异常(exception)是由软件或硬件产生的,分为同步异常和异步异常。同步异常即CPU执行指令期间同步产生的异常,比如常见的除零错误、访问不在RAM中的内存 、MMU 发现当前虚拟地址没有对应的物理地址,于是触发一个异常,系统调用等。异步异常即平时所说的中断(interrupt),外部硬件硬件给 CPU 发送的一种信号,比如说你按下了键盘的某一个按键,键盘控制器于是向 CPU 发送一个中断,通知CPU处理。
外部硬件中断又分为可屏蔽和不可屏蔽中断;可屏蔽中断是可以用以下两个x86_64 -sti和cli指令阻止的中断。Linux内核中源代码如下:
static inline void native_irq_disable(void)
{
asm volatile("cli": : :"memory");
}
static inline void native_irq_enable(void)
{
asm volatile("sti": : :"memory");
}
sti和cli通过修改中断寄存中的IF标志位来达到目的, sti指令设置IF标志,cli指令清除该标志。
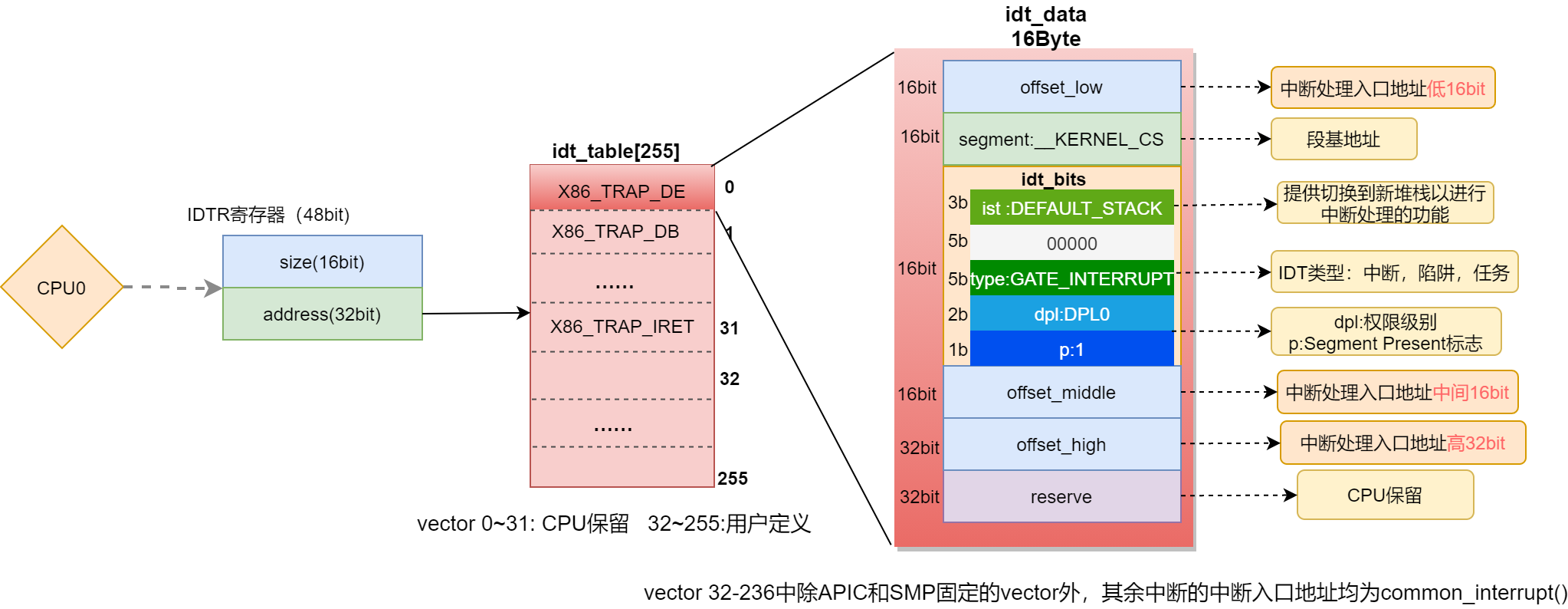
不论是中断还是异常,会每个中断或异常分配一个数来标识,称为vector number,在X86体系中中断向量范围为0-255,最多表示256个异常或中断,如下所示,用一个8位的无符号整数来表示,前32个vector为处理器保留用作异常处理,32 - 255被指定为用户定义的中断,并且不由处理器保留。这些vector通常分配给外部I / O设备,以使这些设备能够向处理器发送中断。
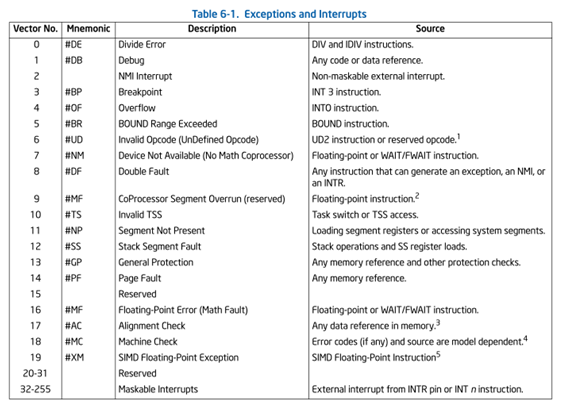
