ETL基本上就是数据采集的代表,包括数据的提取(Extract)、转换(Transform)和加载(Load)。数据源是整个大数据平台的上游,数据采集是数据源与数仓之间的管道。在采集过程中针对业务场景对数据进行治理,完成数据清洗工作。
在大数据场景下,数据源复杂、多样,包括业务数据库、日志数据、图片、视频等多媒体数据等。数据采集形式也需要更加复杂,多样,包括定时、实时、增量、全量等。常见的数据采集工具也多种多样,可以满足多种业务需求。
一个典型的数据加载架构: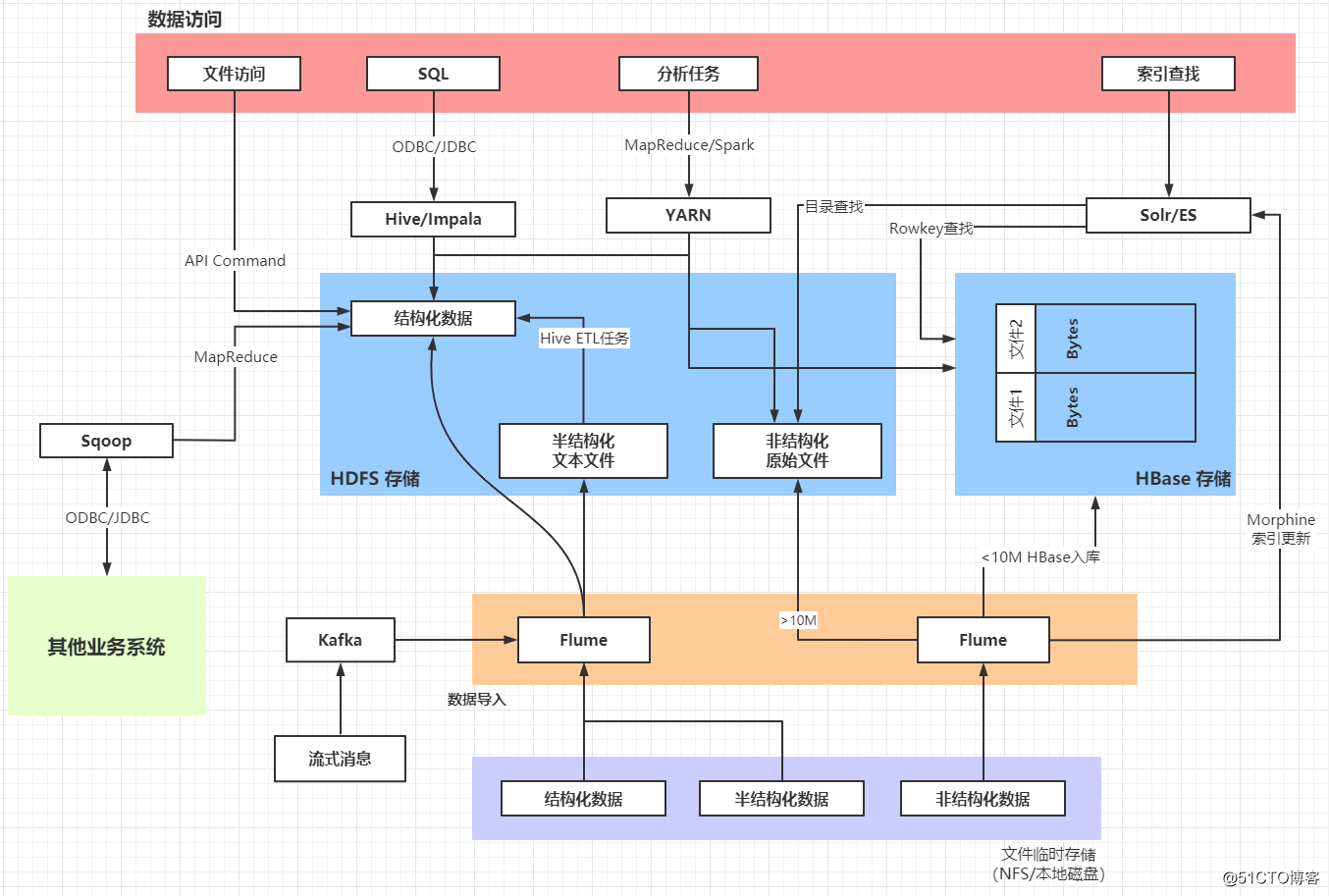
常见的三个数据采集场景:
数据采集系统需求:
Sqoop是常用的关系数据库与HDFS之间的数据导入导出工具,将导入或导出命令翻译成MapReduce程序来实现。所以常用于在Hadoop和传统的数据库(Mysq|、Postgresq|等)进行数据的传递。
可以通过Hadoop的MapReduce把数据从关系型数据库中导入到Hadoop集群。使用Sqoop传输大量结构化或半结构化数据的过程是完全自动化的。
Sqoop数据传输示意图: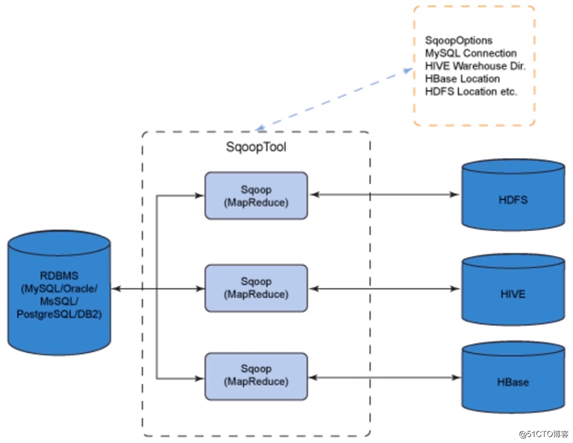
Sqoop Import流程: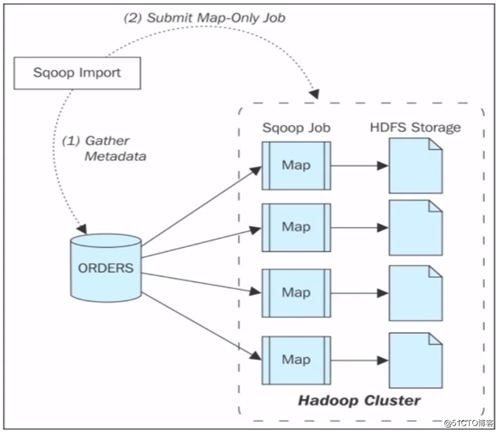
**Sqoop Export流程:***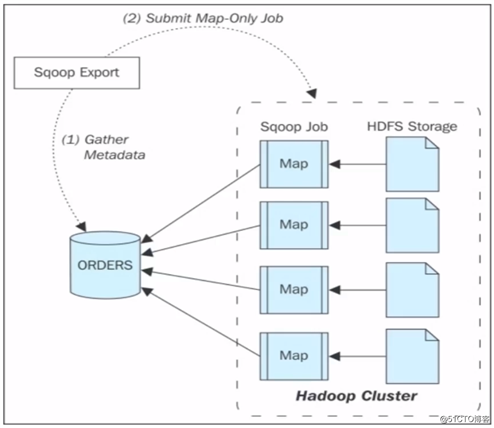
Apache Flume本质上是一个分布式、可靠的、高可用的日志收集系统,支持多种数据来源,配置灵活。Flume可以对海量日志进行采集,聚合和传输。
Flume系统分为三个组件,分别是Source(负责数据源的读取),Sink(负责数据的输出),Channel(作为数据的暂存通道),这三个组件将构成一个Agent。Flume允许用户构建一个复杂的数据流,比如数据流经多个Agent最终落地。
Flume数据传输示意图: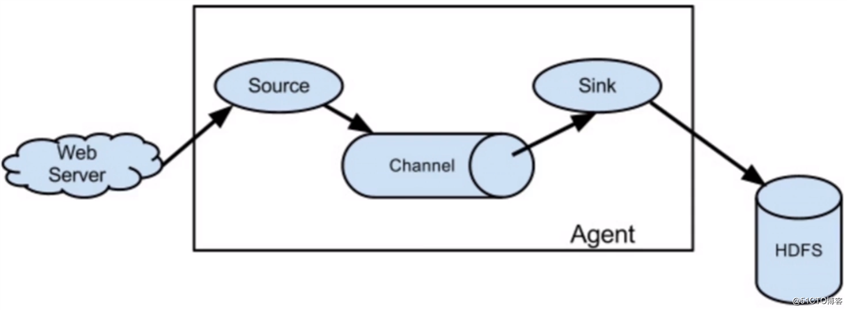
Flume多数据源多Agent下的数据传输示意图: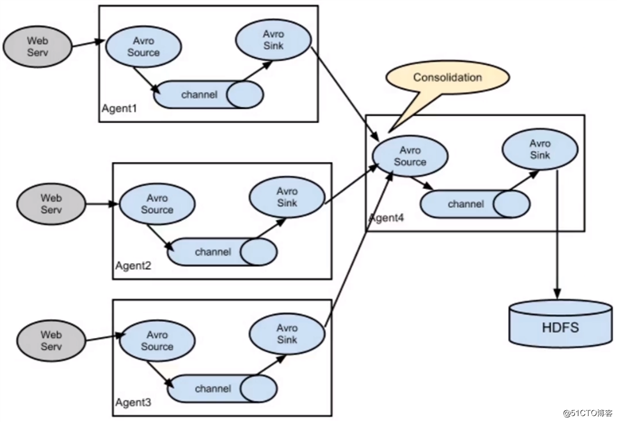
Flume多Sink多Agent下的数据传输示意图: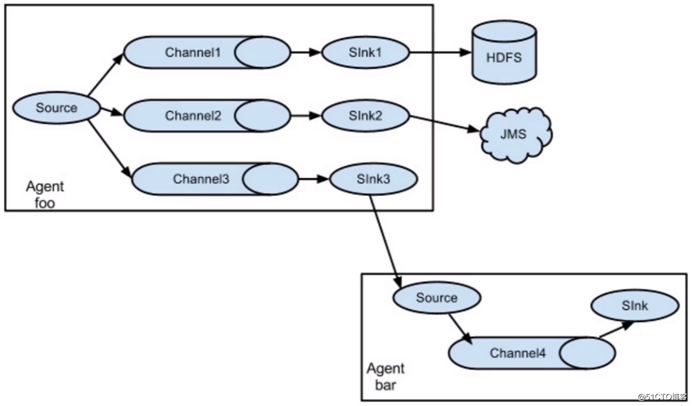
