多年以后,还有很多程序员不知道SQL Server2005有了更方便的分页方法,这就是ROW_NUMBER()函数。我们知道SQL2000时代的分页方式是TOP加NOT IN截取中间数据,效率也是很不错的,但这两种效率到底如何呢,我们这次以一万、十万和百万数据量的数据做演示,比较这两种分页方式的效率。另外为何使用TOP+NOT IN来和ROW_NUMBER()比较,是因为和游标方式及ISNULL方式分页来说,TOP+NOT IN方式效率更高。前人已有证明,可参考这篇文章:http://www.cnblogs.com/morningwang/archive/2009/01/02/1367277.html ,或者自行搜索更权威文章。
准备工具:电脑(当然了o(∩_∩)o )和程序员一名。
同一测试环境,电脑配置如下,数据如有不实,请找周鸿祎~

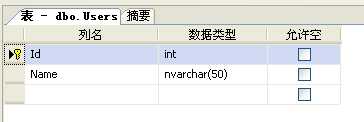
建立数据表,插入相应数据。表结构如下,Id为自增长主键:
插入100万条测试数据:
user table3godeclare @index intset @index=0while @index<1000000 begin insert into Users(Name) values(‘walkingp‘) set @index=@index+1 end |
接下来先扫盲一下ROW_NUMBER()函数。
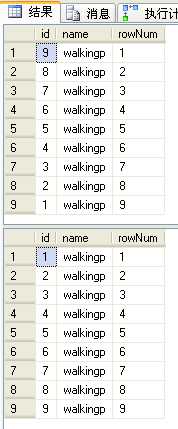
ROW_NUMBER()函数是根据参数传递过来的order by子句的值,返回一个不断递增的整数值,也就是它会从1一直不断自增1,直到条件不再满足。例如表Users(Id,Name),使用以下sql语句进行查询:
select id,name,row_number() over(order by Id desc) as rowNum from users where id<10select id,name,row_number() over(order by Id) as rowNum from users where id<10 |
两条语句order by排序相反,执行结果如下:
以下两种情况,同样取500000到500100中间的数据。
1、使用ROW_NUMBER()函数。
SQL语句如下:
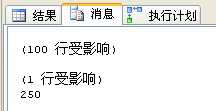
declare @time datetimedeclare @ms intset @time= getdate()select Id,Name from (select row_number() over(order by Id) as rowNum,* from users) as t where rowNum between 500000 and 500100set @ms=datediff(ms,@time,getdate())print @ms--毫秒数 |
测试了几次,平均在250毫秒:
2、使用TOP加NOT IN方法。
SQL语句如下:
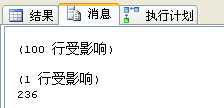
select top 100 * from users where Id not in (select top 500000 id from users order by id) order by id |
平均在236毫秒:
好吧,一起执行看看结果:
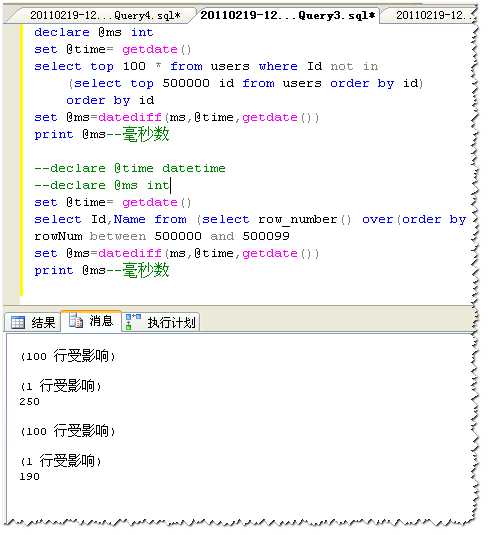
或者你认为SQL存在缓存的问题,把两部分顺序对掉一下:
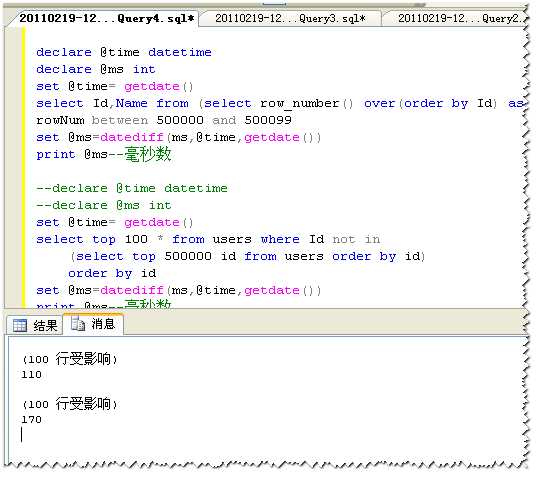
以上是百万数据量的对比,再看看1万条数据下的对比:
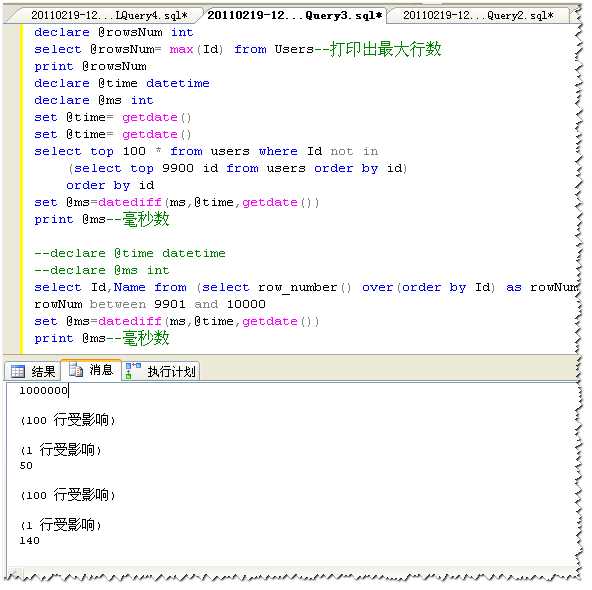
通过以上对比可以我们可以得到这样的结论:在小数据量下(一般应该认为是10万以下,TOP+NOT IN分页方式效率要比ROW_NUMBER()高;在大数据量下(百万级)ROW_NUMBER()分页方式效率要更高一些。
SQL Server 2005的ROW_NUMBER()分页效率比较
原文:https://www.cnblogs.com/shijiehaiyang/p/13902891.html