前面说到vector 32 - 255被指定为用户定义的中断,通常分配给外部I/O设备,CPU是如何接受和处理中断的呢?2.2节内容来源于https://github.com/GiantVM/doc/tree/master/interrupt_and_io
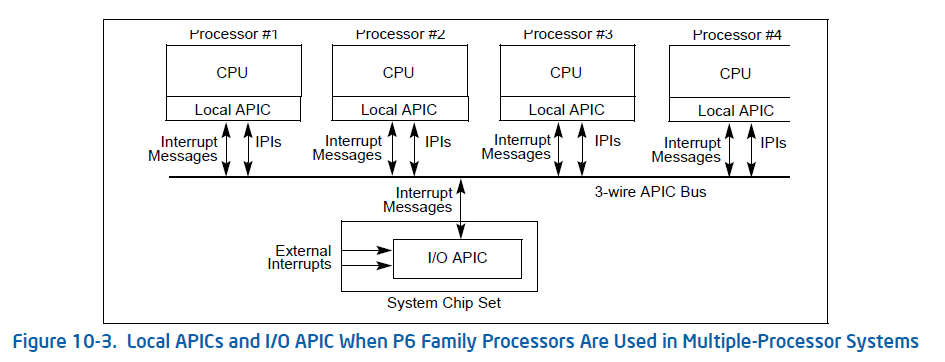
在x86中,当外设向CPU发出中断,中断不会直接发送到CPU,在旧机器中有一个PIC(可编程中断控制器),它是一个芯片(如8259),负责顺序处理来自对各设备的多个中断请求,在现在的新机器中有一个高级可编程中断控制器(APIC),APIC由Local APIC和I/O APIC两部分构成,一般来说,所有 LAPIC 都连接到一个 I/O APIC 上,形成一个一对多的结构(不排除有多 IOAPIC 的架构):
有两种工作模式:
为什么设备中断要经过APIC再与CPU相连,而不直接与CPU相连?原因有二:1)存在大量的外部设备,但CPU的中断引脚等资源是很有限的,满足不了所有的直连需求;2)如果设备中断与CPU直接相连,连接关系随硬件固化,这样在MP系统中,中断负载均衡等需求就无法实现了。
Local APIC是一种负责接收/发送中断的芯片,集成在 CPU 内部,每个 CPU 有一个属于自己的 LAPIC。它们通过 APIC ID 进行区分。
每个 LAPIC 都有自己的一系列寄存器、一个内部时钟(TSC)、一个热传感器、一个本地定时设备(APIC-timer)和 两条 IRQ 线 LINT0 和 LINT1。
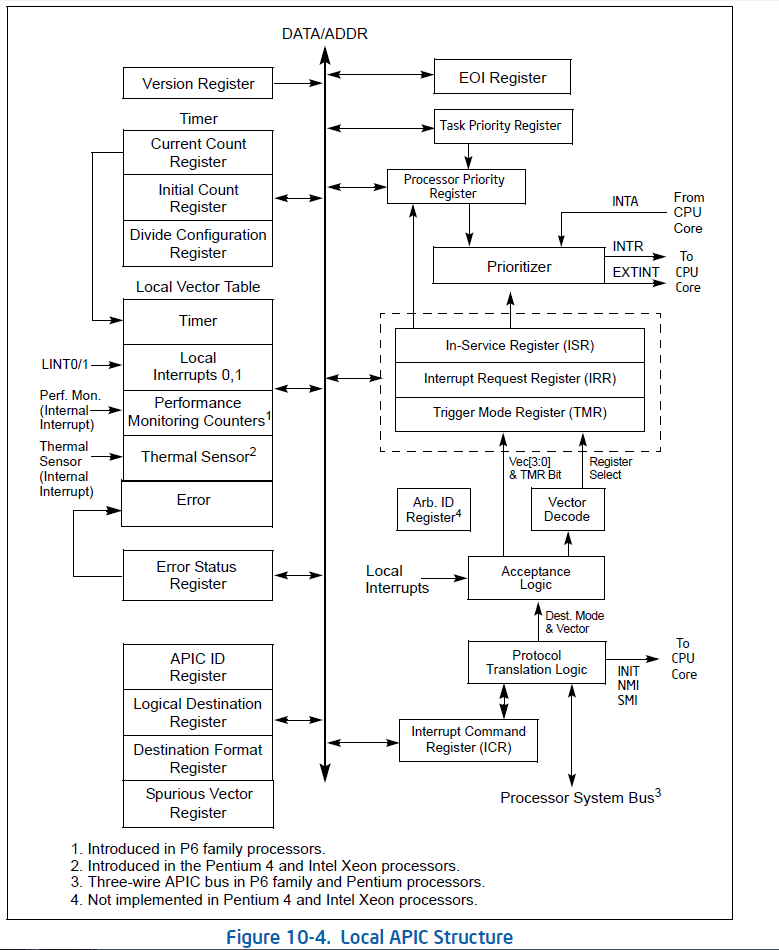
其中常用的寄存器包括:
IRR与ISR两个寄存器,在处理一个vector的同时,缓存一个相同的vector,vector通过2个256-bit的寄存器标识,256个bit代表256个可能的vector,置1表示上报了相应的vector请求处理或者正在处理中。
