参考文献:
Transformer模型详解_u012526436的博客-CSDN博客?blog.csdn.net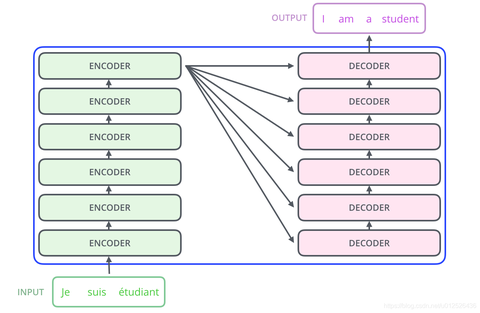
NLP中有许多mask ,如果不了解可以点开下面的链接阅读....
《NLP 中的Mask全解》 - cx_2016 - 博客园?www.cnblogs.com
这篇博客说的实在太详细了。大家可以仔细看博客理解相关模块知识。
所以下面将主要针对Transformer的代码段进行解读。以备用在今后的研究中。其实为什么需要读源码。是因为有时候我们可能根据自己的需求需要修改某部分模块,也就是拆解模块,此时我们就不能当调包侠了。只能乖乖看源码进行修改。但是我一般也不太会直接看源码,因为源码已经将提升性能的代码都用进去,看起来就比较费劲。所以我一般直接看一些能够按照文章走得通,很多人fork 且运行良好的代码进行相应的修改实现。
