基于图像的序列识别是计算机视觉领域长期以来的研究课题。本文研究了场景文本识别问题,这是基于图像的序列识别中最重要和最具挑战性的任务之一。提出了一种集特征提取、序列建模和转录为一体的神经网络体系结构。与以往的场景文本识别系统相比,本文提出的架构具有四个独特的特点:
小结:算法在 III-5K、ICDAR、街景文字数据集上做了baseline的训练,其表现优于现有技术(2015年),在迁移性方面,在乐谱识别方面表现良好,明显验证了该算法的通用性。
本文的主要贡献是提出了一种新的神经网络模型,该模型的网络结构是专门为识别图像中的序列类目标而设计的。由于该神经网络是DCNN和RNN的结合,因此将该神经网络模型命名为卷积递归神经网络(CRNN)。对于类序列对象,CRNN与传统的神经网络模型相比,有几个明显的优势:
作者的track
一个端到端的模型,主要由CNN、RNN、CTC模型组合得到。
模型架构图如图所示:
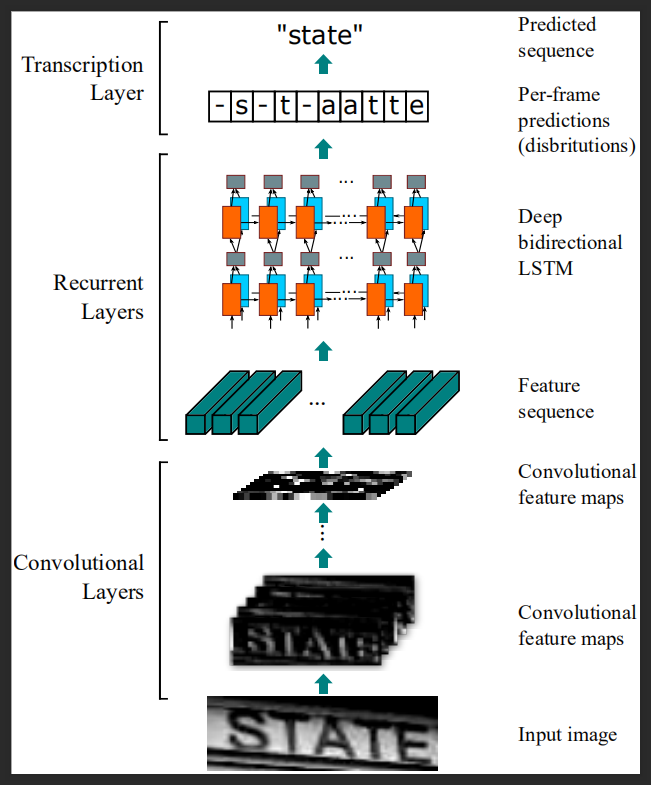
CNN架构负责从自然场景图片中识别到单词区域,即目标检测的候选区域;RNN负责将候选区域的特征图序列化结构做递归神经网络预测,这里可以理解为从特征图到字符编码,如这里的-s-taatte;经过 transcription layer 实现单词的预测。
在CRNN模型中,卷积层的组成部分是通过使用标准CNN模型中的卷积层和最大池层(去掉全连接层)来构建的。该组件用于从输入图像中提取连续的特征表示。在输入网络之前,所有的图像都需要缩放到相同的高度。然后从卷积层组件生成的特征图中提取出一系列的特征向量,卷积层组件是循环层的输入。具体来说,特征序列的每个特征向量在特征图上按列从左到右生成。这意味着第i个特征向量是所有映射的第i列的串联(平铺)。在我们的设置中,每一列的宽度固定为单个像素。
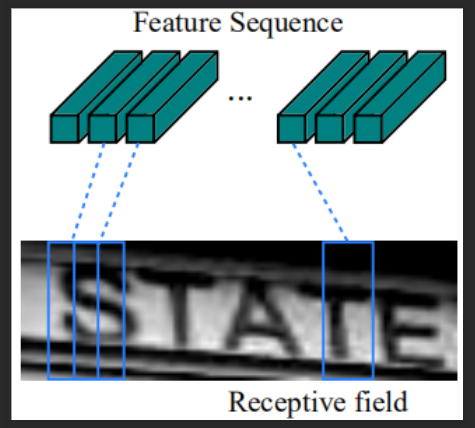
如图所示:Fearture Sequence的每一个特征向量,是下方特征图所有通道的第\(i\)列平铺后的特征向量.