关于Flume的实操内容可以参考:
官方文档:
DataX是阿里开源的异构数据源离线同步工具,致力于实现关系数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、 HBase、 FTP等各种异构数据源之间高效稳定的数据同步功能。DataX将复杂的网状的同步链路变成了星型数据同步链路,具有良好的扩展性。
网状同步链路和DataX星型数据同步链路的对比图: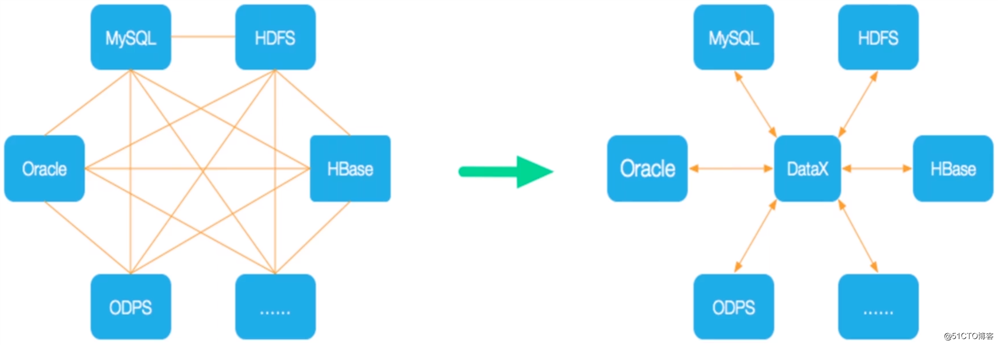
DataX的架构示意图: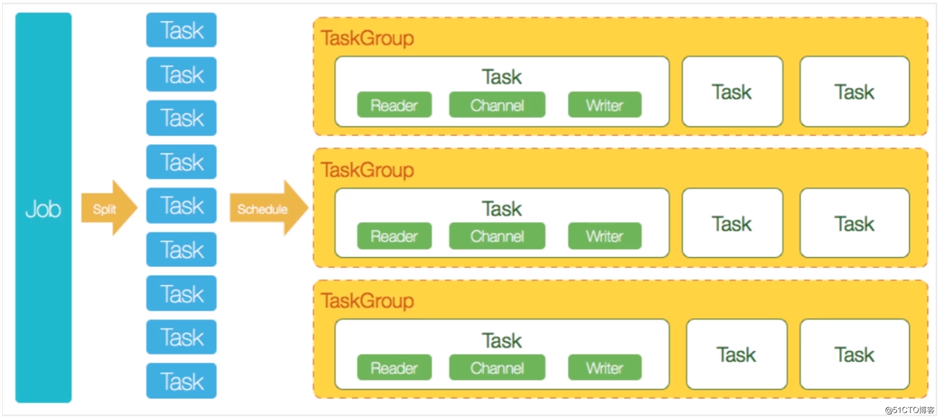
官方文档:
到GitHub上的下载地址下载DataX,或者拉取源码进行编译:
将下载好的安装包,上传到服务器:
[root@hadoop ~]# cd /usr/local/src
[root@hadoop /usr/local/src]# ls |grep datax.tar.gz
datax.tar.gz
[root@hadoop /usr/local/src]# 将安装包解压到合适的目录下:
[root@hadoop /usr/local/src]# tar -zxvf datax.tar.gz -C /usr/local
[root@hadoop /usr/local/src]# cd ../datax/
[root@hadoop /usr/local/datax]# ls
bin conf job lib plugin script tmp
[root@hadoop /usr/local/datax]# 执行DataX的自检脚本:
[root@hadoop /usr/local/datax]# python bin/datax.py job/job.json
...
任务启动时刻 : 2020-11-13 11:21:01
任务结束时刻 : 2020-11-13 11:21:11
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0检测没问题后,接下来简单演示一下将CSV文件中的数据导入到Hive中。我们需要用到hdfswriter,以及txtfilereader。官方文档:
首先,到Hive中创建一个数据库:
0: jdbc:hive2://localhost:10000> create database db01;