蛐蛐xjtu:对Transformer中的Positional Encoding一点解释和理解?zhuanlan.zhihu.com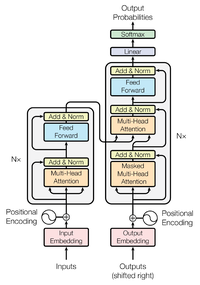
这一篇是针对positional encoding 的解释
The Illustrated Transformer【译】?blog.csdn.net
上面是非常详解的介绍整个模型的训练过程
等我看懂了大佬们实现的pytorch再分享pytorch码
https://github.com/jadore801120/attention-is-all-you-need-pytorchhttps://andrewpeng.dev/transformer-pytorch/下面主要记录代码片段的部分理解
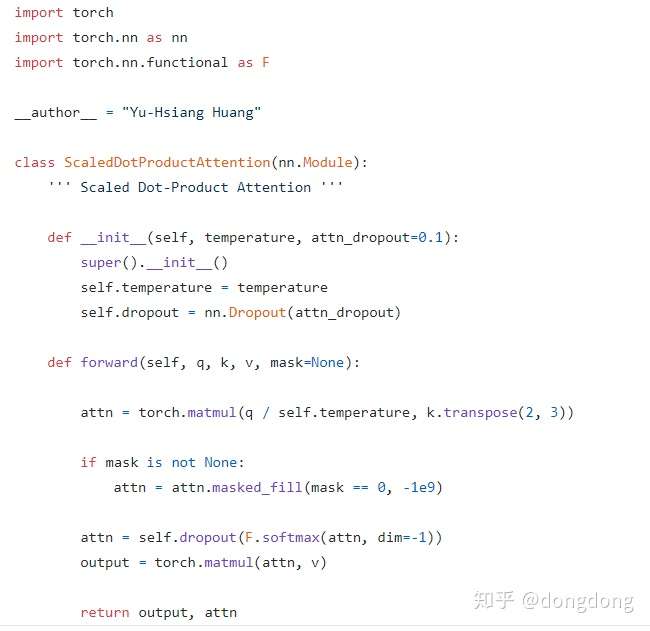 这段实现就是下面的结构图的实现
这段实现就是下面的结构图的实现
