PIE-HYP混合像元分解
遥感图像中混合像元的存在,是像元级遥感分类和要素反演精度难以达到使用要求的主要原因。为了提高遥感应用的精度,必须解决混合像元分解的问题,使遥感应用由像元级达到亚像元级。进入像元内部,将混合像元分解为不同的"基本组分单元",或称"端元",并求得这些基本组分所占的比例(即地物丰度),对混合像元对应地物的真实组成情况进行还原,即所谓的"光谱解混"过程。
同光谱混合模型相对应,光谱解混模型分为两大类:线性光谱解混模型和非线性光谱解混模型。通常情况下,高光谱图像中每个像元都可以近似认为是图像中各个端元的线性混合。线性混合模型一般可分为三种情形:1)为无约束的线性混合模型,2部分约束混合模型,3)全约束混合模型。线性解混就是在已知所有端元的情况下求出每个图像像元中各个端元所占的比例,从而得到反映每个端元在图像中分布情况的比例系数图。线性混合模型适用于本质上就属于或者基本属于线性混合的地物以及在大尺度上可以认为是线性混合的地物。但对于一些微观尺度上地物的精细光谱分析来说,需要非线性混合模型来解释。
线性光谱解混是在高光谱影像分类中针对混合像元经常采用的一种方法,该方法主要分为端元提取和丰度反演两个步骤,第一步是提取"纯"地物的光谱,即端元提取。第二步是用端元的线性组合来表示混合像元,即混合像元分解(丰度反演)。丰度反演主要应用的方法是最小二乘算法。
混合像元分解包括端元数目估计、端元提取和丰度反演三部分。
HySime (Hyperspectral signal identification by minimum error)算法是José M.等人提出的高光谱子空间识别算法。子空间识别步骤可以得到高光谱降维后的有效波段,是目标探测、变化检测、分类和混合像元分类等处理算法的重要的预处理步骤,有助于改善高光谱数据的存储和计算复杂度。HySime算法估计信号和噪声的相关系数矩阵后,在信号特征向量构成的空间中选择使得投影前后具有最小均方差的子空间,构成该子空间的特征向量个数即为端元估计数目。该算法是基于最小均方差的无监督、全自动(不涉及任何需要调整的参数)的特征分解算法
通过PIE-Hyp对演示数据进行端元数目估计操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"端元数目估计"组,单击【HySime端元数目估计】按钮,弹出"HySime端元数目估计"对话框,如下图所示:
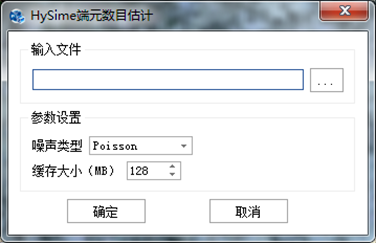
图 1-4-1 HySime端元数目估计菜单
参数设置完成后,点击【确定】按钮,进行端元数目估计处理,输出结果为端元估计的个数。
暂无。
问题1:当计算机内存足够大时,端元数据估计对话框中"缓存大小"是否可以设置很大?
解决办法:可以,但一般不要超过计算机内存的一半。
(1)使用课程提供的数据,进行端元数目估计操作练习。
端元波谱作为高光谱分类、地物识别和混合像元分解等过程中的参考波谱,与监督分类中的分类样本具有类似的作用,直接影响波谱识别与混合像元分解结果的精度。端元提取的作用是从高光谱图像中提取"纯"地物,即端元的光谱。端元提取包括顶点成分分析法、正交子空间投影、内部最大体积法(N-FINDR)。
顶点成分分析(Vertex componment analysis,VCA)算法以线性光谱混合模型的几何学描述为基础,通过反复寻找正交向量并计算图像矩阵在正交向量上的投影距离逐一提取端元。
通过PIE-Hyp对演示数据进行顶点成分分析法操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"端元提取"组,单击【顶点成分分析法】按钮,弹出"顶点成分分析法"对话框,如下图所示:
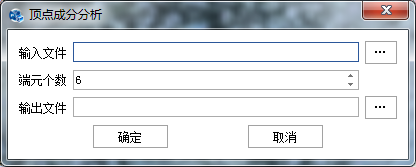
图 2-1-1 顶点成分分析法对话框
参数设置完成后,点击【确定】按钮,进行顶点成分分析处理,输出结果文件为ENVI格式的标准光谱文件(*.sli)。
需要假设前提是:端元一定是单形体的顶点。
问题2:顶点成分分析对话框中"端元个数"如何设置?
