一、主题式网络爬虫设计方案
1.主题式网络爬虫
爬取酷狗top500歌曲热度排名
2.主题式网络爬虫爬取的内容与数据特征分析
内容及数据特征分析:对酷狗TOP500上歌曲的热度排行做一个可视化表格,
主要是爬取酷狗音乐榜单酷狗TOP500的歌曲排名
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:用requests库抓取页面信息,用BeautifulSoup库解析网页,创建excel存储数据进行数据分析
技术难点:excel的创建和相关系数散点图与建立回归方程
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
搜索https://www.kugou.com/,打开主页,然后点击榜单找到榜单页面,如图所示
2.Htmls页面解析
3.节点(标签)查找方法与遍历方法
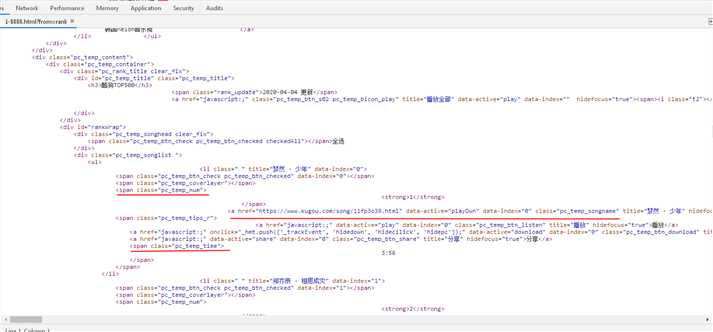
按“F12"打开网页源代码,如图所示
用find_all()方法进行遍历
三、网络爬虫程序设计
1.数据爬取与采集
爬取代码如下

1 import requests
2 import time
3 import xlwt
4 from bs4 import BeautifulSoup
5
6 #创建Excel存储数据
7 class Spider:
8 def __init__(self):
9 self.workbook, self.worksheet = self.create_excel()
10 self.nums = 1
11
12 def create_excel(self):
13 workbook = xlwt.Workbook(encoding=‘utf-8‘)
14 worksheet = workbook.add_sheet(‘Sheet1‘)
15 title = [‘排名‘, ‘歌手和歌名‘, ‘播放时间‘]
16 for index, title_data in enumerate(title):
17 worksheet.write(0, index, title_data)
18 return workbook, worksheet
19
20 def get_html(self,url):
21 headers = {‘User-Agent‘: ‘Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)‘, } # 爬虫请求头信息
22 response = requests.get(url, headers=headers)
23 if response.status_code == 200: # 如果请求状态值为200,则输出
24 return response.text
25 else:
26 return ‘产生异常‘
27
28
29 def get_data(self,html):
30 soup = BeautifulSoup(html, ‘lxml‘) # 用BeautifulSuop库解析网页
31 ranks = soup.find_all(‘span‘, class_=‘pc_temp_num‘) # 排名
32 names = soup.find_all(‘a‘, class_=‘pc_temp_songname‘) # 歌手和歌名
33 times = soup.find_all(‘span‘, class_=‘pc_temp_time‘) # 播放时间
34
35 # 打印信息
36 for r, n, t in zip(ranks, names, times): # 用zip函数
37 r = r.get_text().replace(‘\n‘, ‘‘).replace(‘\t‘, ‘‘).replace(‘\r‘, ‘‘)
38 n = n.get_text()
39 t = t.get_text().replace(‘\n‘, ‘‘).replace(‘\t‘, ‘‘).replace(‘\r‘, ‘‘)
40 data = {‘排名‘: r, ‘歌名-歌手‘: n, ‘播放时间‘: t}
41 self.worksheet.write(self.nums, 0, str(r))
42 self.worksheet.write(self.nums, 1, str(n))
43 self.worksheet.write(self.nums, 2, str(t))
44 self.nums += 1
45
46 def main(self,):
47 urls = [‘https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank‘.format(str(i)) for i in range(1, 24)] # 用for循环
