mysql原生操作
mysql原生操作写入500万数据!
# 建库
create database mydb01;
# 使用库
use mydb01;
# 建表
create table tbl_students(
id int primary key auto_increment,
name varchar(20) unique,
gender varchar(6),
email varchar(40)
);
import pymysql
import gevent
import time
class DBUtil:
def __init__(self, host, port, username, password, db, charset=‘utf8‘):
self.host = host # mysql主机地址
self.port = port # mysql端口
self.username = username # mysql远程连接用户名
self.password = password # mysql远程连接密码
self.db = db # mysql使用的数据库名
self.charset = charset # mysql使用的字符编码,默认为utf8
self.connect() # __init__初始化之后,执行的函数
def connect(self):
# pymysql连接mysql数据库
# 需要的参数host,port,user,password,db,charset
self.conn = pymysql.connect(host=self.host,
port=self.port,
user=self.username,
password=self.password,
db=self.db,
charset=self.charset
)
# 连接mysql后执行协程方法
self.asynchronous()
# 线程
def run(self, nmin, nmax):
# 创建游标
self.cur = self.conn.cursor()
# 定义sql语句,插入数据id,name,gender,email
sql = "insert into tbl_students(id,name,gender,email) values (%s,%s,%s,%s)"
# 定义总插入行数为一个空列表
data_list = []
for i in range(nmin, nmax):
# 添加所有任务到总的任务列表
result = (i, ‘mayun‘ + str(i), ‘male‘, ‘mayun‘ + str(i) + ‘@qq.com‘)
data_list.append(result)
# 执行多行插入,executemany(sql语句,数据(需一个元组类型))
content = self.cur.executemany(sql, data_list)
if content:
print(f‘成功插入第{nmax - 1}条数据‘)
# 提交数据,必须提交,不然数据不会保存
self.conn.commit()
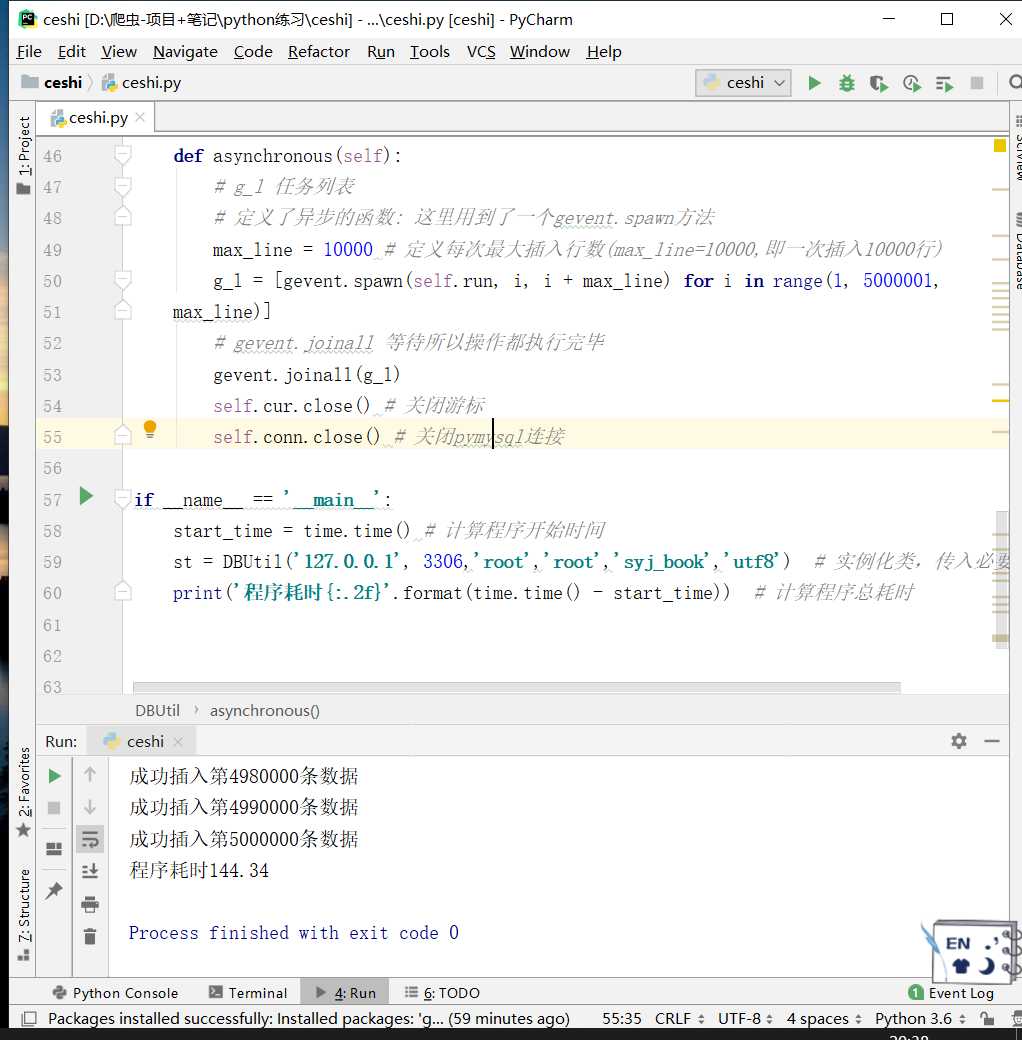
def asynchronous(self):
# g_l 任务列表
# 定义了异步的函数: 这里用到了一个gevent.spawn方法
max_line = 10000 # 定义每次最大插入行数(max_line=10000,即一次插入10000行)
g_l = [gevent.spawn(self.run, i, i + max_line) for i in range(1, 3000001,
max_line)]