中断向量的vector的高4位(bit4-7)为Interrupt-Priority class,每个 class 包含 16 个中断向量。0-15 号中断向量的 class 为 0,但其不合法,这些中断永远不会提交。在 Intel 64 和 IA-32 架构中,0-31 号中断向量被保留,因此 class 0-1 不可用。中断向量的 bit0-3 决定了同 class 下的优先级,越大在 class 内的优先级就越高,由于vector 0-31是CPU保留,所以可用中断优先级范围为2-15。
PPR 决定了 CPU 接受的中断。只有 Interrupt-Priority class 大于 Processor-Priority Class 的中断才会被送到 CPU 中(注意, NMI / SMI / INIT / ExtINT / SIPI 不受该限制)。Processor-Priority Sub-Class 不影响中断的送达,只是用来凑数而已。
Local APIC的TPR和PPR用于设置task优先级和CPU优先级,这两个寄存器的值控制着CPU处理该中断行为,当I/O APIC转发的中断vector优先级小于Local APIC TPR设置的值时,此中断不会打断该CPU上运行的task,当I/O APIC转发的中断vector优先级小于Local APIC PPR值时,该CPU不处理该中断,操作系统通过动态设置local APIC TPR和PPR,来实现操作系统的实时性需求和负载均衡。
LAPIC 主要处理以下中断:
其中前 5 种中断被称为本地中断,LAPIC 在收到后会设置好 LVT(Local Vector Table)的相关寄存器,通过 interrupt delivery protocol 送达 CPU。
LVT 实际上是一片连续的地址空间,每 32-bit 一项,作为各个本地中断源的 APIC register :