No rows affected (0.315 seconds)
0: jdbc:hive2://localhost:10000> use db01;然后创建一张表:
create table log_dev2(
id int,
name string,
create_time int,
creator string,
info string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘
stored as orcfile;当库、表创建完成后,在HDFS中会有对应的目录文件:
[root@hadoop ~]# hdfs dfs -ls /user/hive/warehouse/db01.db
Found 1 items
drwxr-xr-x - root supergroup 0 2020-11-13 11:30 /user/hive/warehouse/db01.db/log_dev2
[root@hadoop ~]# 准备测试数据:
[root@hadoop ~]# cat datax/db.csv
1,创建用户,1554099545,hdfs,创建用户 test
2,更新用户,1554099546,yarn,更新用户 test1
3,删除用户,1554099547,hdfs,删除用户 test2
4,更新用户,1554189515,yarn,更新用户 test3
5,删除用户,1554199525,hdfs,删除用户 test4
6,创建用户,1554299345,yarn,创建用户 test5DataX通过json格式的配置文件来定义ETL任务,创建一个json文件:vim csv2hive.json,我们要定义的ETL任务内容如下:
{
"setting":{
},
"job":{
"setting":{
"speed":{
"channel":2
}
},
"content":[
{
"reader":{
"name":"txtfilereader",
"parameter":{
"path":[
"/root/datax/db.csv"
],
"encoding":"UTF-8",
"column":[
{
"index":0,
"type":"long"
},
{
"index":1,
"type":"string"
