在当前的互联网用户,设备,服务等激增的时代下,其产生的数据量已不可同日而语了。各种业务场景都会有着大量的数据产生,如何对这些数据进行有效地处理是很多企业需要考虑的问题。以往我们所熟知的Map Reduce,Storm,Spark等框架可能在某些场景下已经没法完全地满足用户的需求,或者是实现需求所付出的代价,无论是代码量或者架构的复杂程度可能都没法满足预期的需求。新场景的出现催产出新的技术,Flink即为实时流的处理提供了新的选择。Apache Flink就是近些年来在社区中比较活跃的分布式处理框架,加上阿里在中国的推广,相信它在未来的竞争中会更具优势。 Flink的产生背景不过多介绍,感兴趣的可以Google一下。Flink相对简单的编程模型加上其高吞吐、低延迟、高性能以及支持exactly-once语义的特性,让它在工业生产中较为出众。相信正如很多博客资料等写的那样"Flink将会成为企业内部主流的数据处理框架,最终成为下一代大数据处理标准。
一.下载flink相应的csd文件和parcels文件到本地
https://archive.cloudera.com/csa/1.0.0.0/csd/
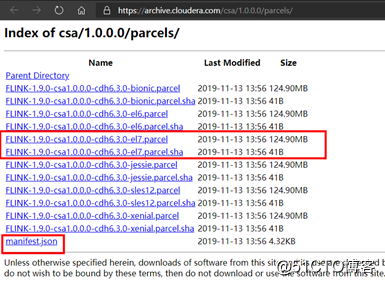
https://archive.cloudera.com/csa/1.0.0.0/parcels/
二.将下载下来的包放到集群的CDH01主节点

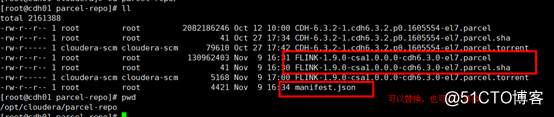
重启cm(利用命令重启cm,不要在web操作,无效)
systemctl restart cloudera-scm-server.service
三.重启完到web界面激活flink并添加服务
激活(这里是激活后的状态)
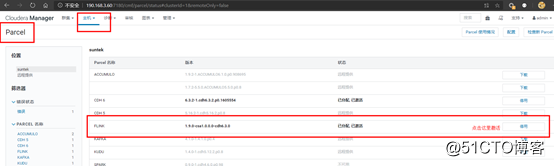
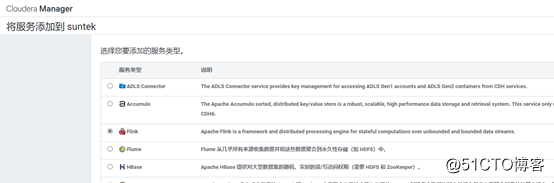
添加服务
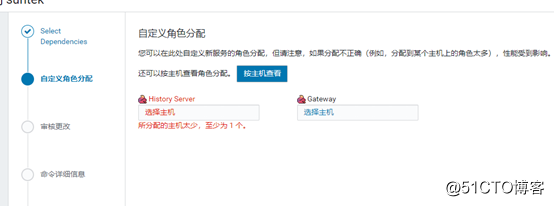
Server在cdh01上,安装了2个gateway在cdh02和cdh03上
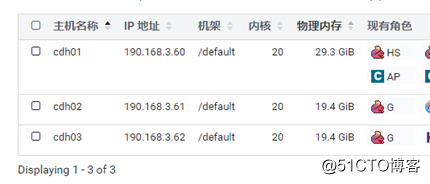
然后就直接安装,完成后点击主机面
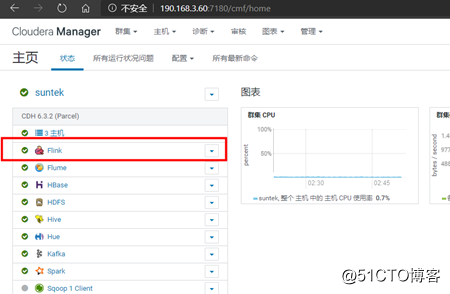
CDH6.3.2集成flink1.9.0
原文:https://blog.51cto.com/anfishr/2550429