# -*- coding = utf-8 -*-
# 词云
import wordcloud as wd
# 分词,支持中文
import jieba
# 绘图,数据可视化
from matplotlib import pyplot as plt
# 矩阵运算
import numpy as np
# 操作excel主要用到xlrd和xlwt这两个库,xlrd是读excel,xlwt是写excel
import xlrd
# 图片处理
from PIL import Image
# 准备词云所需的数据,获取excel数据,这里以第5列的电影名言(总结)为例
def get_data_excel(excel_path):
# 打开excel,并创建excel对象
excel = xlrd.open_workbook(excel_path)
# 选择excel中下标为0的工作表,就是excel文件中的第一个sheet表
sheet = excel.sheets()[0]
# 获取第一行的内容, 索引从0开始
# row = sheet.row_values(0)
# 获取第一列的整列的内容
# col = sheet.col_values(0)
# 获取下标第0列,[0, 4)行数据,0~3行 (不包括第4行)
# print(sheet.col_values(0, 0, 4))
# 获取下标第0行,[0, 5)列数据,0~4列 (不包括第5列)
# print(sheet.row_values(0, 0, 5))
# 获取单个单元格数据,第几行第几个,索引从0开始
# data = sheet.cell(2, 0).value
# 获取第5列的电影名言作为内容分析
data_list = sheet.col_values(5)
# 把第5列第一行的标题 "电影名言" 去掉
data_list.remove(‘电影名言‘)
# 打印查看获取的内容
# for data in data_list:
# print(data, end=‘\n‘)
# 将所有的名言连接成一个字符串,便于词云分析
contents = ""
for data in data_list:
# 将内容添加到contents末尾
contents += data
# print(contents)
return contents
# 词云分析
def word_cloud(data):
# 使用jieba.cut切分str句子
word = jieba.cut(data)
# 使用空格隔开,看看句子分词的个数,以及其效果
word_all = ‘ ‘.join(word)
# print(f"The number of word is {len(word_all)}")
# print(word_all)
# 使用Image打开模板图片
# 打开树形图
img_tree = Image.open(‘../Data/img/tree.jpg‘)
# 将图片的像素点转换成矩阵数据
tree_array = np.array(img_tree)
# 打开哆啦A梦图片
img_love = Image.open(‘../Data/img/哆啦A梦.jpg‘)
# 将图片的像素点转换成矩阵数据
love_array = np.array(img_love)
# 生成词云的对象,并设置格式
tree = wd.WordCloud(
# 设置词云的背景颜色,这里设置成白色
background_color=‘white‘,
# 掩饰背景,就是存放词云的背景区域,默认是矩形,以下三个测试背景选择一个就好
# mask=None,
# 使用树形图作为背景
mask=tree_array,
# 使用哆啦A梦作为背景
# mask=love_array,
# 在C盘目录下搜索 Fonts,选择一个字体,右键查看属性,复制常规项里面的 完整名称
# 设置字体,不然可能不支持中文,simsun.ttc是本机的宋体字体格式
font_path=‘simsun.ttc‘
)
# 词云对象加入分析句子的来源
tree.generate_from_text(word_all)
# 设置图片的名称和尺寸
plt.figure(‘电影词云‘, figsize=(9, 6))
# 设置不使用坐标轴
plt.axis(‘off‘)
# 将词云对象放入图片中
plt.imshow(tree)
# 保存图片,注意先savefig()再show(),否则保存的图片可能一片空白,dpi是图像每英寸长度内的像素点数
plt.savefig(‘../Data/img/film.jpg‘, dpi=500)
# 显示图片
plt.show()
# 主程序
def main():
# excel保存路径
excel_path = ‘../Data/excel/top250.xls‘
# 获取excel数据
data = get_data_excel(excel_path)
# 词云分析
word_cloud(data)
# 主程序入口
if __name__ == ‘__main__‘:
main()
使用默认生成词云
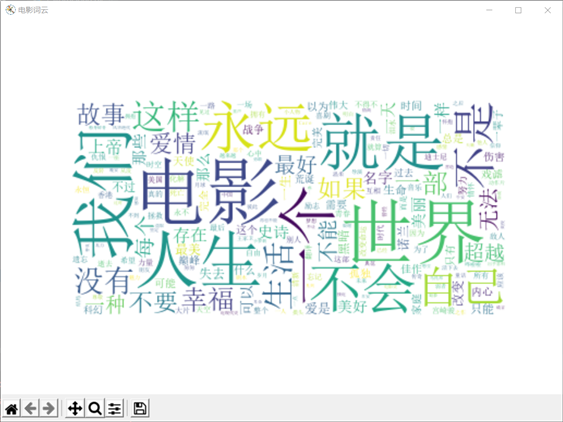
使用树形掩饰

使用哆啦A梦掩饰
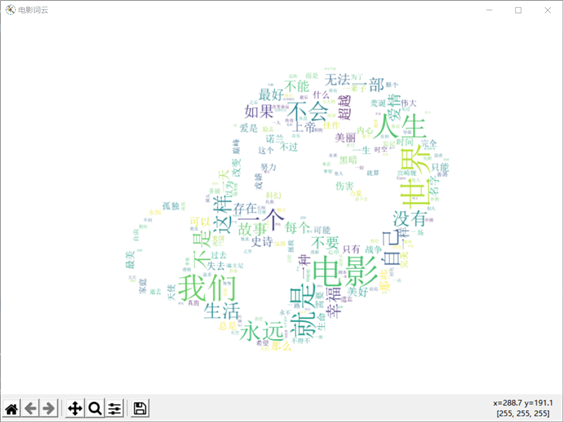
我知道某人跟我一样也很喜欢哆啦A梦,所以一定要附上哆啦A梦的图片

附上树形底图

原文:https://www.cnblogs.com/zq-zq/p/13974837.html