单词,使用正则表达式\b([a-zA-Z])([a-zA-Z])\2\1\b,其中的 \ 1 和 \ 2 就分别表示与第 1 个和第 2 个分组相同的内容,依次类推。
如果分组很多,数字编号数数会很累,也可以使用(?P<name>...)命名,之后再使用(?P=name)引用,比如下面的代码
>>> p = re.compile(r‘(?P<word>\b\w+\b)‘)
>>> m = p.search( ‘(((( Lots of punctuation )))‘ )
>>> m.group(‘word‘)
‘Lots‘
>>> m.group(1)
‘Lots‘
其中的<word>表示匹配的分组名字是word,使用 group() 方法使用名字即可调用这个分组内容。
除此之外,还有如下 5 个特殊的分组匹配符号和正常的匹配符号相似,但是它们匹配...的表达式,却不捕获内容。
(?:...)。非捕获分组,表示匹配… 表示的表达式,但是它不捕获内容,因此不能以\1和<name>的方式被引用。比如
>>> m = re.match("([abc])+", "abc")
>>> m.groups()
(‘c‘,)
>>> m = re.match("(?:[abc])+", "abc")
>>> m.groups()
()
第二个表达式什么都没有匹配。
(?=...)。肯定正序环视 (Positive lookahead),跟在匹配字符之后,表示接下来匹配… 的字符,比如Isaac (?=Asimov)匹配后面跟着 Asimov 的 Isaac。
(?!...)。否定正序环视 (Negative lookahead) 与上面的意思刚好相反,表示不匹配…。
举个例子匹配形如foo.txt的文件名,但是要求文件的扩展名不是bar,就可以使用.*[.](?!bar).*$匹配。
(?<=...)。肯定逆序环视 (Positive lookbehind) 跟在匹配字符之后,表示之前匹配… 的字符,比如(?<=abc)def匹配abcdef,表示之前为abc的def。
(?<!...)。否定逆序环视 (Negative lookbehind) 表示之前不匹配…,与上一条意思刚好相反。
另一个需要留心的问题是正则表达式的优先级,它表示解读正则表达式时对一般字符及字符组(用()括起来的一般字符的组合)的粘度,最低的是|(表中未列出),具体可参考如下的优先级列表。
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (???, (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \ 任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
结合以上的例子,解读如下正则表达式。
[-+]?(\d*\.\d+|\d+)拿到一个正则表达式,首先看它有哪些运算符,然后依照从最高到最低优先级每个运算符去粘挨着它的字符,按照尽量多地将相同优先级的字符粘在在一起形成更大的字符,比如d*\.\d+就是一个大字符,最后就将所有的运算符和字符遍历完为止。
这个正则表达式匹配+.989,-9.989,+989,-989,.989这些小数或者整数。
[1-9]\d{4,}Windows(?=95|98|NT)[1-9]\d{5}附表
此外附上网站 deerchao 总结的常见正则表达式列表
| 说明 | 正则表达式 |
|---|---|
| 网址(URL) | [a-zA-z]+://[^\s]* |
| IP 地址 (IP Address) | ((2[0-4]\d\|25[0-5]\|[01]?\d\d?)\.){3}(2[0-4]\d\|25[0-5]\|[01]?\d\d?) |
| 电子邮件 (Email) | \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* |
| QQ 号码 | [1-9]\d{4,} |
| HTML 标记 (包含内容或自闭合) | <(.*)(.*)>.*<\/\1>\|<(.*) \/> |
| 密码 (由数字 / 大写字母 / 小写字母 / 标点符号组成,四种都必有,8 位以上) | (?=^.{8,}\$)(?=.*\d)(?=.*\W+)(?=.*[A-Z])(?=.*[a-z])(?!.*\n).*$ |
| 日期 (年 - 月 - 日) | (\d{4}\d{2})-((1[0-2])(0?[1-9]))-(([12][0-9])(3[01])(0?[1-9])) |
| 日期 (月 / 日 / 年) | ((1[0-2])(0?[1-9]))/(([12][0-9])(3[01])(0?[1-9]))/(\d{4}\d{2}) |
| 时间 (小时: 分钟, 24 小时制) | ((10?)[0-9]2[0-3]):([0-5][0-9]) |
| 汉字 (字符) | [\u4e00-\u9fa5] |
| 中文及全角标点符号 (字符) | [\u3000-\u301e\ufe10-\ufe19\ufe30-\ufe44\ufe50-\ufe6b\uff01-\uffee] |
| 中国大陆固定电话号码 | (\d{4}-\d{3}-)?(\d{8}\d{7}) |
| 中国大陆手机号码 | 1\d{10} |
| 中国大陆邮政编码 | [1-9]\d{5} |
| 中国大陆身份证号 (15 位或 18 位) | \d{15}(\d\d[0-9xX])? |
| 非负整数 (正整数或零) | \d+ |
| 正整数 | [0-9]*[1-9][0-9]* |
| 负整数 | -[0-9]*[1-9][0-9]* |
| 整数 | -?\d+ |
| 小数 | (-?\d+)(\.\d+)? |
| 不包含 abc 的单词 | \b((?!abc)\w)+\b |
原文:https://www.cnblogs.com/bugxch/p/14190972.html