48 for url in urls:
49 print(url)
50 html = self.get_html(url)
51 self.get_data(html)
52 time.sleep(1) # 暂停1S
53 self.workbook.save(‘data.xls‘)#存入所有信息后保存为data.xls
54
55
56 if __name__ == ‘__main__‘: # 程序执行时调用主程序main()
57 spider = Spider()
58 spider.main()
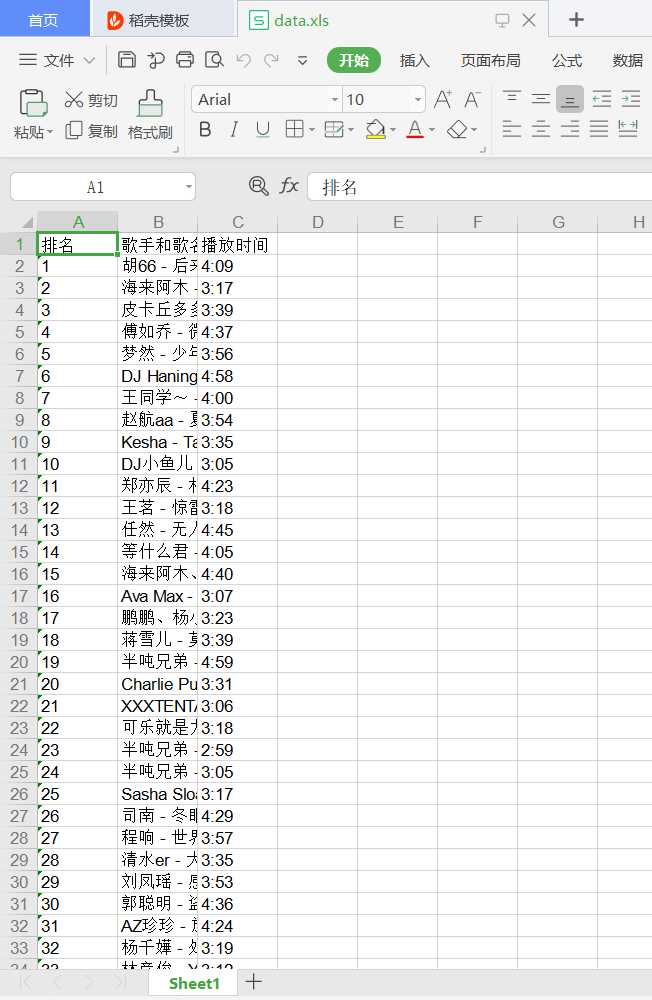
运行结果如图
2.对数据进行清洗和处理
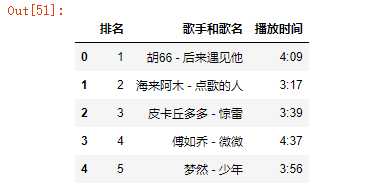
输出数据文件的前5行
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘)) 3 kugou.head()
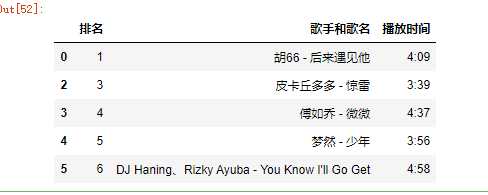
(1)删除无效行与列
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘)) 3 kugou.head() 4 kugou.drop(1,axis=0,inplace=True) 5 kugou.head()
(2)重复值处理,索引判断词没有出现“True”
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘)) 3 kugou.head() 4 kugou.duplicated()

(3)空值与缺失值处理
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘)) 3 kugou.head() 4 kugou[‘播放时间‘].isnull().value_counts()

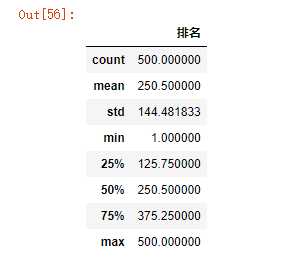
(4)异常值处理
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘)) 3 kugou.head() 4 kugou.describe()
3.文本分析(可选):jieba分词、wordcloud的分词可视化
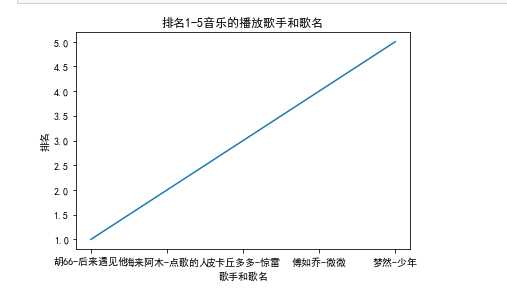
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
1 import matplotlib
2 from matplotlib import pyplot
3 matplotlib.rcParams[‘font.sans-serif‘]=[‘SimHei‘]
4 x = [‘胡66-后来遇见他‘,‘海来阿木-点歌的人‘,‘皮卡丘多多-惊雷‘,‘傅如乔-微微‘,‘梦然-少年‘]
5 y = [1,2,3,4,5]
6 pyplot.plot(x,y)
7 plt.xlabel("歌手和歌名")
8 plt.ylabel("排名")
9 plt.title(‘排名1-5音乐的播放歌手和歌名‘)
10 pyplot.show()
1 import matplotlib.pyplot as plt
2 plt.rcParams[‘font.family‘]=[‘sans-serif‘]
3 plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘]
4 plt.bar([‘胡66-后来遇见他‘,‘海来阿木-点歌的人‘,‘皮卡丘多多-惊雷‘,‘傅如乔-微微‘,‘梦然-少年‘],[1,2,3,4,5])
5 plt.legend()
6 plt.xlabel("歌手和歌名")
7 plt.ylabel("排名")
8 plt.title(‘排名1-5音乐的歌手和歌名‘)
9 pyplot.show()
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)
1 import numpy as np
2 import pandas as pd
3 import sklearn
4 kugou_df=pd.read_excel(‘data.xls‘)
5 kugou_df.head()
6 from sklearn.linear_model import LinearRegression
7 X = kugou_df.drop("排名",axis=1)
