字符“hello world" 是unicode 字符集,utf-8和gbk为字符编码方式。
ASCll有编码方式和ASCII字符集
编码:是将对应的字符集中的的字符转化为二进制存储,打印时方便看自动转为16进制
解码:是将二进制的数据转化成对应字符集中的字符。
UTF-8 属于变长的编码方式,它可以由 1,2,3,4 四种字节组合,使用的是高位保留的方式来区别不同变长,具体方式如下:
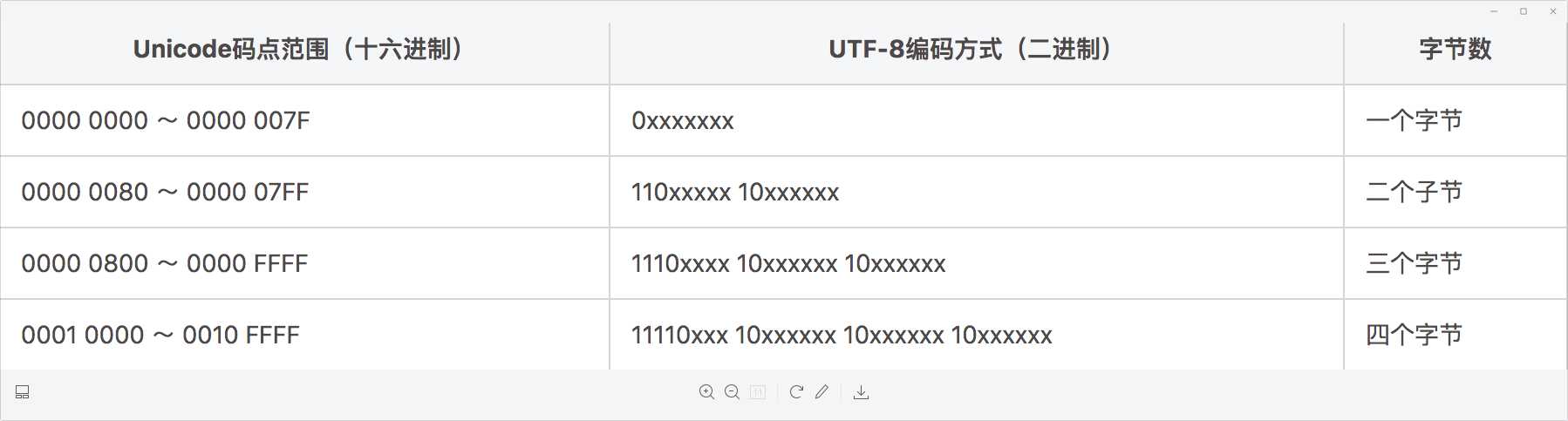 根据上表,编码字符时就非常简单了,以汉字 “丑” 为例,它的码点为 0x4E11(0100 1110 0001 0001)在上表的第三行范围(0000 0800 ~ 0000 FFFF)内,因此 “丑” 需要以三个字节的形式编码:
根据上表,编码字符时就非常简单了,以汉字 “丑” 为例,它的码点为 0x4E11(0100 1110 0001 0001)在上表的第三行范围(0000 0800 ~ 0000 FFFF)内,因此 “丑” 需要以三个字节的形式编码: 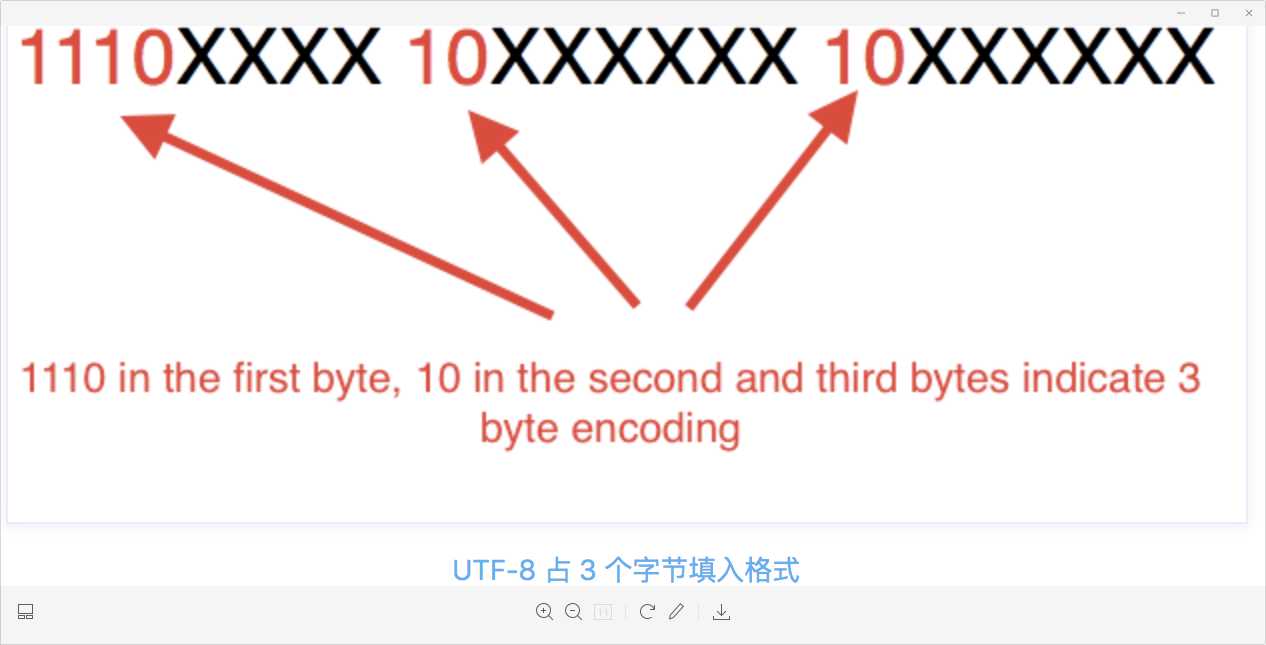
这里最高位的第一个字节中的三个 1 表示该字符占 3 个字节,空出的 16 位 x 就会从 “丑” 的最后一个二进制位开始,依次从后向前填入格式中,多出的位补 0,这样就得到了 “丑” 的 UTF-8 编码是 11100100 10111000 10010001,转换成十六进制就是 E4B891。
a="丑" a.encode("utf-8") b‘\xe4\xb8\x91‘
解码 UTF-8 编码也很简单了,如果一个字节的第一位是 0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个 1,就表示当前字符占用多少个字节,”丑” 有三个 1 表示占三个字符,然后取出有效位即可。

原文:https://www.cnblogs.com/wuzhibinsuib/p/13829441.html