一、了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
0.141
HDFS中更好的校验和。校验和不再存储在并行HDFS文件中,而是由数据节点与块一起直接存储。这对于命名节点更加有效,并且还提高了数据完整性。
管道:MapReduce的C ++ API
Eclipse插件,包括HDFS浏览,作业监视等。
HDFS中的文件修改时间
1.0
安全
HBase(append / hsynch / hflush和安全性)
webhdfs(全面支持安全性)
性能增强了对HBase对本地文件的访问
其他性能增强,错误修复和功能
1.1
从主干向后移植HDFS的许多性能改进
使用SPNEGO而不是Kerberized SSL进行HTTP事务的安全性方面的改进
当然,它也具有与1.0.4版相同的安全修复程序。
1.2
DistCp v2向后移植
JobTracker的Web服务
WebHDFS增强功能
任务放置和副本放置策略接口的扩展
向后移植脱机图像查看器
名称节点在编辑日志损坏的情况下更强大
将节点组级别添加到NetworkTopology
将“未设置”添加到配置API
2.2
YARN-Hadoop的通用资源管理系统,允许MapReduce和其他其他数据处理框架和服务
HDFS的高可用性
HDFS联盟
HDFS快照
NFSv3访问HDFS中的数据
支持在Microsoft Windows上运行Hadoop
在hadoop-1.x上构建的MapReduce应用程序的二进制兼容性
与生态系统中其他项目的大量集成测试
2.3
支持HDFS中的异构存储层次结构。
HDFS数据的内存中缓存,具有集中式管理和管理功能。
通过YARN分布式缓存中的HDFS简化了MapReduce二进制文件的分发。
2.4
支持HDFS中的访问控制列表
对HDFS中的滚动升级的本机支持
为HDFS FSImage使用协议缓冲区以实现平稳的操作升级
HDFS中完整的HTTPS支持
支持YARN ResourceManager的自动故障转移
使用应用程序历史记录服务器和应用程序时间轴服务器增强了对YARN上新应用程序的支持
通过抢占支持YARN CapacityScheduler中的强大SLA
2.5
使用HTTP代理服务器时的身份验证改进。
一个新的Hadoop Metrics接收器,允许直接写入Graphite。
Hadoop兼容文件系统工作规范。
支持POSIX样式的文件系统扩展属性。
OfflineImageViewer通过WebHDFS API浏览fsimage。
NFS网关的可支持性改进和错误修复。
HDFS守护程序的现代化Web UI(HTML5和Javascript)。
YARN的REST API支持提交和杀死应用程序。
YARN的时间轴存储的Kerberos集成。
FairScheduler允许在运行时在任何指定的父队列下创建用户队列。
2.6
HADOOP-10433-密钥管理服务器(测试版)
HADOOP-10607-凭据提供程序(测试版)
异构存储层-第二阶段
HDFS-5682-用于异构存储的应用程序API
HDFS-7228 -SSD存储层
HDFS-6584-支持档案存储
HDFS-6134-透明的静态数据加密(测试版)
HDFS- 2856-在无需root用户访问的情况下操作安全的DataNode
HDFS-6740-热插拔驱动器:支持添加/删除数据节点卷,而无需重新启动数据节点(测试版)
HDFS-6606 -AES支持更快的线路加密
YARN-896-在YARN中支持长期运行的服务
YARN-913-应用程序的服务注册表
YARN-666-支持滚动升级
YARN-556 -ResourceManager的工作保留重启
YARN-1336 -NodeManager的保留容器重新启动
YARN-796-调度期间的支持节点标签
YARN-1051-在Capacity Scheduler(beta)中支持基于时间的资源保留
YARN-1964-支持在Docker容器中本地运行应用程序(alpha)
2.7
此版本放弃了对JDK6运行时的支持,并且仅与JDK 7+一起使用。
此版本尚未准备好用于生产。关键问题正在通过测试和下游采用得到解决。生产用户应等待2.7。1 / 2 .7.2释放。
HADOOP-9629-支持Windows Azure存储-Blob作为Hadoop中的文件系统。
HDFS-3107-支持文件截断
HDFS-7584-支持每种存储类型的配额
HDFS-3689-支持具有可变长度块的文件
YARN-3100-使YARN授权可插入
YARN-1492 -YARN本地化资源的自动共享,全局缓存(测试版)
MAPREDUCE-5583-能够限制作业的正在运行的Map / Reduce任务
MAPREDUCE-4815-对于具有许多输出文件的超大型作业,可以加快FileOutputCommitter的速度。
2.8
支持异步呼叫重试和故障转移,可在重试工作中用于异步DFS实现。
可以通过通用的servlet过滤器为UI提供跨框架脚本(XFS)防护。
S3A改进:增加了插入任何AWSCredentialsProvider的功能,除了XML配置文件之外,还支持从hadoop凭据提供程序API读取s3a凭据,支持Amazon STS临时凭据
WASB的改进:添加了附加API支持