8 predict_model = LinearRegression()
9 predict_model.fit(X,kugou_df[‘排名‘])#训练模型
10 print("回归系数为:",predict_model.coef_)#判断相关性
1 import numpy as np 2 import pandas as pd 3 import seaborn as sns 4 kugou_df = pd.read_excel(‘data.xls‘) 5 kugou_df.columns 6 DataFrame=kugou_df[["排名","歌手和歌名","播放时间"]] 7 sns.regplot(kugou_df.排名,kugou_df.歌手和歌名)
6.数据持久化
7.将以上各部分的代码汇总,附上完整程序代码
1 import requests
2 import time
3 import xlwt
4
5 from bs4 import BeautifulSoup
6
7 #创建Excel存储数据
8 class Spider:
9 def __init__(self):
10 self.workbook, self.worksheet = self.create_excel()
11 self.nums = 1
12
13 def create_excel(self):
14 workbook = xlwt.Workbook(encoding=‘utf-8‘)
15 worksheet = workbook.add_sheet(‘Sheet1‘)
16 title = [‘排名‘, ‘歌手和歌名‘, ‘播放时间‘]
17 for index, title_data in enumerate(title):
18 worksheet.write(0, index, title_data)
19 return workbook, worksheet
20
21 def get_html(self,url):
22 headers = {‘User-Agent‘: ‘Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)‘, } # 爬虫请求头信息
23 response = requests.get(url, headers=headers)
24 if response.status_code == 200: # 如果请求状态值为200,则输出
25 return response.text
26 else:
27 return ‘产生异常‘
28
29 #获取数据
30 def get_data(self,html):
31 soup = BeautifulSoup(html, ‘lxml‘) # 用BeautifulSuop库解析网页
32 ranks = soup.find_all(‘span‘, class_=‘pc_temp_num‘) # 排名
33 names = soup.find_all(‘a‘, class_=‘pc_temp_songname‘) # 歌手和歌名
34 times = soup.find_all(‘span‘, class_=‘pc_temp_time‘) # 播放时间
35
36 # 打印信息
37 for r, n, t in zip(ranks, names, times): # 用zip函数
38 r = r.get_text().replace(‘\n‘, ‘‘).replace(‘\t‘, ‘‘).replace(‘\r‘, ‘‘)
39 n = n.get_text()
40 t = t.get_text().replace(‘\n‘, ‘‘).replace(‘\t‘, ‘‘).replace(‘\r‘, ‘‘)
41 data = {‘排名‘: r, ‘歌名-歌手‘: n, ‘播放时间‘: t}
42 self.worksheet.write(self.nums, 0, str(r))
43 self.worksheet.write(self.nums, 1, str(n))
44 self.worksheet.write(self.nums, 2, str(t))
45 self.nums += 1
46
47 def main(self,):
48 urls = [‘https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank‘.format(str(i)) for i in range(1, 24)] # 用for循环
49 for url in urls:
50 print(url)
51 html = self.get_html(url)
