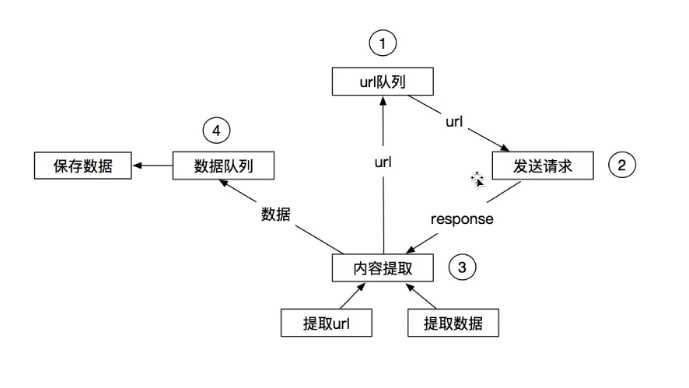
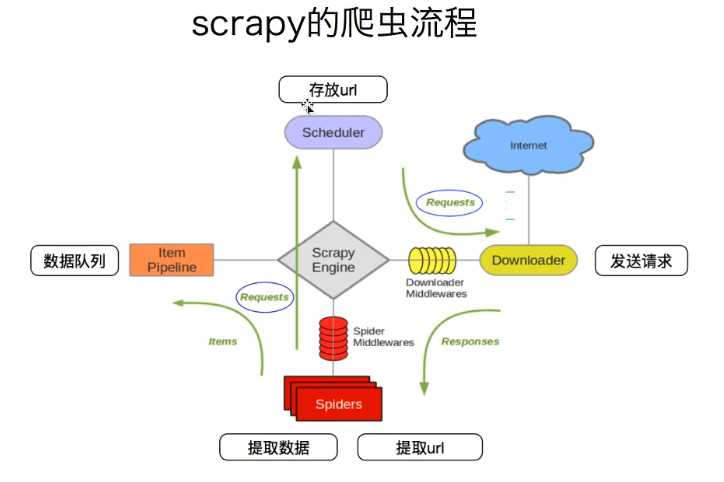

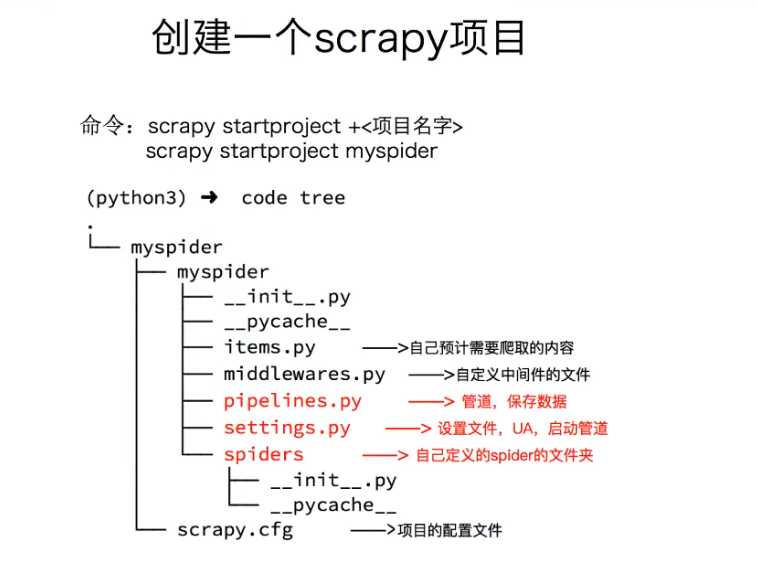
安装scrapy模块 :
pip install scrapy
创建scrapy项目
1.scrapy startprojecty 项目名称
注意:如果创建失败,可以先卸载原有的scrapy模块,使用pip3 intall scrapy 进行安装