代码中的mask 来标记是否是mask self attetion。因为transformer在编码器没有mask模块,在解码器中有mask模块,会将所有未来的输入量mask掉。该函数mask_fill是mask==0的地方用一个很大的负数代替。-10的9次方。其他位置不改变原先的数值。
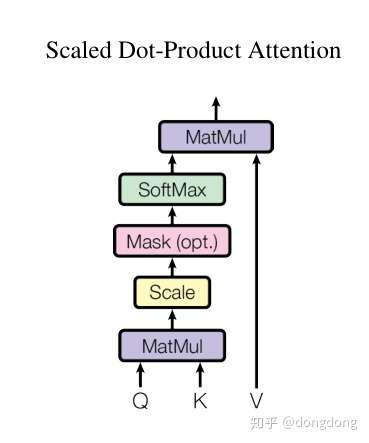
具体scaled dot-product attention对应transformer的哪一块?应该在self attention的模块,Q/K/V是该模块的输入,该模块的输出就是,attention值点乘各模块的Value值。
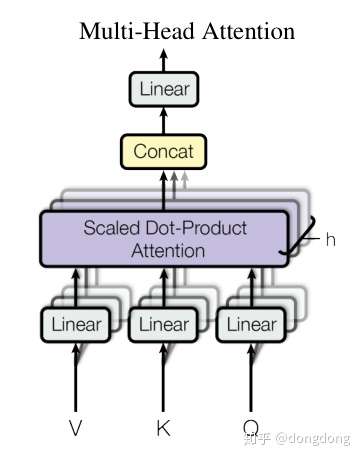

 图中解释的是Muti-attention的代码段
图中解释的是Muti-attention的代码段
