Logistics Regression
我们知道线性回归模型可以处理回归问题,但是如何处理分类问题?
对于一个二分类问题,或许我们可以认为w*x+b > 0为正类,其他情况为负类。
那么模型不就变成了:y = f(z) ,z = w*x+b,即 y = f(w*x+b)
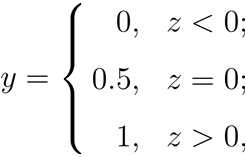
z大于零就判为正例,小于零就判为反例,z为临界值零则可任意判别 。
不难发现我们提出了一个新的函数 f ,也就是阶跃函数作为一个联系函数,把 z = w*x+b一个线性模型和 y 联系起来了。
于是我们把这种加入了联系函数的新的线性模型称之为广义线性模型。
广义线性模型的一般形式为:
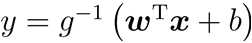
在这里,g 称为联系函数,因此我们刚才说的 f 是联系函数是有点区别的,f 函数应该是 g 的反函数,g 是关于y 的一个函数,也就 g(y) = w*x+b,不难发现,广义线性模型的目的是希望用线性模型w*x+b来逼近y 的衍生物 g(y)。
Why logistic ?
从阶跃函数的图像上看,不难发现它是一个不是一个严格单调的函数(ps:西瓜书上说是因为连续,并未说明要求单调,但是笔者认为是因为不是严格单调所以才不能使用阶跃函数),因此不能作为 g 的反函数。于是我们想引入一个单调可微的函数,sigmoid函数。
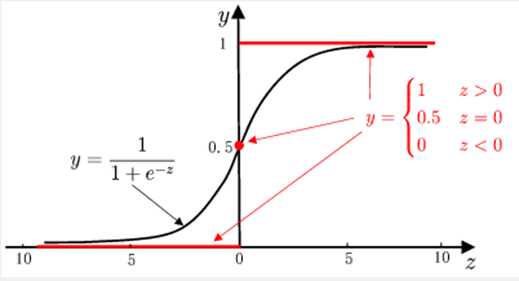
所以 :
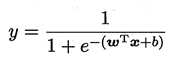
若将 y 视为样本 x 下作为正例的可能性,则1-y 则是负例的可能性。我们称
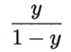
为几率(odds) ,几率反映了x作为正例的相对可能性,对几率取对数得到对数几率(log odds,也称 logit):
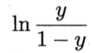
此处我们进行一番推导:
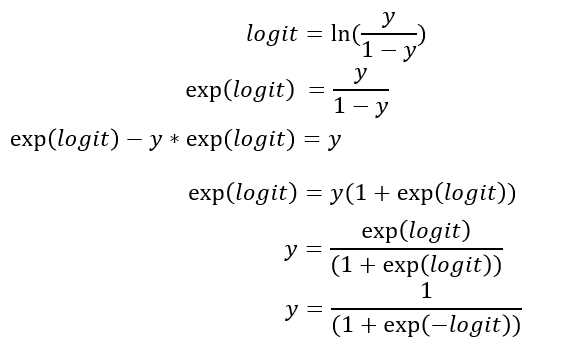
至此,我们发现对数几率 logit 和 y 的关系是sigmoid函数关系,这也是开头为什么我们要用sigmoid函数原因。
接着我们根据这个式子,我们提出假设: 对数几率 logit 和 x 满足线性相关,即 logit = w*x+b。
因此呼应了我们提出的对数几率回归模型,使用sigmoid函数作为联系函数,用线性模型去逼近真实的对数几率。
因此这就是为什么该模型称为对数几率回归模型。
当我们不知道数据分布的情况下,我们得到的模型输出不仅仅是预测的类别,而是近似的概率。
什么时候能够确定我们的输出是概率呢?
需要满足两个条件:
1. y服从Bernoulli分布(只有分类问题0,1值,经常会选择该假设。该假设的意义在于对每一个确定的x,y仍然是一个随机变量)
2. 对数几率 logit 和 x 满足线性相关。
只有这两个条件满足输出的才是概率,否则输出的是一种近似概率的置信度。
参考资料:
1、周志华——《机器学习》
2、逻辑回归输出的值是真实的概率吗?——https://www.jianshu.com/p/a8d6b40da0cf
3、李航——《统计学习方法》
原文:https://www.cnblogs.com/ISGuXing/p/13921097.html