作者使用了双向递归神经网络模型,额,就是LSTM。
主要的特点:
双向RNN结构有利于获取上下文信息,使用多层LSTM结构有利于获取高级语义,在NLP领域有很好的性能提升,所以作者这里使用了多层LSTM结构叠加。
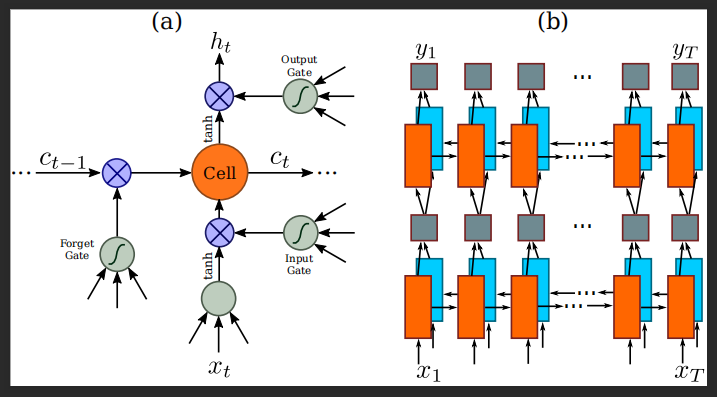
? a. 基本LSTM单元的结构。LSTM由一个单元模块和三个门组成,即输入门、输出门和遗忘门。
? b. 本文采用的深度双向LSTM结构。将正向LSTM(从左到右)和反向LSTM(从右到左)结合在一起就形成了双向LSTM。多层双向LSTM叠加后形成深双向LSTM。
这里两个层级之间有一个Map-to-Sequence layer进行连接。
转录是RNN将每帧预测转换为标签序列的过程。从数学上讲,转录是在每帧预测的条件下找到概率最高的标签序列。在实践中,存在着两种转录方式,即无词典转录和基于词典转录。词典是一组被预测限制的标签序列,例如拼写检查词典。在无词汇模式下,预测不需要任何词汇。在基于词典的模式中,通过选择概率最大的标签序列来进行预测。
额:说那么多,实际这部分就是语言模型。不管你是磕磕巴巴“说”出来的单词,语言模型都会给出最可靠的结果。
这里作者选用了CTC模型进行RNN输出标签的处理。CTC模型在场景文字识别领域可以算是一个baseline的技术点。
定义
\(l\) 为模型预测的label,这里即为字符,\(\textbf{L}\)为序列,即输出向量labels;
\(y_{t}\) 为RNN模型预测的输出,CTC模型的输入, \(\textbf{Y}\)为CTC输入的序列;
CTC算法即为:\(\underset{\textbf{Y}}{argmax} P\left ( \textbf{L}|\textbf{Y}\right )\)
目标函数:\(-logP\left ( \textbf{L}|\textbf{Y}\right )\)
? 目标函数为条件概率的负对数似然函数。额,说白了就是统计里面的条件概率--->对数似然--->求解参数。
| CTC算法 |
|---|
| 输入:\(\textbf{Y}=y_{1},\cdots ,y_{T}\),T为输入的序列长度 其中$y_{t}\in \Re ^{\left |
| 重要公式: $p\left ( \Pi |
上面的表格总的来说讲了一件事,就是求条件概率或者后验期望。在深度学习模型中怎么求,这里作者采用了近似解:
? \(L^{*}\approx B\left ( \underset{\Pi}{argmax}\ p\left ( \Pi|Y \right ) \right )\)
备注
Lexicon-free transcription 独立转换
? 作者这里使用了\(\Pi\)各个元素之间相互独立,即\(y_{t}\)之间相互独立,\([-, -, h,h,-,e,l,-,l,l,-,o,o,-,-]\)之间相互独立。基于两两独立假设,每一个\(y_{t}\)只需要求解最可能的“字符”,这样模型变得很简单了。但是这两个序列明显不独立啊,而且序列内部是有相关性的,这个相关性主要是语言模型造成的。那么这种相关性很强吗?实际上从特征工程上讲,这种相关性不是强相关,这里我无法给出严格的数学证明,我们可以从语言模型本身出发理解,在一个语言模型下,某单词字符序列我们假设其为强相关的,那么当字符可重复时,这种相关性就大打折扣了,如果再加空白符,那么它还能强相关吗?所以作者使用独立性假设,取得了很好的效果,说明这种相关性是很弱的,如果是强相关,这里训练的模型一定会识别性能很差。
? 若哪一天可以解决这种弱相关,那时我们一定处于强人工智能时代。
Lexicon-based transcription 基于字典的转换
? 作者在这部分告诉我们,假设我们考虑每个字符(最终的输出字符)的相关性,即我们不考虑中间过程,那么我们要对每一个序列考虑排列组合的情况,感觉要了老命了,如字符有60个,假设现在最终的序列长为10,那我们要考虑\(60^{10}\),这可不是一个小数目,再加上复杂的数学计算,额,裂开了。这种情况我们时间是还是在对齐的状态说的,而输入、输出序列本身就不能对齐,这是真的太难了;另一方面我们要考虑的对象是单词而不是字符,所以实际远大于60,如论文中给出的是5000个词。
? 在这个时候,论文给出了一种近似算法。