在整个模块的全景图的位置如下(对应的编码器的Multi-Head attention与解码器的Masked Multi-Head attention ,根据传参中mask的有无,确定切换哪种模块):目前看来,开头的residual 赋值应该是输入的embedding 的词向量。然后再进行矩阵变换生成对应的QKV各个矩阵。residual模块的实现就是上面模块scaled dot-product attention的输出值+residual(一开头输入向量的词嵌入)。
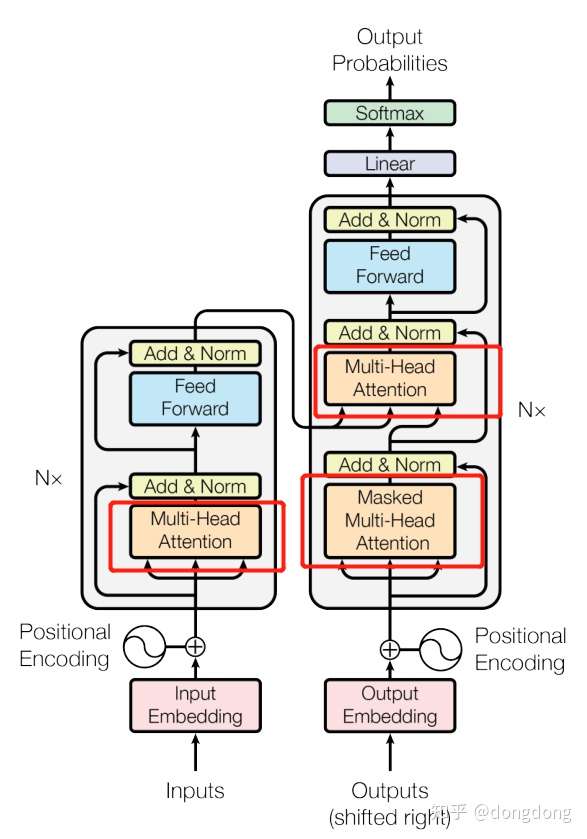
但是上面代码块将残差部分与layer-norm也连带的封装到此类中。可能是这两块太简单了。就直接并到multi-head attention.
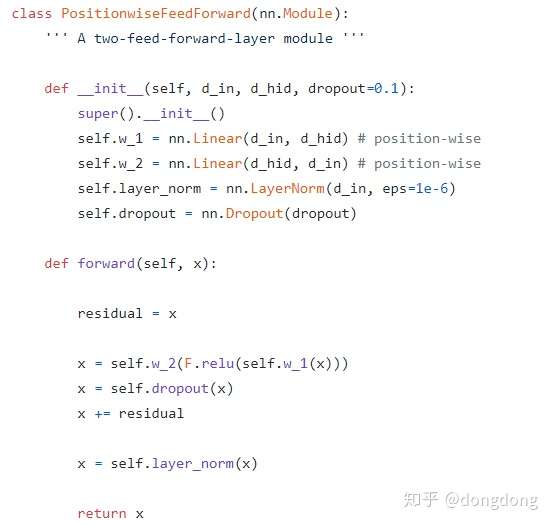
这块代码实现的就是编码器经过multi-head attention模块之后输入的两层前馈神经网络,使用了Relu的激活函数。并且也使用了Layer-norm+残差结构。