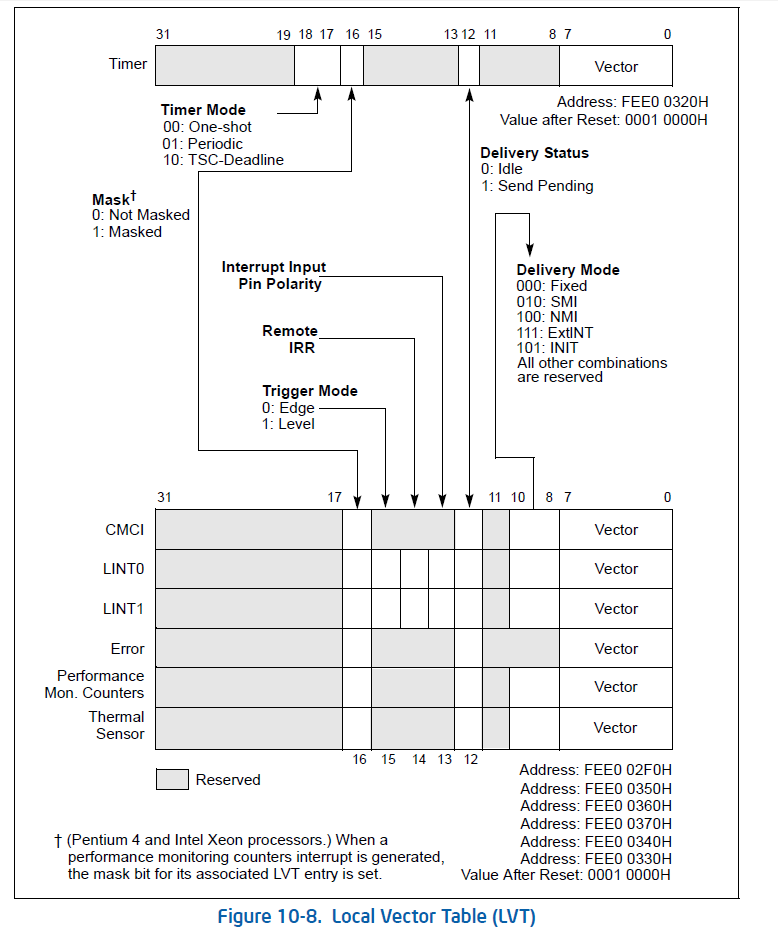
register 被划分成多个部分:
最后两种中断通过写 ICR 来发送。当对 ICR 进行写入时,将产生 interrupt message 并通过 system bus(Pentium 4 / Intel Xeon) 或 APIC bus(Pentium / P6 family) 送达目标 LAPIC 。
当有多个 APIC 向通过 system bus / APIC bus 发送 message 时,需要进行仲裁。每个 LAPIC 会被分配一个仲裁优先级(范围为 0-15),优先级最高的拿到 bus,从而能够发送消息。在消息发送完成后,刚刚发送消息的 LAPIC 的仲裁优先级会被设置为 0,其他的 LAPIC 会加 1。
举个例子:当一个 CPU 想要向其他 CPU 发送中断时,就在自己的 ICR(interrupt command ragister) 中存放对应的中断向量和目标 LAPIC ID 标识。然后由 system bus(Pentium 4 / Intel Xeon) 或 APIC bus(Pentium / P6 family) 直接传递到目标 LAPIC。
一个 LAPIC 在收到一个 interrupt message 后,执行以下流程:
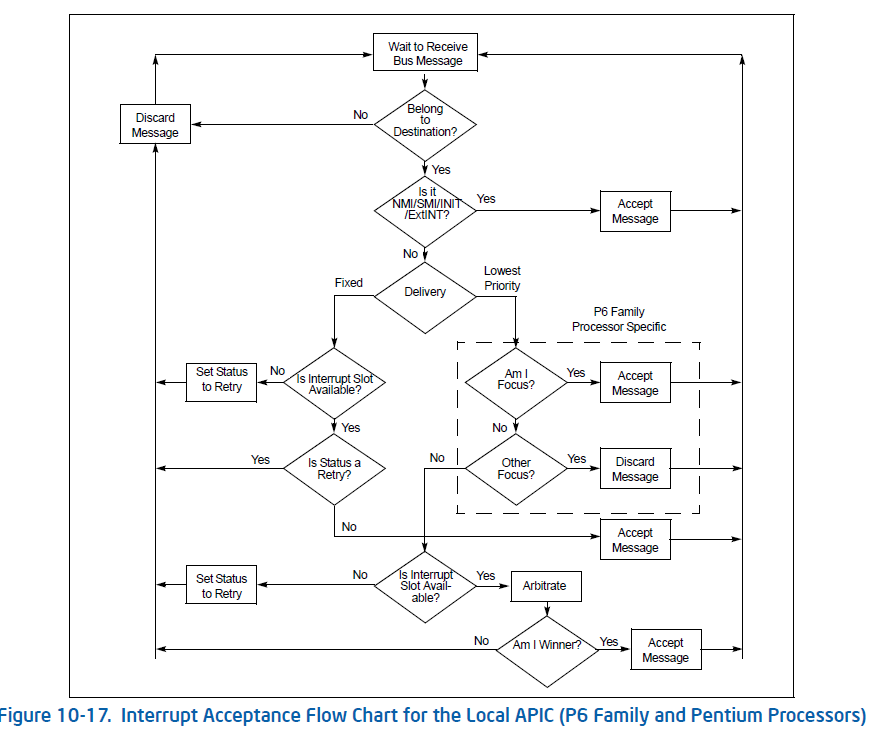
IRR + ISR 的机制决定了同一个中断最多可以 pending 两次,第一次已被送到 CPU 中进行处理,而第二次处于 IRR 中等待送到 CPU 中。
IOAPIC (I/O Advanced Programmable Interrupt Controller) 属于 Intel 芯片组的一部分,也就是说通常位于南桥.
