实际工作中使用ES有一段时间了,比起一直在理论上接触ES还是要好上一些的。今天就来总结一些实际工作中用到的一些ES功能吧。本文编排顺序,按使用的先后可能性排序编排。ES的功能很强大,但我们能用到的,也许并不会太多,所以本文可作为一个简单速查手册使用哟。
# 健康检查
GET _cluster/health?pretty # 作用:可以帮助我们排查es八九是否有故障 # 结果样例如下: { "cluster_name" : "testcluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 2, "active_primary_shards" : 5, "active_shards" : 10, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0 }
GET _cat/shards?pretty
# 作用:可以帮助我们查看数据分片情况
# 结果样例如下:
。。。
GET _nodes/stats
# 帮助我们排查es集群问题,知道节点分布情况
# 结果样例如下:
。。。
GET _cat/indices?v&pretty
# 作用:可以让我们快速查看都有些什么索引及其数据量,让我们在不理解业务的情况查询数据
# 类似于sql中的 show databases; show tables;
# 结果样例如下:
。。。
GET _cat/aliases
# 作用:可以帮助你快速知道目前使用的索引可能,因为外部用户可能只知道别名,但内部索引可能会很多
# 和 show databases; show tables; 语义相近
# 结果样例如下:
。。。
# 查看某索引mapping GET /index_name/_mapping/type_name # 创建或修改mapping PUT /index_name { "mapping":{ "article":{ "properties":{ "content":{ "type": "string", "analyzer":"english" }, "post_date":{ "type":"date }, "title":{ "type":"keyword" } } } } }
# 作用:类似sql中创建修改表结构,可以让你快速了解此索引都由些什么构成,并排查可能出线问题的原因,比如text是不能用于搜索的,需要添加 fielddata:true 才可以。
# 结果样例如下:
。。。
# 一般你可以在首次插入数据时创建索引,也可以先手动创建索引,创建mapping,这样控制更好
# 创建空索引
POST index_name # 创建mapping,如上 # 也可以带分片数设置创建索引 POST index_name { "settings": { "number_of_shards": 3, "number_of_replicas": 2 } }
# 和添加数据时一样,不过需要指定id
# 更新分个别字段更新和全记录更新
# 个别字段更新使用 _update,如下 POST index_name/anytype/id1/_update { "title": "test title 001", "createDate": "2018-01-12" } # 全记录更新 POST index_name/anytype/id1/_doc { "title":"overwrtite title full" }
# 毫无疑问,es的作用就在于查询,快速及有效
# 查询场景有很多,我们按照sql的方式类比,简单分为普通查询,聚合查询,分组查询,子查询
# 1. 普通查询(可带分页),类比sql:select * from index_name where title="abc" order by id limit 0, 10 # es 查询如下 GET userindex/anytype/_search { "size": 10, "from": 0 , "query": { "term": { "title": "abc" } }, "sort": [ { "id": { "order": "asc" } } ] } # 其他查询条件可以任意在term中添加 # 2. 聚合查询,类比sql:select max(id) from index_name where title="abc" # es 查询 GET userindex/anytype/_search { "size": 10, "from": 0 , "query": { "term": { "title": "abc" } }, "aggs": { "max_id": { "max": { "field": "id" } } } } # 可以自行组合其他聚合方式,一起得出聚合结果,max,min,
# get 查询单个doc GET ‘indexName/type/1‘ # mget多个查询 get indexName/type/_mget { "docs":[{ "_id":["id1", "id2"] "_source":["field1", "field2"] }] } # 类似sql中的select f1, f2 from tb where id in (xxx);
# 索引打开关闭,是为了一些特殊场景的考量,比如我们做了索引别名,那么老的索引可能没用了,但又不敢完全保证新索引正确,所以先将旧索引关闭然后观察一段时间无误后,再将其删除,一旦出现问题,则将旧索引open恢复启用
#打开索引,使其可用 POST test/_open #关闭索引,减少资源消耗,关闭后索引不可被搜索添加操作 POST test/_close
# 删除索引就是删除索引及其对应的所有资源,类似于sql中的 drop table 或者 drop database,所以需要小心操作,后果很严重
# 删除某个索引
DELETE indexName
# 删除所有索引:
DELETE * 或者 DELETE _all
# 索引merge的目的在于将小segment合并为大文件,从而减少文件打开数量,这个动作一般是es自动完成的,但有时我们可能需要自己执行
// 强制merge POST indexname/_forcemerge?max_num_segments=1
# 如果仅仅是kv的搜索方式,则只需用 k:v 就可以进行搜索,当然你得先将字段类型设置为keyword或者 fielddata=true 才行,即开启索引的索引
# match/match_all: 普通搜索过滤
# bool/filter/must: 搜索结果过滤
# term(s) : 字段包含某些词搜索
# agg: 聚合结果
# _source: 设置字段信息
# sort: 排序结果
# exists: 空值判定查询
# prefix: 前缀匹配查询
# wildcard: 通配符查询,模糊匹配
# regexp: 正则查询
# score: 搜索评分
es为什么这么快?
system cache的重要性?
segment
translog
memorybuffer
flush
分片
集群通信raft
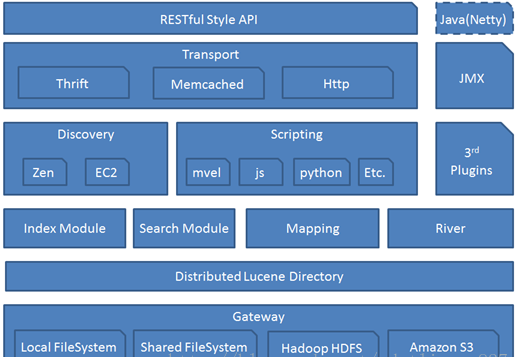
搜索流程图示例:
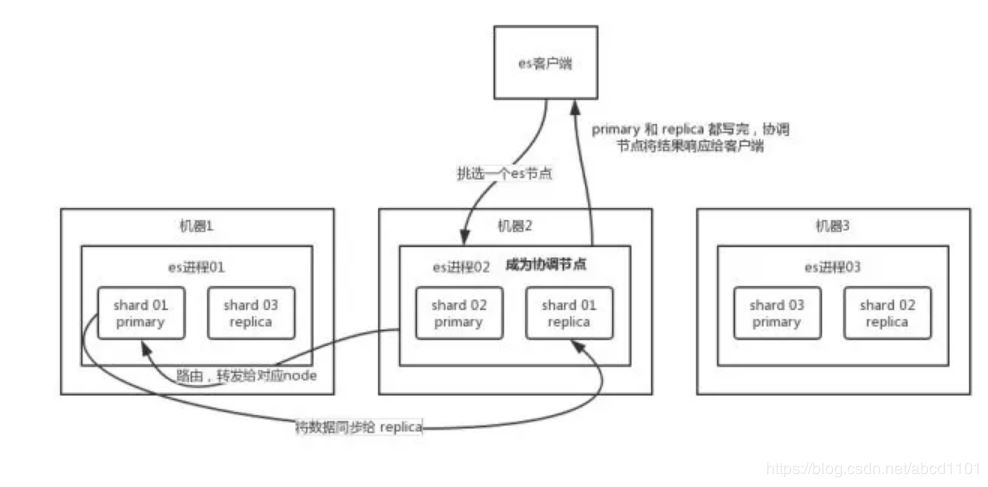
。。。
原文:https://www.cnblogs.com/yougewe/p/13975826.html