对应的结构图如下:
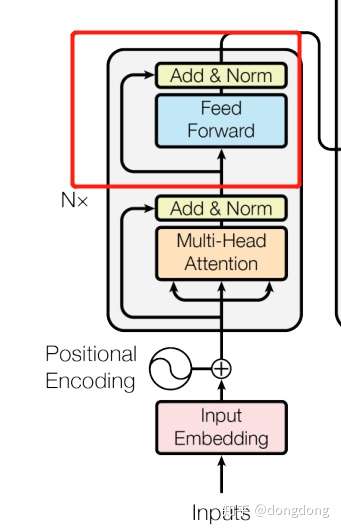 Position-wise feed forward
Position-wise feed forward
由于代码相对简单,此处不再赘述。上面两个部分就实现了transformer的编码器部分。
下面看一下整体的Encoder模块的代码。
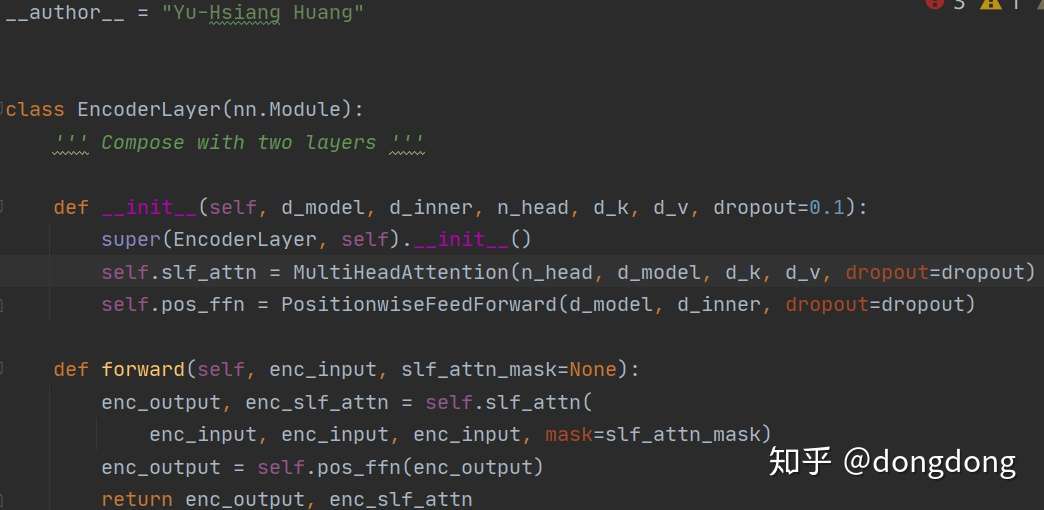
这个Encoder Layer模块还是很直接,将之前的两个模块直接进行顺序排列即可。我们也可以看出此处Multi-head attention 有三个重复的输入参数,也就是在Multi-head attention 函数开头处,q、k、v的随意一个赋值给residual都可以。
那么我们再来看看Decoder Layer代码又会是什么样子?
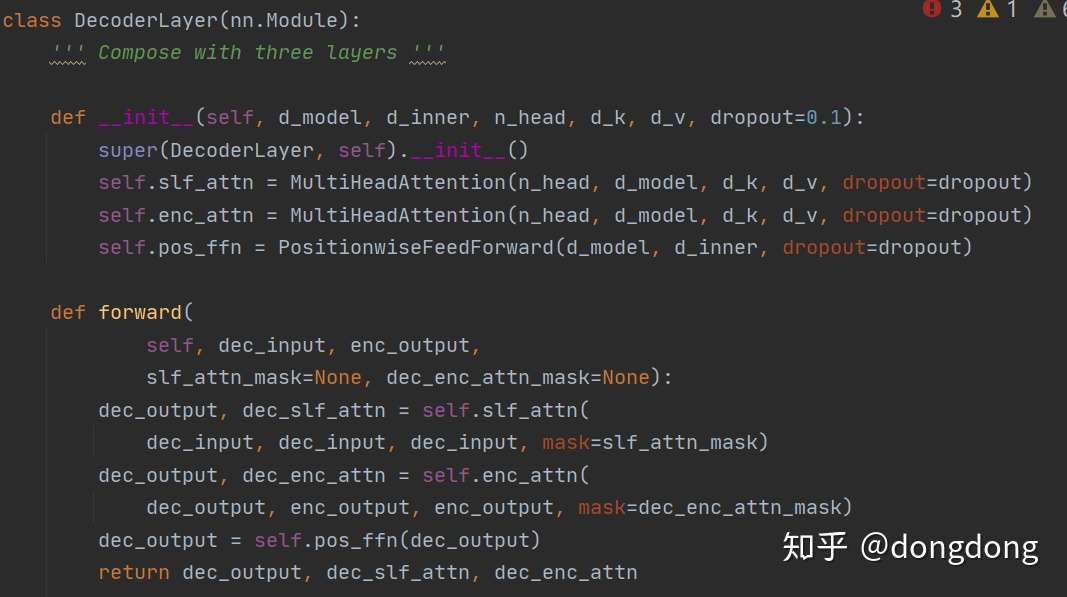