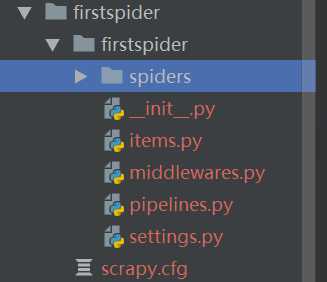
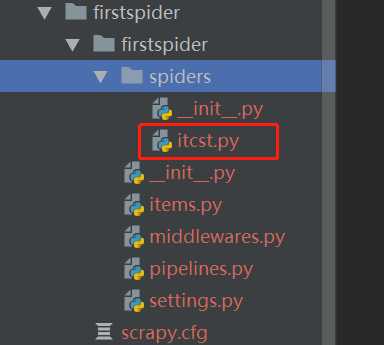
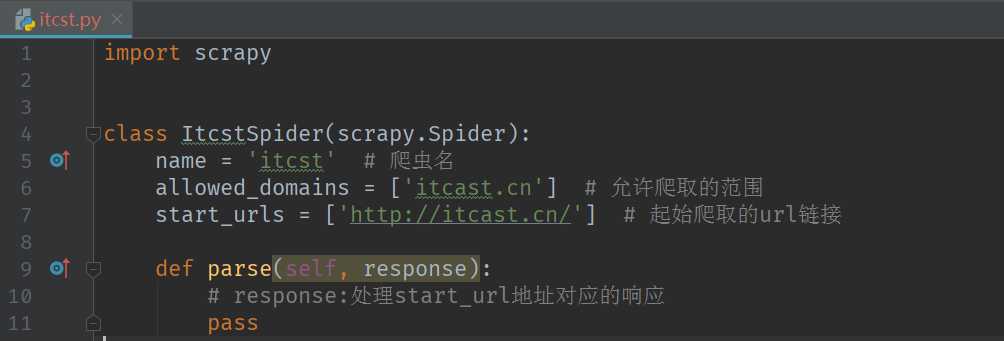
2.生成一个爬虫
scrapy genspider 爬虫名 要爬取的域名 eg: scrapy genspider itcast itcast.cn
如下图:
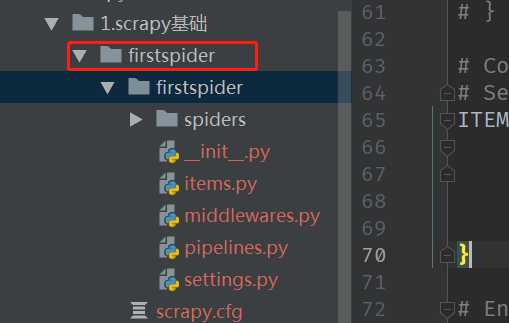
3.启动爬虫 scrapy crawl itcast
注意:启动爬虫的位置是在项目目录中 ,也就是在如下图
注意事项:
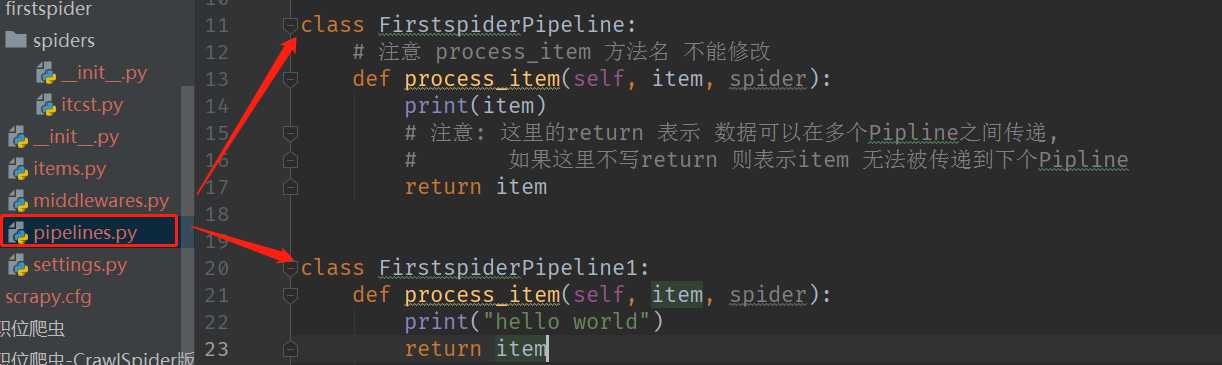
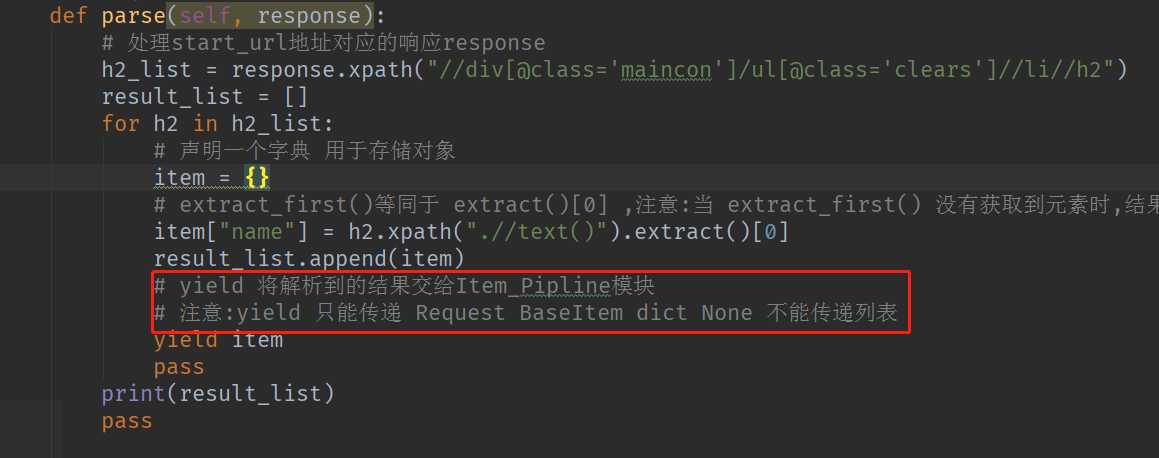
1.爬虫中定义的parse()方法和Pipline中定义的 process_item()方法的方法名不能修改
![]()
![]()
2.Pipline中的return 返回值是将数据传递给下一个Pipline,如果取消return 关键字,则下一个Pipline接受到的数据为None

3.可以定义多个Pipline,多个Pipline的执行循序在settings.py文件中配置 ,配置的数字越小,Pipline越先执行
 4. yield 不能传递列表 只能传递Reqeust BaseItem dict None (原因,传递列表意义不大,数据一次性加载到内存,占用内存较高)
4. yield 不能传递列表 只能传递Reqeust BaseItem dict None (原因,传递列表意义不大,数据一次性加载到内存,占用内存较高)
原文:https://www.cnblogs.com/july-sunny/p/13697144.html