解决办法:在对高光谱影像进行顶点成分分析之前,利用端元数目估计功能对影像进行端元个数估计,然后作为输入端元个数的参考。
(1)使用课程提供的数据,进行顶点成分分析操作练习。
正交子空间投影(Orthogonal Subspace Projection, OSP)算法考虑了背景光谱和各种噪声(高斯白噪声、非高斯白噪声和非白噪声等)的情况下最大化剩余信号,提取高光谱影像中的端元光谱。
通过PIE-Hyp对演示数据进行正交子空间投影操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"端元提取"组,单击【正交子空间投影】按钮,弹出"正交子空间投影"对话框,如下图所示:
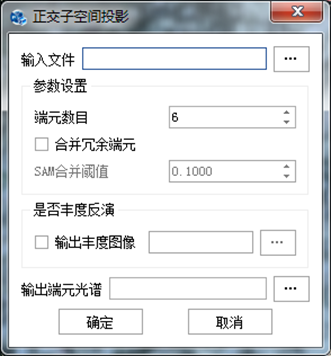
图2-2-1正交子空间投影端元提取功能对话框
所有参数设置完成后,点击【确定】按钮,执行正交子空间投影操作。
暂无。
问题3:正交子空间投影对话框中"端元个数"如何设置?
解决办法:参考顶点成分分析中端元个数设置方法。
问题4:正交子空间投影对话框中"SAM合并阈值"如何设置?
解决办法:SAM合并阈值根据提取端元的个数进行设置,如果提取的端元数比较多,则该值设置的比较小;反之该值设置的比较大。
(1)使用课程提供的数据,进行正交子空间投影操作练习。
内部最大体积法(N-FINDR)算法(Winter,1999)以线性光谱混合模型的几何学描述为基础,利用高光谱数据在特征空间中的凸面单形体的特殊结构,通过寻找具有最大体积的单形体自动获取图像中的所有端元。
通过PIE-Hyp对演示数据进行内部最大体积法操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"端元提取"组,单击【N-FINDR】按钮,弹出"N-FINDR"对话框,如下图所示:
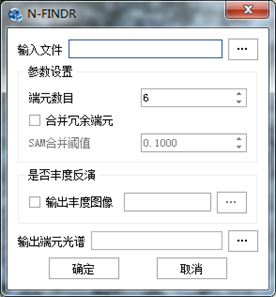
图 2-3-1 N-FINDR端元提取功能对话框
注:SAM合并阈值根据提取端元的个数进行设置,如果提取的端元数比较多,则该值设置的比较小;反之该值设置的比较大。
参数设置完成后,点击【确定】按钮,执行N-FINDR-端元提取操作。
需要先对原始数据进行降维处理,可能会引起偏差("忽视"小目标)。
问题5:内部最大体积法对话框中"端元个数"如何设置?
解决办法:参考顶点成分分析中端元个数设置方法。
问题6:内部最大体积法对话框中"SAM合并阈值"如何设置?
解决办法:参考正交子空间投影中SAM合并阈值设置方法。
(1)使用课程提供的数据,进行内部最大体积法操作练习
丰度反演主要是用于求的混合像元中不同的基本组分单元所占的比例。丰度反演包括最小二乘法、单形体体积、超平面距离和MTMF解混等。
通过PIE-Hyp对演示数据进行最小二乘法操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"丰度反演"组,单击【最小二乘法】按钮,弹出"最小二乘法"对话框,如下图所示:
图 31-1 最小二乘法丰度反演对话框
图 31-2 最小二乘法参数选择对话框
图 31-3 光谱浏览对话框