同样与Encoder Layer代码一样简洁。但是我们还要细细的看代码。因为下图的红框还是需要去细看如何实现。此处代码第一个multi-head输入的是dec_input.第二个multihead 的输入是Q 为 dec_out上一层的输出,K与V则对应encoder层的输出作为输入。至此Decoder Layer 部分已经看完。
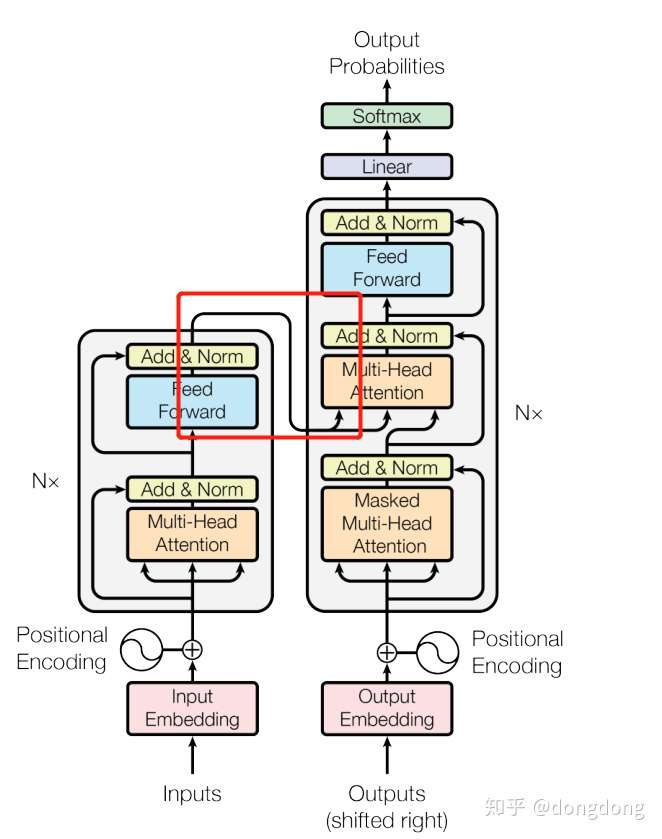
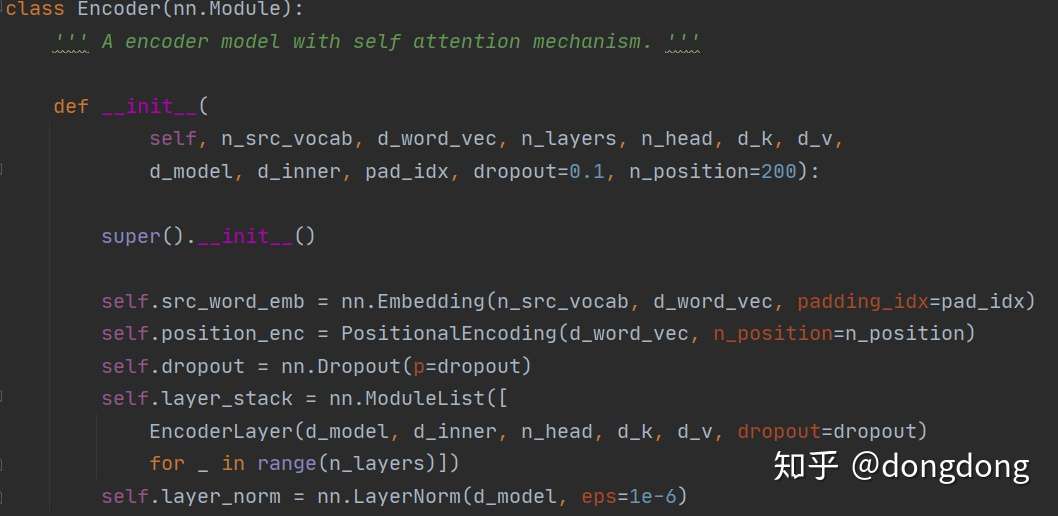
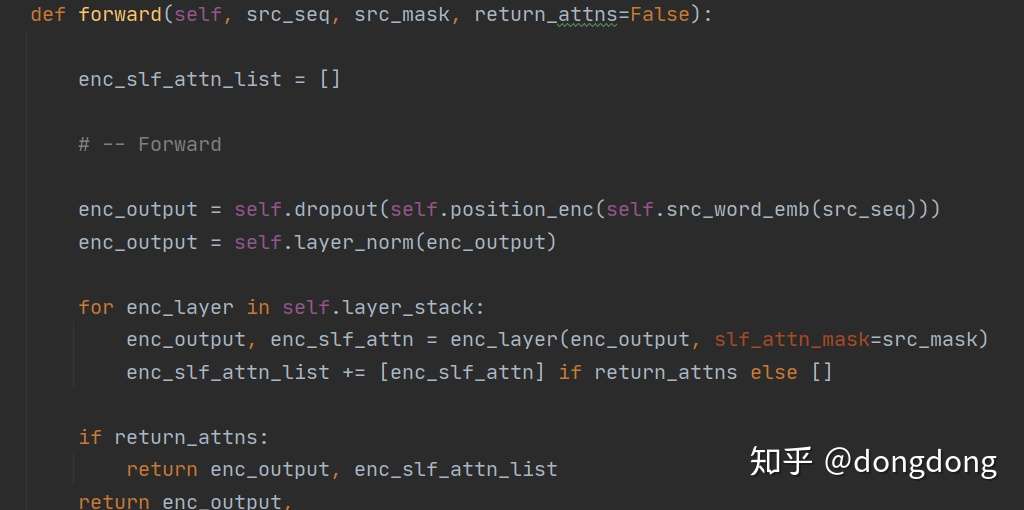
从代码中读到:Encoder 的处理顺序:词嵌入--位置嵌入--dropout层--layer层--各个EncoderLayer层的堆砌。每一层的EncoderLayer输出作为下一层EncoderLayer的输入。