Build增强功能:将开发支持替换为Yetus的包装,提供基于docker的解决方案来设置构建环境,删除CHANGES.txt并重新制作更改日志和发行说明。
添加对LDAP组映射服务的posixGroups支持。
支持与Azure数据湖(ADL)集成,作为与Hadoop兼容的替代文件系统。
WebHDFS增强功能:在WebHDFS中集成CSRF预防过滤器,在WebHDFS中支持OAuth2,通过WebHDFS禁用/允许快照
允许长时间运行的Balancer使用keytab登录
添加ReverseXML处理器,该处理器从XML文件重建fsimage。这将使创建fsimage进行测试变得容易,并且在损坏时手动编辑fsimage。
支持嵌套加密区域
DataNode生命线协议:一种用于报告DataNode活跃度的替代协议。这可以防止NameNode在心跳处理受到延迟的高度过载的群集中错误地将DataNode标记为陈旧或死机。
将HDFS操作的调用者上下文记录到审核日志中
一个新的Datanode命令,用于驱逐写入器,该命令在缓慢的写入器阻止数据节点退役时很有用。
Windows中的NodeManager CPU资源监视。
NM关闭更加顺畅:NM将立即注销到RM,而不是等待超时成为LOST(如果未启用NM工作保留)。
添加了在AM尝试卡住的情况下使特定AM尝试失败的功能。
YARN审核日志中的CallerContext支持。
ATS版本控制支持:一种新的配置,用于指示时间轴服务版本。
允许节点标签在提交MR作业时被指定
添加新工具以将汇总的日志合并到HAR文件中
2.9
HADOOP资源估计器。有关更多详细信息,请参见用户文档。
基于HDFS路由器的联盟。有关更多详细信息,请参见用户文档。
YARN时间轴服务v.2。有关更多详细信息,请参见用户文档。
yarn联合会。有关更多详细信息,请参见用户文档。
机会容器。有关更多详细信息,请参见用户文档。
YARN Web UI v.2。有关更多详细信息,请参见用户文档。
通过API更改队列配置(仅在Capacity Scheduler上受支持)。有关更多详细信息,请参见用户文档。
更新已分配/正在运行的容器的资源和执行类型(仅在Capacity Scheduler上受支持)。有关更多详细信息,请参见用户文档。
3.0
最低要求的Java版本从Java 7增加到Java 8
现在已针对Java 8的运行时版本编译了所有Hadoop JAR。仍在使用Java 7或更低版??本的用户必须升级到Java 8。
支持HDFS中的擦除编码
与复制相比,擦除编码是一种持久存储数据的方法,可节省大量空间。与标准HDFS复制的3倍开销相比,像Reed-Solomon(10,4)这样的标准编码的空间开销为1.4倍。
由于擦除编码在重建期间会带来额外的开销,并且大部分执行远程读取,因此传统上已将其用于存储较冷,访问频率较低的数据。用户在部署此功能时应考虑擦除编码的网络和CPU开销。
HDFS删除编码文档中提供了更多详细信息。
我们正在介绍YARN时间轴服务主要版本:v.2的早期预览(alpha 2)。YARN Timeline Service v.2解决了两个主要挑战:提高Timeline Service的可伸缩性和可靠性,以及通过引入流和聚合来增强可用性。
提供了YARN Timeline Service v.2 alpha 2,以便用户和开发人员可以对其进行测试并提供反馈和建议,以使其可以替代Timeline Servicev.1.x。仅应以测试能力使用。
支持两个以上的NameNode。
HDFS NameNode高可用性的初始实现是为单个活动NameNode和单个Standby NameNode提供的。
S3Guard:S3A文件系统客户端的一致性和元数据缓存
HADOOP-13345向Amazon S3存储的S3A客户端添加了一项可选功能:能够将DynamoDB表用作文件和目录元数据的快速且一致的存储。
基于HDFS路由器的联合
Capacity Scheduler队列配置的基于API的配置
YARN资源模型已被通用化,以支持用户定义的CPU和内存以外的可计数资源类型。例如,集群管理员可以定义资源,例如GPU,软件许可证或本地连接的存储。然后可以根据这些资源的可用性来调度YARN任务。
3.1
Yarn Service框架提供了一流的支持和API,以在YARN中本地托管长期运行的服务。
YARN上一流的GPU调度和隔离(适用于docker / non-docker容器)。
YARN上一流的FPGA调度和隔离(适用于docker / non-docker容器)。
支持管理员为队列指定绝对资源(X内存,Y VCore,Z GPU等),而不是提供基于百分比的值。这为管理员提供了更好的控制,以配置给定队列所需的资源量。
提供的存储允许将HDFS外部存储的数据映射到HDFS并从中寻址。通过将新的存储类型PROVIDED引入DataNode中的媒体集,它基于异构存储而构建。。
3.2
YARN中的节点属性支持
节点属性有助于根据节点的属性在节点上标记多个标签,并支持基于这些标签的表达来放置容器。
节点属性文档中提供了更多详细信息。
Hadoop Submarine使数据工程师可以在数据驻留的同一Hadoop YARN集群上轻松开发,训练和部署深度学习模型(在TensorFlow中)。