图 31-4 最小二乘法算法选择对话框
点击【应用】按钮,弹出对应算法的参数设置对话框,在不同约束程度的最小二乘法选项中选择对应的约束条件。
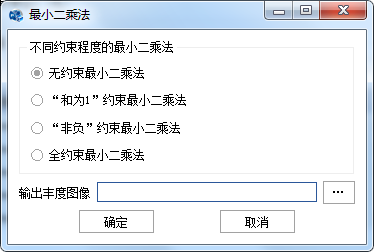
图 31-5 最小二乘法参数选择设置对话框
所有参数设置完成后,点击【确定】按钮,执行最小二乘法丰度反演操作。
暂无。
暂无。
(1)使用课程提供的数据,进行最小二乘法丰度反演操作练习。
根据线性光谱混合模型的代数学描述(不考虑误差)和高光谱数据在特征空间中凸面单形体的特殊结构,端元组成的单形体体积最大。某个端元用其他像元替换后所得单形体的体积比原单形体体积小,因此,可根据替换后单形体与原单形体的体积比计算像元中端元的丰度。单形体体积丰度反演算法功能输入的高光谱影像需为地表反射率数据。
通过PIE-Hyp对演示数据进行单形体体积丰度反演算法操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"丰度反演"组,单击【单形体体积】按钮,弹出"单形体体积"对话框,如下图所示:
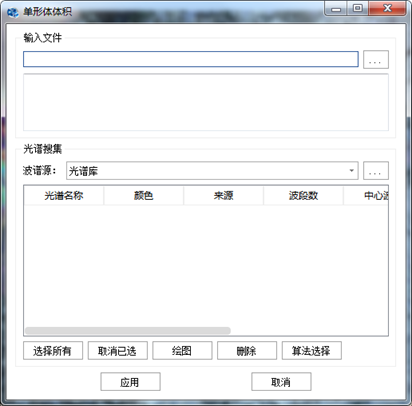
图 32-1 单形体体积参数设置对话框
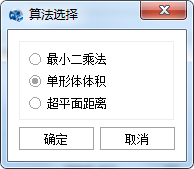
图 32-2 单形体体积法算法选择对话框
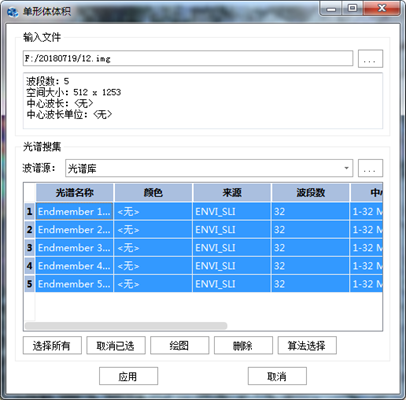
图 32-3 单形体体积法参数选择对话框
点击【应用】按钮,弹出单形体体积输出参数设置对话框。
图 32-4 单形体体积法输出文件对话框
所有参数设置完成后,点击【确定】按钮,执行单形体体积丰度反演操作。
暂无。
暂无。
(1)使用课程提供的数据,进行单形体体积丰度反演操作练习。
根据线性光谱混合模型的几何学描述,混合像元应位于L维特征空间单形体内部,端元应位于单形体顶点,某个端元是距离其他端元构成的L维空间超平面最远的点,因此可以根据像元到超平面的距离与端元到超平面距离的比值计算像元中的端元丰度。
通过PIE-Hyp对演示数据进行超平面距离操作。
序号 | 数据名称 | 数据说明 |
1 | cup99hy.tiff | 待处理的高光谱文件 |
在"混合像元分解"标签下的"丰度反演"组,单击【超平面距离】按钮,弹出"超平面距离"对话框,如下图所示:
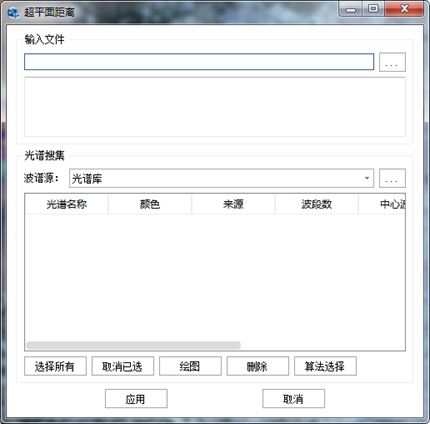
图 33-1 超平面距离参数设置对话框
图 33-2 超平面距离算法选择对话框
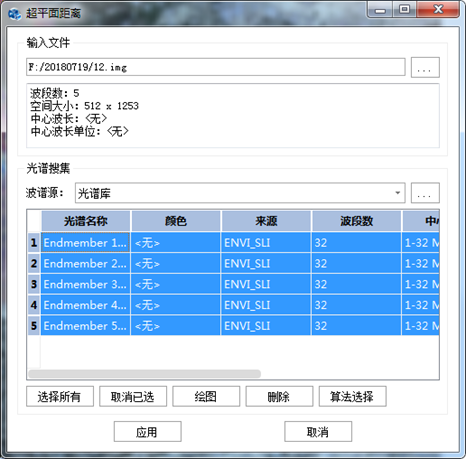
图 33-3 超平面距离参数选择对话框
点击【应用】按钮,弹出单形体体积输出参数设置对话框。
图 33-4 超平面距离输出文件对话框
所有参数设置完成后,点击【确定】按钮,执行超平面距离丰度反演操作。
暂无。
暂无。
(1)线性光谱混合模型有哪些?
(2)简述线性混合像元分解的过程。
(3)使用课程提供的数据,运用不同分类算法进行混合像元分解,掌握不同算法处理出的成果差异。
原文:https://www.cnblogs.com/PIESat/p/14067991.html