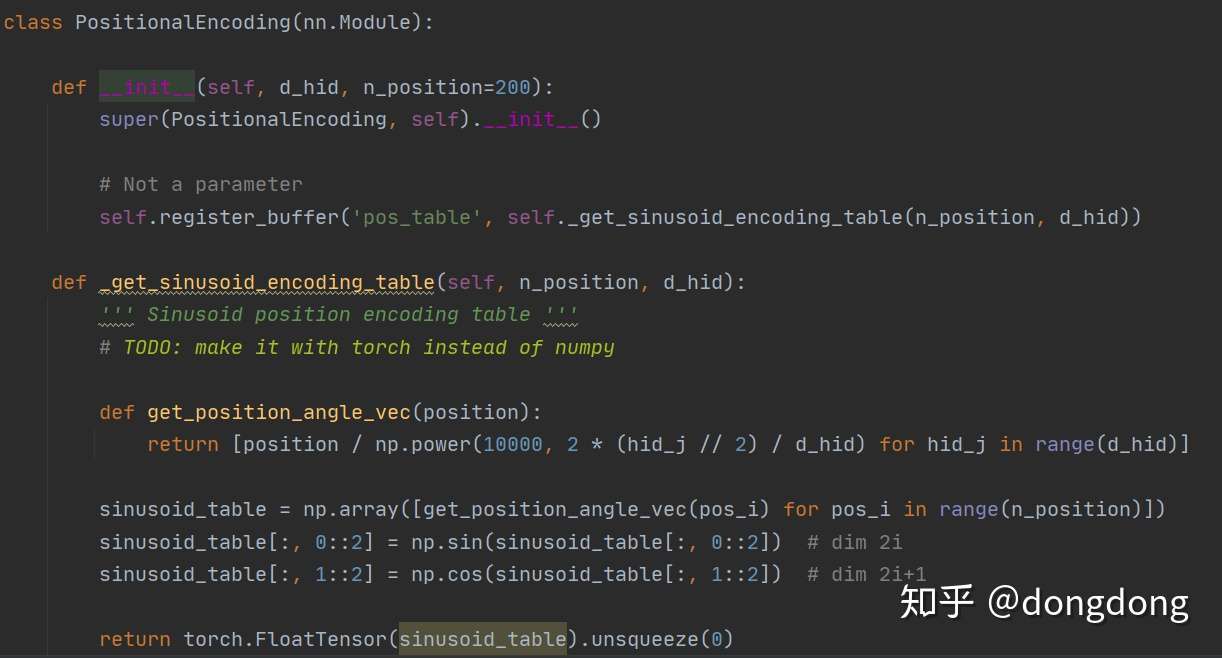 对某个位置的词的词向量使用sin与cos 进行转换
对某个位置的词的词向量使用sin与cos 进行转换
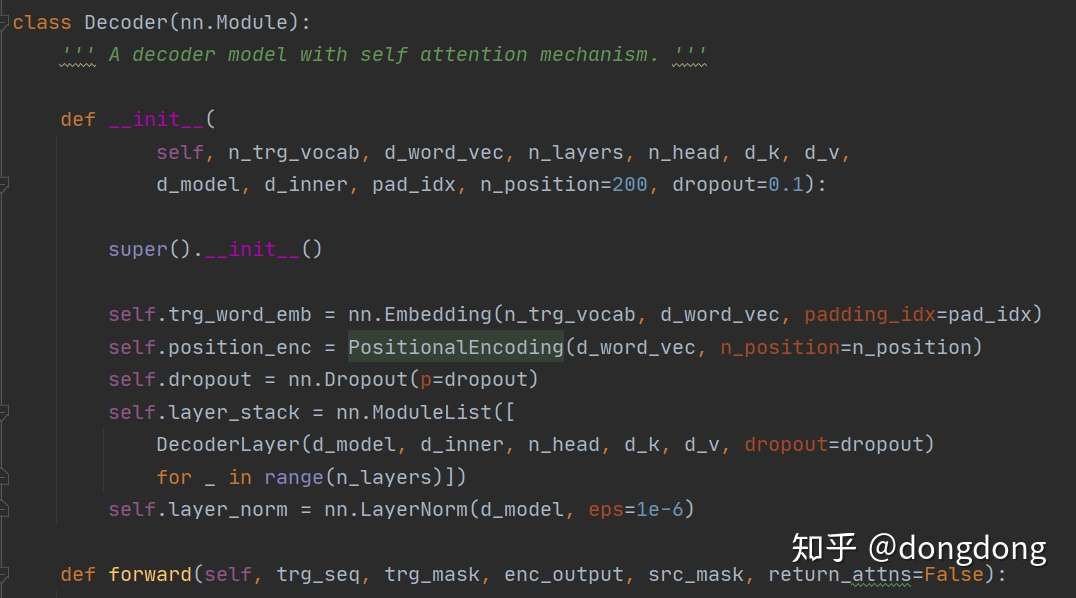
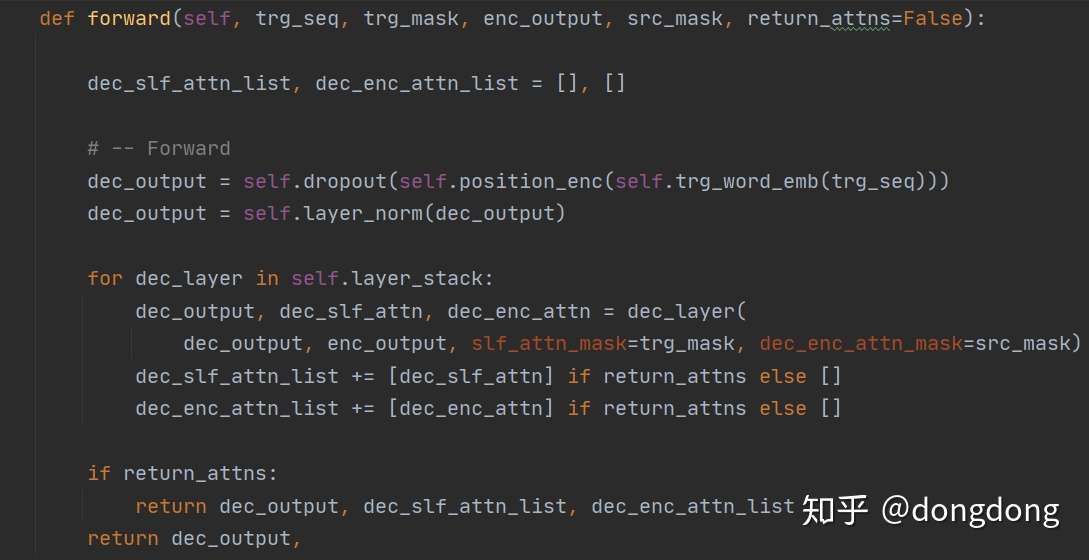
从代码中读到:Decoder 的处理顺序:词嵌入--位置嵌入--dropout层--layer层--各个DecoderLayer层的堆砌。每一层的DecoderLayer输出作为下一层DecoderLayer的输入。
从这里仔细看到传入的enc_output参数一直被调用。也就是Encoder部分最后输出的enc_output多次传入到各个堆砌的Decoder Layer层。
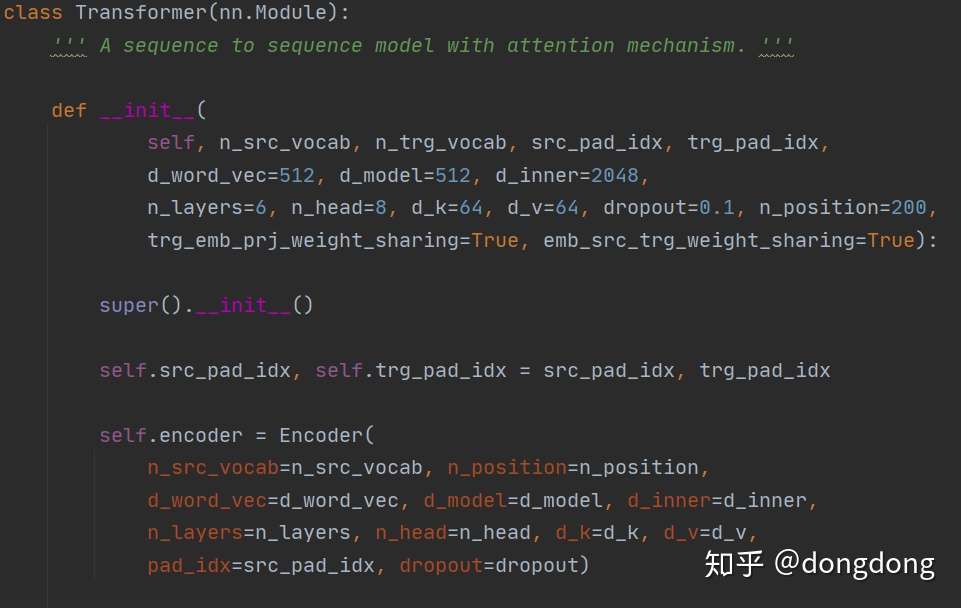
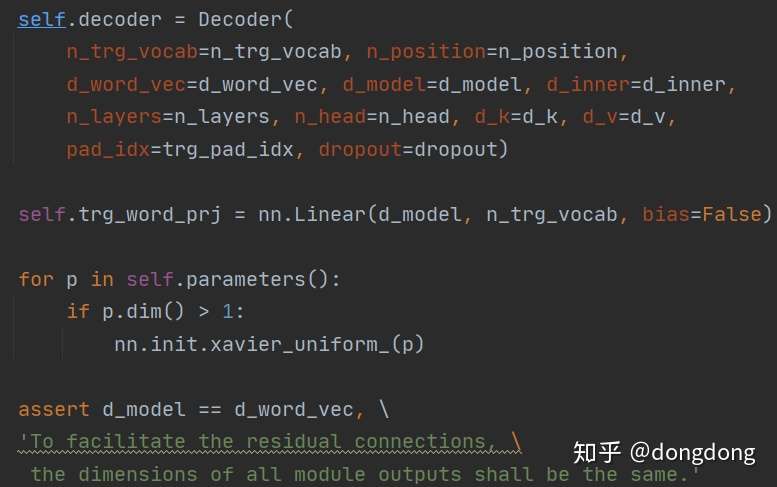