支持增强的S3A连接器,包括对受限制的AWS S3和DynamoDB IO的更好的弹性。
通过YARN本机服务API和CLI支持长期运行的容器的就地无缝升级。
YARN服务升级文档中提供了更多详细信息。
二、Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
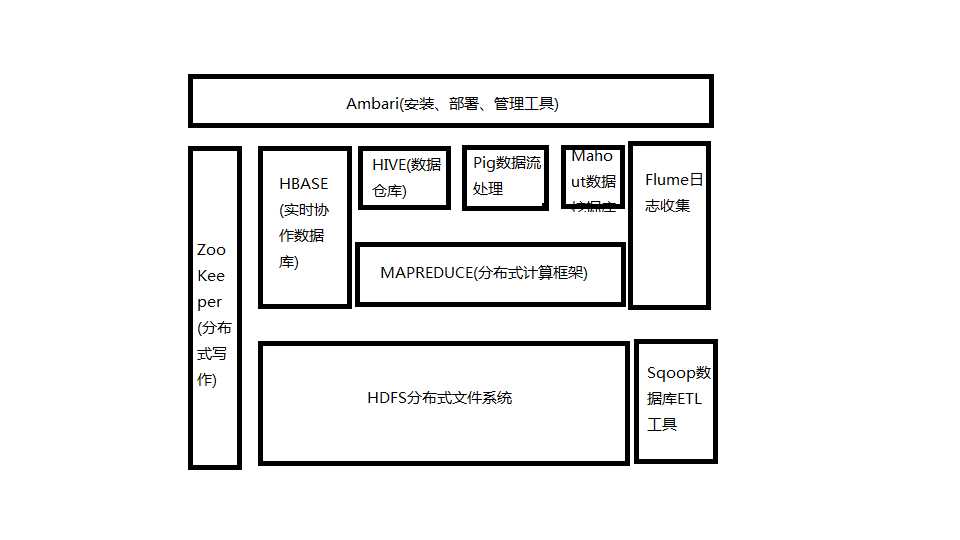
1.HDFS
Hadoop分布式文件系统HDFS是针对谷歌分布式文件系统(Google File System,GFS)的开源实现,它是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
HDFS具有很好的容错能力,并且兼容廉价的硬件设备,因此,可以以较低的成本利用现有机器实现大流量和大数据量的读写。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
用户在使用 HDFS 时,仍然可以像在普通文件系统中那样,使用文件名去存储和访问文件。
实际上,在系统内部,一个文件会被切分成若干个数据块,这些数据块被分布存储到若干个数据节点上。
MapReduce 是一种分布式并行编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。MapReduce极大方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算。在MapReduce中,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的小数据块,这些小数据块可以被多个Map任务并行处理。MapReduce框架会为每个Map任务输入一个数据子集,Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后结果,并写入分布式文件系统。
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
HBase利用MapReduce来处理HBase中的海量数据,实现高性能计算;利用 Zookeeper 作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力,当然,HBase也可以在单机模式下使用,直接使用本地文件系统而不用 HDFS 作为底层数据存储方式,不过,为了提高数据可靠性和系统的健壮性,发挥HBase处理大量数据等功能,一般都使用HDFS作为HBase的底层数据存储方式。此外,为了方便在HBase上进行数据处理,Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
Hive的学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语言——HiveQL,可以通过HiveQL语句快速实现简单的MapReduce统计,Hive自身可以自动将HiveQL语句快速转换成MapReduce任务进行运行,而不必开发专门的MapReduce应用程序,因而十分适合数据仓库的统计分析。
Flume 是 Cloudera 公司开发的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(比如导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
7.Ambari™:基于Web的工具,用于供应,管理和监视Apache Hadoop集群,其中包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个仪表板,用于查看集群健康状况(例如热图)以及以可视方式查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
8.Mahout™:可扩展的机器学习和数据挖掘库
9.Pig™:用于并行计算的高级数据流语言和执行框架
10.ZooKeeper™:针对分布式应用程序的高性能协调服务
三、官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
支持GNU / Linux作为开发和生产平台。Hadoop在具有2000个节点的GNU / Linux集群上得到了证明。
Windows也是受支持的平台,但是以下步骤仅适用于Linux。要在Windows上设置Hadoop,请参wiki页面
Linux所需的软件包括:
必须安装Java™。HadoopJavaVersions中描述了推荐的Java版本。
如果要使用可选的启动和停止脚本,则必须安装ssh并且必须运行sshd才能使用管理远程Hadoop守护程序的Hadoop脚本。另外,建议也安装pdsh以便更好地进行ssh资源管理。
如果您的群集没有必需的软件,则需要安装它。
例如在Ubuntu Linux上:
$ sudo apt-get install ssh $ sudo apt-get install pdsh
要获得Hadoop发行版,请从Apache下载镜像之一下载最新的稳定版本。
原文:https://www.cnblogs.com/LZK678/p/13689580.html