},
{
"index":2,
"type":"long"
},
{
"index":3,
"type":"string"
},
{
"index":4,
"type":"string"
}
],
"fieldDelimiter":","
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"defaultFS":"hdfs://192.168.243.161:8020",
"fileType":"orc",
"path":"/user/hive/warehouse/db01.db/log_dev2",
"fileName":"log_dev2.csv",
"column":[
{
"name":"id",
"type":"int"
},
{
"name":"name",
"type":"string"
},
{
"name":"create_time",
"type":"INT"
},
{
"name":"creator",
"type":"string"
},
{
"name":"info",
"type":"string"
}
],
"writeMode":"append",
"fieldDelimiter":",",
"compress":"NONE"
}
}
}
]
}
}job,job包含setting和content两部分,其中setting用于对整个job进行配置,content是数据的源和目的setting:用于设置全局channe|配置,脏数据配置,限速配置等,本例中只配置了channel个数1,也就是使用单线程执行数据传输content:
name:插件名称,需要和工程中的插件名保持-致parameter:插件对应的输入参数path:源数据文件的路径encoding:数据编码fieldDelimiter:数据分隔符column:源数据按照分隔符分割之后的位置和数据类型name:插件名称,需要和工程中的插件名保持一致parameter:插件对应的输入参数path:目标路径fileName:目标文件名前缀writeMode:写入目标目录的方式通过DataX的Python脚本执行我们定义的ETL任务:
[root@hadoop ~]# python /usr/local/datax/bin/datax.py datax/csv2hive.json
...