# gevent.joinall 等待所以操作都执行完毕
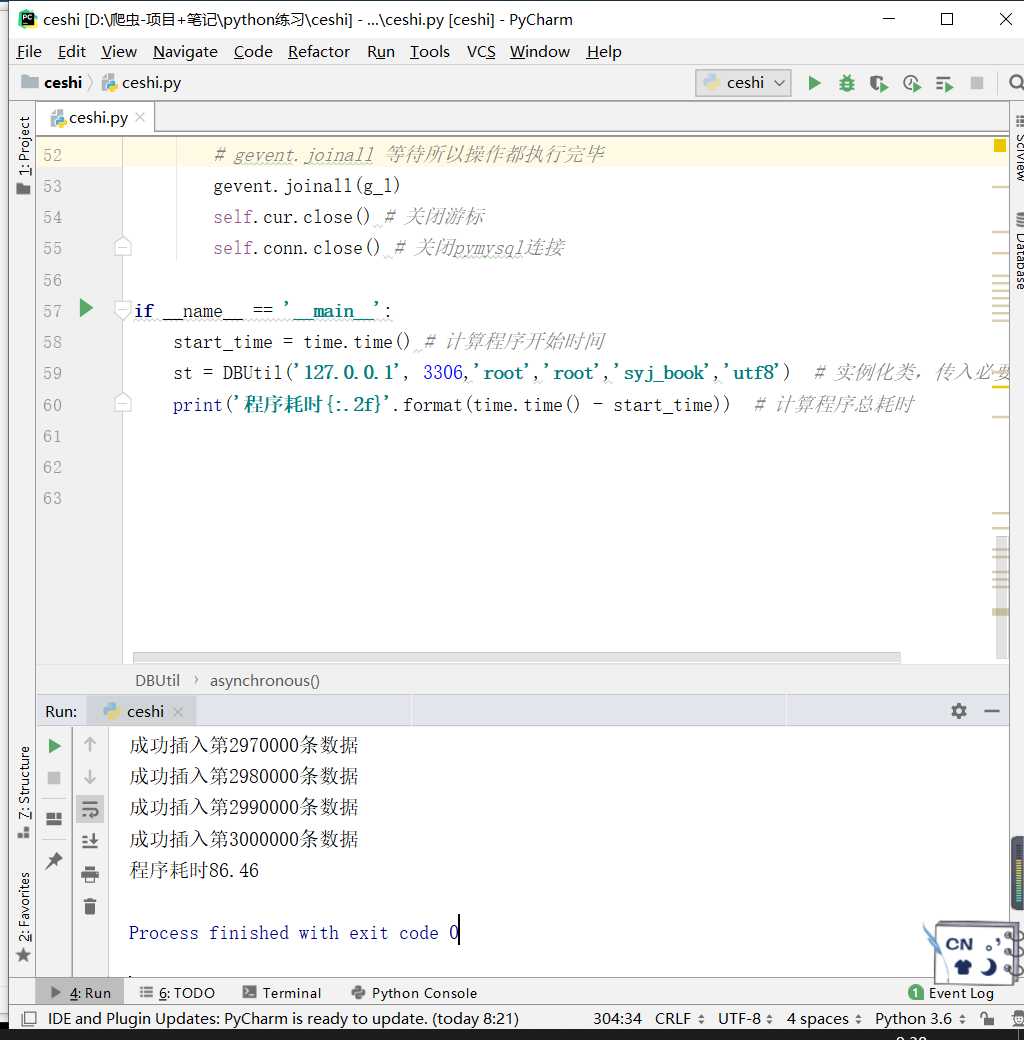
gevent.joinall(g_l)
self.cur.close() # 关闭游标
self.conn.close() # 关闭pymysql连接
if __name__ == ‘__main__‘:
start_time = time.time() # 计算程序开始时间
st = DBUtil(‘127.0.0.1‘, 3306,‘root‘,‘root‘,‘mydb01‘,‘utf8‘) # 实例化类,传入必要参数
print(‘程序耗时{:.2f}‘.format(time.time() - start_time))
# 计算程序总耗时
[Flask]sqlalchemy批量插入数据(性能问题)
方式1:
first_time = datetime.utcnow()
for i in range(10000):
user = User(username=username + str(i), password=password)
db.session.add(user)
db.session.commit()
second_time = datetime.utcnow()
print((second_time - first_time).total_seconds())
# 38.14347s
方式2:
second_time = datetime.utcnow()
db.session.bulk_save_objects(
[
User(username=username + str(i), password=password)
for i in range(10000)
]
)
db.session.commit()
third_time = datetime.utcnow()
print((third_time - second_time).total_seconds())
# 2.121589s
方式3:
third_time = datetime.utcnow()
db.session.bulk_insert_mappings(
User,
[
dict(username="NAME INSERT " + str(i), password=password)
for i in range(10000)
]
)
db.session.commit()
fourth_time = datetime.utcnow()
print((fourth_time - third_time).total_seconds())
# 1.13548s
方式4:
fourth_time = datetime.utcnow()
db.session.execute(
User.__table__.insert(),
[{"username": ‘Execute NAME ‘ + str(i), "password": password} for i in range(10000)]
)
db.session.commit()
five_time = datetime.utcnow()
print((five_time - fourth_time).total_seconds())
# 0.888822s
Django之ORM性能优化
利用标准数据库优化技术
索引,给关键的字段添加索引
如:给表的关联字段,搜索频率高的字段加上索引等
使用适当字段类型
本来varchar就搞定的字段,就别要text类型
了解Django的QuerySets
QuerySets是有缓存的,一旦取出来,它就会在内存里呆上一段时间,尽量重用它。