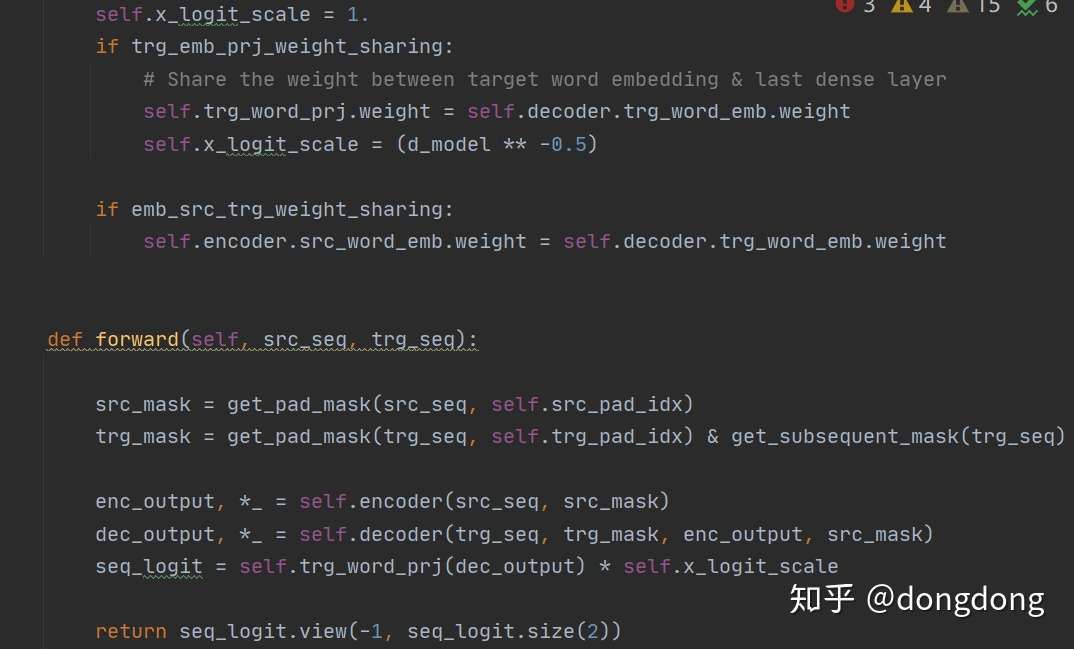
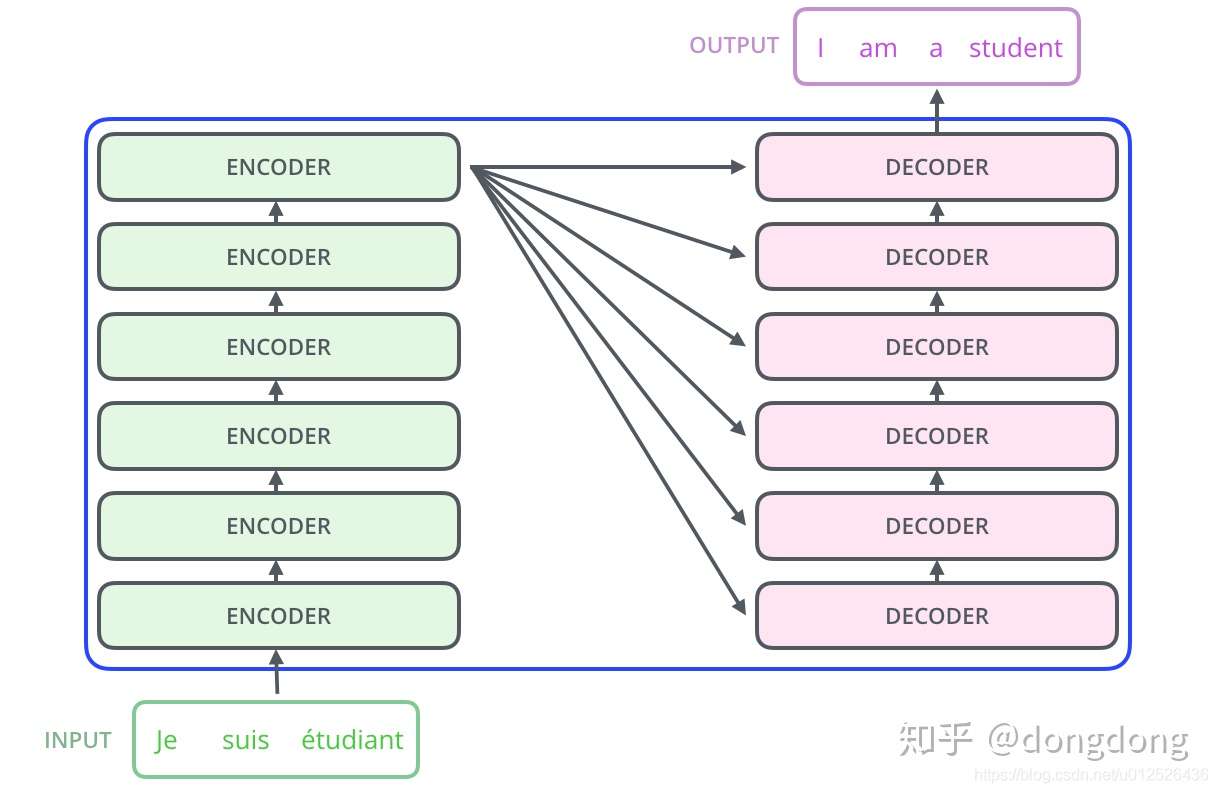
Transfomer结构就是Encoder+Decoder的组合。Encoder可以多层,Decoder可以多层。
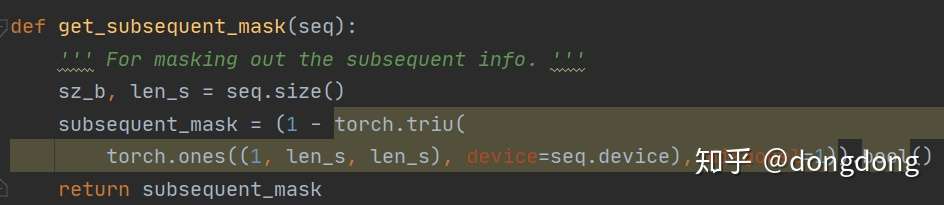
还有一段取主对角线及其以下三角型,且其值为1的代码,则除对角线外,上三角为0,也就是屏蔽上三角。应用于decoder的词嵌入部分

摘要:Transformer是一种经典的基于神经网络的机器翻译模型,催生了BERT、GPT等大幅推进NLP领域发展的重要模型。本文首先对Transformer的发展史进行了简单回顾,然后概括地展示其总体结构,…

原文:https://www.cnblogs.com/cx2016/p/14083717.html
还没有评论