? \(L^{*}\approx B\left ( \underset{L\in \delta \left ( {L}‘ \right ) }{argmax}\ p\left ( L|Y \right ) \right )\),其中\({L}‘\)是中从\(\textbf{Y}\)转换后的中间状态,如\([-, -, h,h,-,e,l,-,l,l,-,o,o,-,-]\)。\(\delta \left ( {L}‘ \right )\)是中间状态的最大编辑距离的邻域,主要这里的最大编辑距离是一个超参数,你得提前定啊!
? 那么怎么搜索邻域内的单词呢?嗯,作者这里提出了BK-tree,这个算法是编辑距离里面做拼写检查的,这个知识点已经忘了,点点链接了解一下吧!
? 作者还提到他在测试中使用了 Hunspell spell-checking dictionary。
训练数据集:Synth 论文:Synthetic data and artifificial neural networks for natural scene text recognition
该数据集包含800万张训练图像及其对应的ground truth词。这样的图像是由合成文本引擎生成的,非常逼真。我们的网络在合成数据上训练一次,并在所有其他真实世界的测试数据集上测试,没有任何微调他们的训练数据。尽管CRNN模型是纯合成文本数据训练的,但它在标准文本识别基准的真实图像上工作得很好。
测试数据集:ICDAR 2003、 ICDAR 2013、 IIIT 5k-word、Street View Text。
模型架构
| Type | Confifigurations |
|---|---|
| Transcription | - |
| Bidirectional-LSTM | #hidden units:256 |
| Bidirectional-LSTM | #hidden units:256 |
| Map-to-Sequence | - |
| Convolution | #maps:512, k:2 × 2, s:1, p:0 |
| MaxPooling | Window:1 × 2, s:2 |
| BatchNormalization | - |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| BatchNormalization | - |
| Convolution | #maps:512, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:1 × 2, s:2 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| Convolution | #maps:256, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:128, k:3 × 3, s:1, p:1 |
| MaxPooling | Window:2 × 2, s:2 |
| Convolution | #maps:64, k:3 × 3, s:1, p:1 |
| Input | W × 32 gray-scale image |
采用了1x2的MaxPooling使得方框扁平化,因为我们的文字是长序列;
normalization在模型训练中有很好的效果;
DCNN网络被提出之后,很多学者用这种架构的网络来提取字符,这种方法通常需要训练一个强大的字符检测器,以便准确地检测和裁剪出原始单词图像中的每个字符;另一种方法将场景文本识别作为一个图像分类问题,为每个英语单词(总计90K单词)分配一个类标签。这是一个庞大的训练模型,类的数量庞大,很难推广到其他类序列对象,如中文文本、乐谱等,因为此类序列的基本组合数量可能超过100万个。综上所述,目前基于DCNN的系统还不能直接用于基于图像的序列识别。
小结:这里我们注意到,识别每一个单词或者字符,假设算法可以\(100\%\)的识别正确字符、单词。但是在自然场景的序列化上面,我们会遇到组合爆炸的情况!
递归神经网络(RNN)模型是深度神经网络家族的另一个重要分支,主要用于处理序列。
RNN的优点之一是在训练和测试中都不需要序列目标图像中每个元素的位置。但是在我们的任务场景中,需要需处理图片的特征图到序列化特征。
预处理步骤独立于流水线中的后续组件,因此现有的基于RNN的系统不能以端到端的方式进行训练和优化。
原文:https://www.cnblogs.com/dan-baishucaizi/p/13992809.html