# 了解缓存属性:
entry = Entry.objects.get(id=1)
entry.blog # 博客实体第一次取出,是要访问数据库的
entry.blog # 第二次再用,那它就是缓存里的实体了,不再访问数据库
entry = Entry.objects.get(id=1)
entry.authors.all() # 第一次all函数会查询数据库
entry.authors.all() # 第二次all函数还会查询数据库
all,count exists是调用函数(需要连接数据库处理结果的),注意在模板template里的代码,模板里不允许括号,但如果使用此类的调用函数,一样去连接数据库的,能用缓存的数据就别连接到数据库去处理结果。
还要注意的是,自定义的实体属性,如果调用函数的,记得自己加上缓存策略。
利用好模板的with标签:
模板中多次使用的变量,要用with标签,把它看成变量的缓存行为吧。
使用QuerySets的iterator():
通常QuerySets先调用iterator再缓存起来,当获取大量的实体列表而仅使用一次时,缓存行为会耗费宝贵的内存,这时iterator()能帮到你,iterator()只调用iterator而省 去了缓存步骤,显著减少内存占用率,具体参考相关文档
数据库的工作就交给数据库本身计算,别用Python处理
1.使用 filter and exclude 过滤不需要的记录,这两个是最常用语句,相当是SQL的where
2.同一实体里使用F()表达式过滤其他字段
3.使用annotate对数据库做聚合运算
4.使用QuerySet.extra() extra虽然扩展性不太好,但功能很强大,如果实体里需要需要增加额外属性,不得已时,通过extra来实现,也是个好办法
5.使用原生的SQL语句 如果发现Django的ORM已经实现不了你的需求,而extra也无济于事的时候,那就用原生SQL语句
1.如果需要就一次性取出你所需要的数据
单一动作(如:同一个页面)需要多次连接数据库时,最好一次性取出所有需要的数据,减少连接数据库次数。
相反,别取出你不需要的东西。
使用QuerySet.count()代替len(queryset),虽然这两个处理得出的结果是一样的,但前者性能优秀很多。同理判断记录存在时,QuerySet.exists()比if queryset实在强得太多了
懂减少数据库的连接数
使用 QuerySet.update() 和 delete(),这两个函数是能批处理多条记录的,适当使用它们事半功倍;如果可以,别一条条数据去update delete处理。
对于一次性取出来的关联记录,获取外键的时候,直接取关联表的属性,而不是取关联属性,如:
entry.blog.id
优于
entry.blog__id
# 善于使用批量插入记录,如:
Entry.objects.bulk_create([
Entry(headline="Python 3.0 Released"),
Entry(headline="Python 3.1 Planned")
])
优于
Entry.objects.create(headline="Python 3.0 Released")
Entry.objects.create(headline="Python 3.1 Planned")
# 前者只连接一次数据库,而后者连接两次
# 还有相似的动作需要注意的,如:多对多的关系,
my_band.members.add(me, my_friend)
优于
my_band.members.add(me)
my_band.members.add(my_friend)原文:https://www.cnblogs.com/shiyujie/p/13955572.html