像 PIC 一样,连接各个设备,负责接收外部 IO 设备 (Externally connected I/O devices) 发来的中断,典型的 IOAPIC 有 24 个 input 管脚(INTIN0~INTIN23),没有优先级之分。
I/O APIC提供多处理器中断管理,用于CPU核之间分配外部中断,在某个管脚收到中断后,按一定规则将外部中断处理成中断消息发送到Local APIC。
和 LAPIC 一样,IOAPIC 的寄存器同样是通过映射一片物理地址空间实现的:
取消了 APIC bus,LAPIC 与 IOAPIC 直接通过 system bus 通信。寄存器通过内存映射到物理地址来进行读写。
在 APIC 规范中 APIC ID 只有 4bit ,因此最多只能支持 15 个 CPU。 xAPIC 扩展到 8bit ,支持 255 个。
x2APIC 将 APIC ID 扩展到 32bit ,占 APIC ID Register 的32位,因此支持 \(2^{32}-1\)个 CPU。
寄存器被改为只读,只会在开机时由硬件设置一次,其末8位被作为 xAPIC 模式下的 APIC ID 。
新增了 Self IPI Register ,向该寄存器写入 Interrupt Vector 可实现发送一个 Edge Triggered + Fixed Interrupt 的 Self IPI 。
PCI Specification 2.2 引入,设备通过向某个 MMIO 地址写入 system-specified message 可实现向 CPU 发送中断的效果。
写入的数据仅能用来决定发送给哪个 CPU,而不能携带更多的信息。
具体的实现方式为设备通过 PCI write command 向 Message Address Register 指示的地址写入 Message Data Register 中内容来向 LAPIC 发送中断。
Message Address Register 的格式如下:

Destination ID 字段存放了中断要发往 LAPIC ID。该 ID 也会记录在 I/O APIC Redirection Table 中每个表项的 bit56-63 。Redirection hint indication 指定了 MSI 是否直接送达 CPU。 Destination mode 指定了 Destination ID 字段存放的是逻辑还是物理 APIC ID 。
Message Data Register 的格式如下:
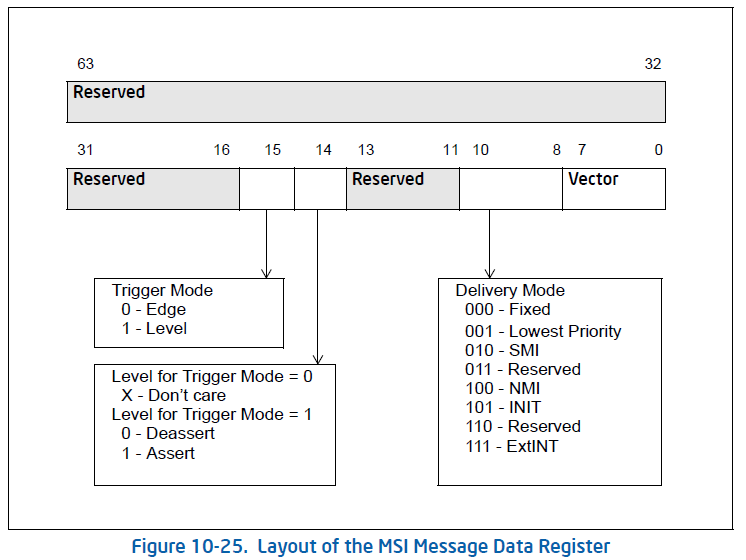
Vector 指定了中断向量号, Delivery Mode 定义同传统中断,表示中断类型。Trigger Mode 为触发模式,0 为边缘触发,1 为水平触发。 Level 指定了水平触发中断时处于的电位(边缘触发无须设置该字段)。
允许设备分配 1/2/4/8/16/32 个中断。