52 self.get_data(html)
53 time.sleep(1) # 暂停1S
54 self.workbook.save(‘data.xls‘)
55
56
57 if __name__ == ‘__main__‘: # 程序执行时调用主程序main()
58 spider = Spider()
59 spider.main()
60
61 #对数据进行清洗和处理
62 import pandas as pd
63 kugou=pd.DataFrame(pd.read_excel(‘data.xls‘))
64 kugou.head()#输出数据文件的前5行
65
66 kugou.drop(1,axis=0,inplace=True)#删除无效行与列
67
68 kugou.duplicated()#缩影重复值处理
69
70 kugou[‘播放时间‘].isnull().value_counts()#查找空值与缺失值处理
71
72 kugou.describe()#索引异常值处理
73 kugou.head()
74
75 #绘制图像
76 import matplotlib
77 from matplotlib import pyplot
78 matplotlib.rcParams[‘font.sans-serif‘]=[‘SimHei‘]
79 x = [‘胡66-后来遇见他‘,‘海来阿木-点歌的人‘,‘皮卡丘多多-惊雷‘,‘傅如乔-微微‘,‘梦然-少年‘]
80 y = [1,2,3,4,5]
81 pyplot.plot(x,y)
82 plt.xlabel("歌手和歌名")
83 plt.ylabel("排名")
84 plt.title(‘排名1-5音乐的播放歌手和歌名‘)
85 pyplot.show()
86
87 import matplotlib.pyplot as plt
88 plt.rcParams[‘font.family‘]=[‘sans-serif‘]
89 plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘]
90 plt.bar([‘胡66-后来遇见他‘,‘海来阿木-点歌的人‘,‘皮卡丘多多-惊雷‘,‘傅如乔-微微‘,‘梦然-少年‘],[1,2,3,4,5])
91 plt.legend()
92 plt.xlabel("歌手和歌名")
93 plt.ylabel("排名")
94 plt.title(‘排名1-5音乐的歌手和歌名‘)
95 pyplot.show()
96
97 import seaborn as sns
98 file_path = "data.xls"
99 df = pd.read_excel(file_path,names=[‘排名‘,‘歌手和歌名‘,‘播放时间‘])
100 sns.boxplot(x=‘播放时间‘,y=‘排名‘,data=df)
101
102 #分析相关系数
103 import numpy as np
104 import pandas as pd
105 import sklearn
106 kugou_df=pd.read_excel(‘data.xls‘)
107 kugou_df.head()
108 from sklearn.linear_model import LinearRegression
109 X = kugou_df.drop("排名",axis=1)
110 predict_model = LinearRegression()
111 predict_model.fit(X,kugou_df[‘排名‘])#训练模型
112 print("回归系数为:",predict_model.coef_)#判断相关性
113
114 #绘制散点图,建立回归方程
115 import numpy as np
116 import pandas as pd
117 import seaborn as sns
118 kugou_df = pd.read_excel(‘data.xls‘)
119 kugou_df.columns
120 DataFrame=kugou_df[["排名","歌手和歌名","播放时间"]]
121 sns.regplot(kugou_df.排名,kugou_df.歌手和歌名)
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
酷狗音乐TOP500的音乐热度非常高
排行榜上歌手多为网络歌手
2.对本次程序设计任务完成的情况做一个简单的小结。
本次程序让我跟了解了python,同时也让我知道了自己的不足
原文:https://www.cnblogs.com/li128/p/13734550.html