本脚本主要实现爬取caoliu某图片板块,前3页当天更新的帖子的所有图片,同时把图片下载到对应帖子名创建的文件夹中
爬虫主要通过python xpath来实现,同时脚本内包含,创建文件夹,分割数据,下载等操作
首先,我们分析下caoliu某图片板块的资源链接

贴子对应的页面元素

展开元素,可以看到帖子的实际地址,所以我们第一步就是把地址都给扒下来
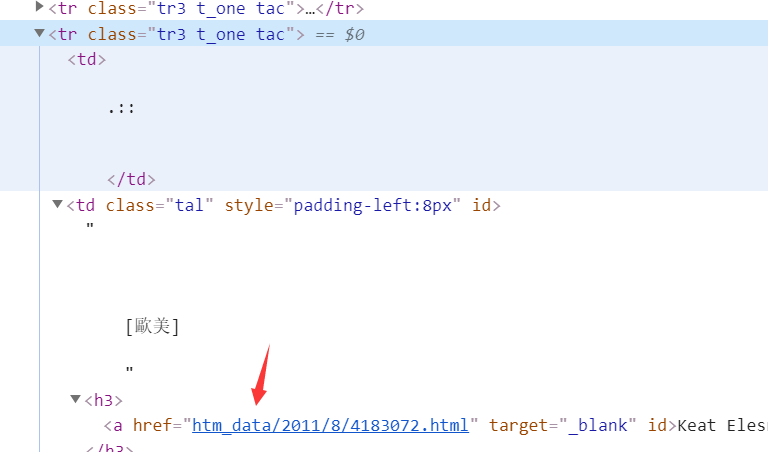
AA里包含了caoliu某图片板块前3页的地址,创建lit空集来收集爬取来的帖子地址
def stepa (AA): lit=[] for url in AA: response = requests.get(url=url, headers=headers, timeout=100000) wb_data = response.text.encode(‘iso-8859-1‘).decode(‘gbk‘)#caoliu的编码格式需要对返回值重新转码 # 将页面转换成文档树 html = etree.HTML(wb_data) a = html.xpath(‘//td[@class="tal"]//@href‘)#帖子地址xpath lit.append(a) return(lit) alllink = stepa(AA) alllink=alllink[0]
执行后的结果