传统中断基于的引脚 (pin) 往往被多个设备所共享。中断触发后,OS 需要调用对应的中断处理例程来确定产生中断的设备,耗时较长。而 MSI 中断只属于一个特定的设备,不存在该问题。
传统中断通常是设备写完数据 (DMA) 后,给 CPU 一个中断请求,通知 CPU 进行处理。但是可能由于某些原因(优化?),PCI bridge 或 Memory controller 可能会延迟写数据操作,导致 CPU 在收到中断时,数据还未到达内存。为了解决这个问题,interrupt handlers 必须从通过轮询来确保写操作已经完成,具体操作是访问一个寄存器,只有数据到达内存后,寄存器才会返回值(PCI 事务保证),这样导致性能不好。而 MSI 的中断本质上也是写内存,这样就保证了写内存后发中断这样的流程是串行的,因而避免了轮询的问题。
传统中断先发送到 IOAPIC 后再转发给对应的 LAPIC ,路径较长。MSI 能让设备直接将中断送达 LAPIC 。
无法保证 Interrupt Latency,MSG 可能会被 Host/Loading Cache 这样就可能会出现 Latency,另外当 Loading 重的时候也可能会出现比较大的 Latency。
PCI 3.0 引入。最多允许设备分配 2048 个中断,给每个中断都分配一个不同的目标地址和 data word,比 MSI 粒度更细(需要 LAPIC 的支持)。
异常/中断的发生和捕捉,是在硬件层面完成的,异常的处理还需要软件来完成。在计算机的内存里,会保存一个表,这个表叫作中断描述符表(Interrupt Descriptor Table或IDT),每个异常的处理程序的地址入口作为一项保存在该表里,称为gates。
CPU使用特殊寄存器IDTR来保存中断描述符表的位置,可以使用lidt指令将IDT的基地址保存到IDTR,IDTR是一个48bit的寄存器,存放了 IDT 的起始地址和长度。IDTR寄存器结构如下:
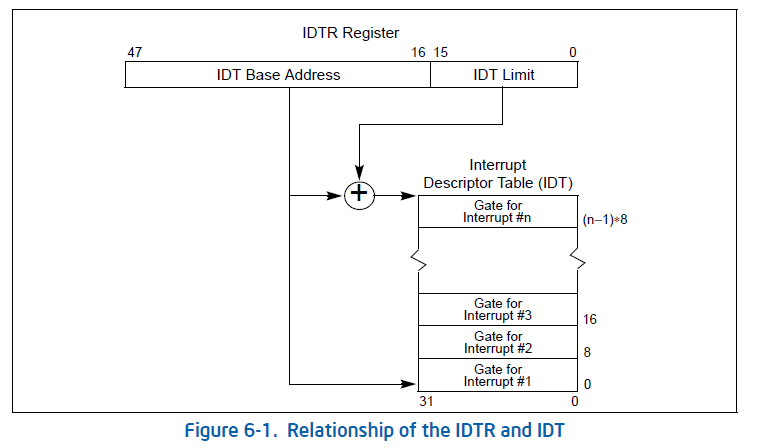
当异常产生和捕捉后,CPU会拿到表示该异常的异常向量(vector),接下来会先保存当前程序的执行现场,保存到程序堆栈里面,然后从 IDTR 拿到IDT表的 base address,加上向量号 * IDT entry size,即可以定位到对应的表项(IDT gate)。
下面来看IDT具体内容。
32 bit IDT

32bit处理与64bit类似就不细说,直接看64Bit
64 bit IDT
在64位x86下IDT用16字节描述。

IDT图包含如下字段:
0-15 bits - 从segment select的偏移,处理器使用该段选择器作为中断处理程序入口点的基址;
16-31 bits - segment select的基地址,包含中断处理程序的入口点;
IST - x86_64提供切换到新堆栈以进行中断处理的功能。