任务启动时刻 : 2020-11-15 11:10:20
任务结束时刻 : 2020-11-15 11:10:32
任务总计耗时 : 12s
任务平均流量 : 17B/s
记录写入速度 : 0rec/s
读出记录总数 : 6
读写失败总数 : 0查看HDFS中是否已存在相应的数据文件:
[root@hadoop ~]# hdfs dfs -ls /user/hive/warehouse/db01.db/log_dev2
Found 1 items
-rw-r--r-- 3 root supergroup 825 2020-11-15 11:10 /user/hive/warehouse/db01.db/log_dev2/log_dev2.csv__f19a135d_6c22_4988_ae69_df39354acb1e
[root@hadoop ~]# 到Hive中验证导入的数据是否符合预期:
0: jdbc:hive2://localhost:10000> use db01;
No rows affected (0.706 seconds)
0: jdbc:hive2://localhost:10000> show tables;
+-----------+
| tab_name |
+-----------+
| log_dev2 |
+-----------+
1 row selected (0.205 seconds)
0: jdbc:hive2://localhost:10000> select * from log_dev2;
+--------------+----------------+-----------------------+-------------------+----------------+
| log_dev2.id | log_dev2.name | log_dev2.create_time | log_dev2.creator | log_dev2.info |
+--------------+----------------+-----------------------+-------------------+----------------+
| 1 | 创建用户 | 1554099545 | hdfs | 创建用户 test |
| 2 | 更新用户 | 1554099546 | yarn | 更新用户 test1 |
| 3 | 删除用户 | 1554099547 | hdfs | 删除用户 test2 |
| 4 | 更新用户 | 1554189515 | yarn | 更新用户 test3 |
| 5 | 删除用户 | 1554199525 | hdfs | 删除用户 test4 |
| 6 | 创建用户 | 1554299345 | yarn | 创建用户 test5 |
+--------------+----------------+-----------------------+-------------------+----------------+
6 rows selected (1.016 seconds)
0: jdbc:hive2://localhost:10000> 接下来演示一下将MySQL数据导入Hive中。为了实现该功能,我们需要使用到mysqlreader来从MySQL中读取数据,其官方文档如下:
首先,执行如下SQL构造一些测试数据:
CREATE DATABASE datax_test;
USE `datax_test`;
CREATE TABLE `dev_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`create_time` int(11) DEFAULT NULL,
`creator` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`info` varchar(2000) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1069 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
insert into `dev_log`(`id`,`name`,`create_time`,`creator`,`info`) values
(1,‘创建用户‘,1554099545,‘hdfs‘,‘创建用户 test‘),
(2,‘更新用户‘,1554099546,‘yarn‘,‘更新用户 test1‘),
(3,‘删除用户‘,1554099547,‘hdfs‘,‘删除用户 test2‘),
(4,‘更新用户‘,1554189515,‘yarn‘,‘更新用户 test3‘),
(5,‘删除用户‘,1554199525,‘hdfs‘,‘删除用户 test4‘),
(6,‘创建用户‘,1554299345,‘yarn‘,‘创建用户 test5‘);然后到Hive的db01数据库中再创建一张表:
create table log_dev(
id int,
name string,
create_time int,
creator string,
info string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘
stored as textfile;创建ETL任务的配置文件:
[root@hadoop ~]# vim datax/mysql2hive.json文件内容如下:
{
"job":{
"setting":{
"speed":{
"channel":3
},
"errorLimit":{
"record":0,
"percentage":0.02