我们获得帖子地址后,获取的帖子地址如上图,所以需要对地址进行处理,同时屏蔽掉站务贴
BB是需要屏蔽掉的站务贴集合,alllink是上一步骤获取的图贴集合,创建循环,从alllink集合里每次取一个链接,if用于跳过账务贴
def stepb(alllink,headers,BB): for url in alllink: #print(url) if "read" in url: continue elif url in BB: continue else: url=‘https://cl.hexie.xyz/‘+url print(url) response = requests.get(url, headers=headers) response=response.text.encode(‘iso-8859-1‘).decode(‘gbk‘) html = etree.HTML(response) b = html.xpath(‘//div[@class="tpc_content do_not_catch"]//@ess-data‘)#图片地址xpath title = html.xpath(‘/html/head/title/text()‘)#帖子名称xpath title=title[0] title=title[:-27]#去掉帖子名称后面共同的和影响创建文件夹的部分 print(title)
因为获取的链接”htm_data/2011/8/4182612.html“需要重新拼接
拼接步骤”url=‘https://cl.hexie.xyz/‘+url“
后面的步骤就是访问拼接好的url,获取帖子内的图片地址,我们分析下图片资源的元素信息
图片地址存放在"tpc_content do_not_catch"class内,所以xpath可写成”
//div[@class="tpc_content do_not_catch"]//@ess-data“
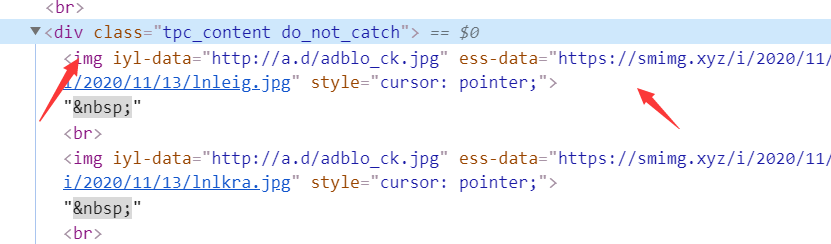
如此,图片地址就获取到了
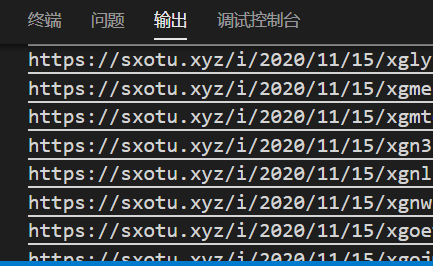
接下来,就是通过地址,下载图片资源到本地
创建文件夹参考:https://www.cnblogs.com/becks/p/13977943.html
下载图片到本地参考:https://www.cnblogs.com/becks/p/13978612.html
附上整个脚本
# -*-coding:utf8-*- # encoding:utf-8 # 本脚本用于爬取草榴图片板块(新时代的我们)最近3天的所有帖子的所有图片,每一个帖子创建独立的文件夹,图片下载到文件夹中 import requests from lxml import etree import os import sys import re import random from urllib import request import io #sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘utf8‘) #解决vscode窗口输出乱码的问题,需要import io 和import sys headers = { ‘authority‘: ‘cl.hexie.xyz‘, ‘upgrade-insecure-requests‘: ‘1‘, ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36‘, ‘accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9‘, ‘sec-fetch-site‘: ‘none‘, ‘sec-fetch-mode‘: ‘navigate‘, ‘accept-language‘: ‘zh-CN,zh;q=0.9‘, ‘cookie‘: ‘__cfduid=d9b8dda581516351a1d9d388362ac222c1603542964‘, } path = os.path.abspath(os.path.dirname(sys.argv[0])) AA=[ "https://cl.和谐.xyz/thread0806.php?fid=8", #"https://cl.和谐.xyz/thread0806.php?fid=8&search=&page=2", #"https://cl.和谐.xyz/thread0806.php?fid=8&search=&page=3" ] #AA里包含最新前3页列表链接 BB=["htm_data/1109/8/594739.html", "htm_data/1803/8/3018643.html", "htm_data/0706/8/36794.html", "htm_data/1106/8/524775.html", "htm_data/2011/8/344500.html"] #BB里面包含需要跳过的帖子,这部分帖子是站务贴,里面没资源 #第1步,获取每一页所有的帖子地址,地址格式“https://cl.和谐.xyz/htm_data/2011/8/4182841.html” def stepa (AA): lit=[] for url in AA: response = requests.get(url=url, headers=headers, timeout=100000) wb_data = response.text.encode(‘iso-8859-1‘).decode(‘gbk‘)#草榴的编码格式需要对返回值重新转码 # 将页面转换成文档树 html = etree.HTML(wb_data) a = html.xpath(‘//td[@class="tal"]//@href‘)#帖子地址xpath lit.append(a) return(lit) alllink = stepa(AA) alllink=alllink[0] #第2步,获取每一篇帖子里所有图片的地址,地址格式“https://和谐.xyz/i/2020/11/15/sedlrk.jpg" def stepb(alllink,headers,BB): for url in alllink: #print(url) if "read" in url: continue elif url in BB: continue else: url=‘https://cl.和谐.xyz/‘+url print(url) response = requests.get(url, headers=headers) response=response.text.encode(‘iso-8859-1‘).decode(‘gbk‘) html = etree.HTML(response) b = html.xpath(‘//div[@class="tpc_content do_not_catch"]//@ess-data‘)#图片地址xpath title = html.xpath(‘/html/head/title/text()‘)#帖子名称xpath title=title[0] title=title[:-27]#去掉帖子名称后面共同的和影响创建文件夹的部分 print(title) path2 = r‘D://tu‘ os.mkdir(path2 + ‘./‘+str(title)) #以上两行即在d盘tu目录下创建名称为变量title的文件夹 for c in b: print("loading"+" " +c) pic_name = random.randint(0,100)#图片名称随机命令 r = requests.get(c,stream=True,headers=headers) time = r.elapsed.total_seconds()#获取响应时间 if time > 1000: continue else: with open(path2 + ‘./‘+str(title) +‘./‘+str(pic_name) +‘.jpg‘, ‘wb‘) as fd: for chunk in r.iter_content(): fd.write(chunk) #从87行开始即下载的脚本,把图片下载到上文创建的指定文件夹中 stepb(alllink,headers,BB) #第3步:提示爬取完成 def over(): print("ok") over()
嘿嘿

python实例:爬取caoliu图片,同时下载到指定的文件夹内
原文:https://www.cnblogs.com/becks/p/13978807.html