32位与64位对比,可以发现 byte 4-7 的 bit 0-4 由 reserved 变成了 IST(Interrupt Stack Table),而 offset 在 64 位下需要扩展为 64 bit,因此 byte 8-11 将保存 offset 的 bit 32-63 。
IST 是 64 位引入的新的栈切换机制。在收到中断 / 异常时,如果中断对应的 IDT 表项中 IST 字段非 0,则硬件会自动切换到对应的中断栈(中断栈的指针存放在 TSS 中,被加载到 rsp)。IST 最多有 7 项,它们指向的中断栈的大小都可以不同。目前实现的栈有:
Type - IDT条目类型:GATE_INTERRUPT,GATE_TRAP、GATE_CALL、GATE_TASK
DPL - 描述符的权限级别0最高
P - Segment Present标志
Segment Present GDT或LDT代码段选择子
48-63 bits - 处理程序基址的第二部分
64-95 bits - 处理程序基址的第三部分
96-127 bits - 由CPU保留
当CPU收到一个中断/异常后,CPU 执行以下流程:
如果要以较低的数字特权级别执行处理程序过程,则会发生堆栈切换。从当前执行任务的TSS获得处理程序要使用的堆栈的段选择器和堆栈指针,加载 tss.esp0 到 esp 中, tss.ss0 到 ss 中,从而切换到内核栈。
如果要以与被中断过程相同的特权级别执行处理程序,则不需要切换堆栈。
在 32 位下,会根据有没有特权级切换决定是否压 ss 和 sp:
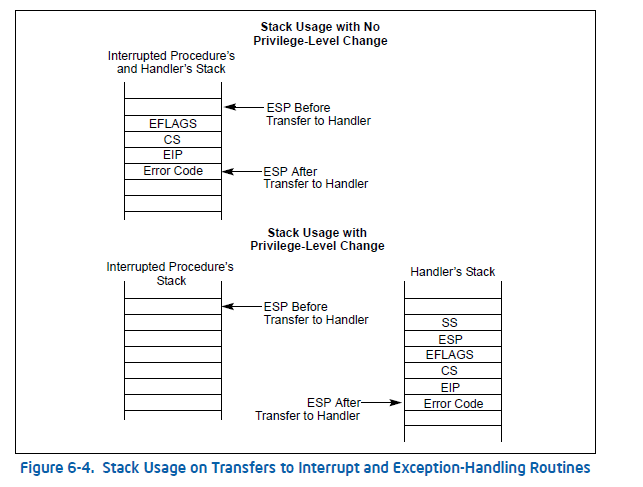
在 64 位下无论如何都会压。这样一来,保证了所有中断和异常的栈帧(stackframe)都是一样大的。在 iret 时也不必进行区分,都弹出相同数量的寄存器值。
error code 用于向 handler 传递相关信息(并不是所有异常都有error code )。比如对于 page fault handler 来说,产生 page fault的原因有几个,需要让handler区别处理,page fault error code 定义如下:
注意的是,为了防止中断重入,interrupt gate 在执行时会清掉 eflags 寄存器的 IF bit,而 trap gate 不会这样做。
要从异常或中断处理程序过程返回,处理程序必须使用IRET(或IRETD)指令。
IRET指令与RET指令相似,不同之处在于它将已保存的标志恢复到EFLAGS寄存器中。 仅当CPL为0时,才恢复EFLAGS寄存器的IOPL字段。仅当CPL小于或等于IOPL时,才更改IF标志。 请参阅英特尔?64和IA 32架构的第3章“指令集参考,A-L”软件开发人员手册,第2A卷,介绍了IRET指令执行的完整操作。
如果在调用处理程序过程时发生了堆栈切换,则IRET指令将在返回时切换回被中断过程的堆栈。
英特尔? 64 位和 IA-32 架构软件开发人员手册第 3 卷 :系统编程指南
原文:https://www.cnblogs.com/wsg1100/p/14055863.html