}
},
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"username":"root",
"password":"123456a.",
"column":[
"id",
"name",
"create_time",
"creator",
"info"
],
"where":"creator=‘${creator}‘ and create_time>${create_time}",
"connection":[
{
"table":[
"dev_log"
],
"jdbcUrl":[
"jdbc:mysql://192.168.1.11:3306/datax_test?serverTimezone=Asia/Shanghai"
]
}
]
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"defaultFS":"hdfs://192.168.243.161:8020",
"fileType":"text",
"path":"/user/hive/warehouse/db01.db/log_dev",
"fileName":"log_dev3.csv",
"column":[
{
"name":"id",
"type":"int"
},
{
"name":"name",
"type":"string"
},
{
"name":"create_time",
"type":"INT"
},
{
"name":"creator",
"type":"string"
},
{
"name":"info",
"type":"string"
}
],
"writeMode":"append",
"fieldDelimiter":",",
"compress":"GZIP"
}
}
}
]
}
}where条件来过滤需要读取的数据,具体参数可以在执行datax脚本时传入,我们可以通过这种变量替换的方式实现增量同步的支持mysqlreader默认的驱动包是5.x的,由于我这里的MySQL版本是8.x,所以需要替换一下mysqlreader中的驱动包:
[root@hadoop ~]# cp /usr/local/src/mysql-connector-java-8.0.21.jar /usr/local/datax/plugin/reader/mysqlreader/libs/
[root@hadoop ~]# rm -rf /usr/local/datax/plugin/reader/mysqlreader/libs/mysql-connector-java-5.1.34.jar 然后执行该ETL任务:
[root@hadoop ~]# python /usr/local/datax/bin/datax.py datax/mysql2hive.json -p "-Dcreator=yarn -Dcreate_time=1554099547"
...
任务启动时刻 : 2020-11-15 11:38:14
任务结束时刻 : 2020-11-15 11:38:25
任务总计耗时 : 11s
任务平均流量 : 5B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0查看HDFS中是否已存在相应的数据文件:
[root@hadoop ~]# hdfs dfs -ls /user/hive/warehouse/db01.db/log_dev
Found 1 items
-rw-r--r-- 3 root supergroup 84 2020-11-15 11:38 /user/hive/warehouse/db01.db/log_dev/log_dev3.csv__d142f3ee_126e_4056_af49_b56e45dec1ef.gz
[root@hadoop ~]# 到Hive中验证导入的数据是否符合预期:
0: jdbc:hive2://localhost:10000> select * from log_dev;
+-------------+---------------+----------------------+------------------+---------------+
| log_dev.id | log_dev.name | log_dev.create_time | log_dev.creator | log_dev.info |
+-------------+---------------+----------------------+------------------+---------------+
| 4 | 更新用户 | 1554189515 | yarn | 更新用户 test3 |
| 6 | 创建用户 | 1554299345 | yarn | 创建用户 test5 |
+-------------+---------------+----------------------+------------------+---------------+
2 rows selected (0.131 seconds)
0: jdbc:hive2://localhost:10000> 将数据采集到数仓后所面临的问题:
数据治理需要解决的问题:
数据治理的目标:
数据治理:
元数据管理:
数据血缘管理:
数据治理步骤简述:
数据治理与周边系统:
常见的数据治理工具:
Apache Altas:
Apache Altas架构图: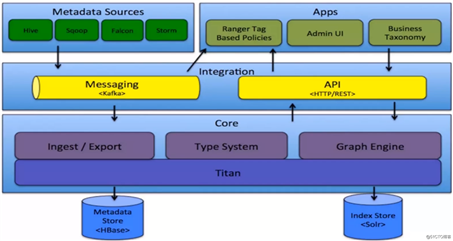
元数据捕获:
原文:https://blog.51cto.com/zero01/2551050