String:字符串,使用一对""引起来表示。
String 声明为 final 的,不可被继承。
String:
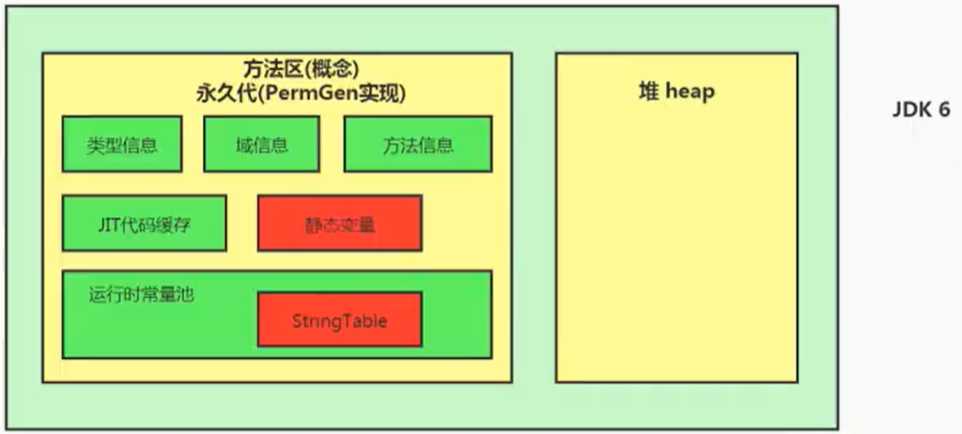
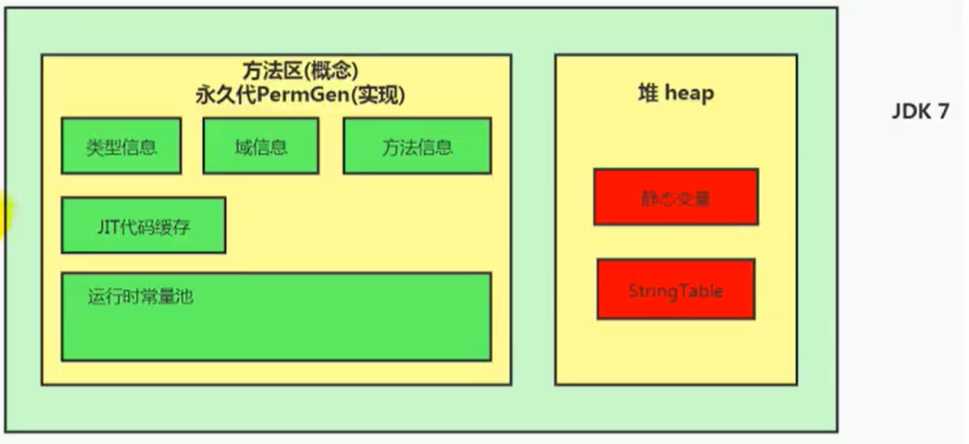
String 在 jdk8 及以前内部定义了 final char[] value 用于存储字符串数据,jdk9 时改为 final byte[] value 。
http://openjdk.java.netjeps/254
Motivation:
The current implementation of the Stirng class stores characters in a char array, using two bytes (sixteen bits) for each character. Data gathered from many different applications indicates that strings are a major component of heap usage and, moreover, that most String objects contain only Latin-1 characters. Such characters require only one byte of storage, hence half of the space in the internal char arrays of such String objects is going unused.
Description:
We propose to change the internal representation of the String class from a UTF-16 char array to a byte array plus an encoding-flag field. The new String class will store characters encoded either as ISO-8859-1/Latin-1 (one byte per character), or as UTF-16 (two bytes per charater), based upon the contents of the string. The encoding flag will indicate which encoding is used.
String 代表不可变的字符序列,简称:不可变性。
通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中。
例子:
public class StringExer {
String str = new String("good");
char[] ch = {‘t‘, ‘e‘,‘s‘,‘t‘};
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = ‘b‘;
}
public static void main(String[] agrs) {
StringExer ex = new StringExer();
ex.change(ex.str, ex.ch);
System.out.println(ex.str); // 输出 good
System.out.println(ex.ch); // 输出 best
}
}
上述例子中,ex.str 传入 ex.change() 函数时,将 ex.str 引用String对象“good”的地址值传给了 change() 函数的str参数,此时 str 参数和 ex.str 都指向了 String 对象 ”good“;之后 str 参数指向了字面量”test ok“,而 ex.str 依旧保存着指向 String 类 ”good“ 的地址,故 ex.str 依旧输出 “good” 。
字符串常量池中是不会存储相同内容的字符串的。
String的String Pool是一个固定大小的 Hashtable,默认值大小长度是1009。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用 String.intern 时性能会大幅下降。
使用-XX:StringTableSize可以设置StringTable的长度。
在Java语言中有8种基本数据类型和一种比较特殊的类型String。这些类型为了使它们在运行过程中速度更快、更节省内存,都提供了一种常量池的概念。
常量池就类似一个Java系统级别提供的缓存。8种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种:
直接使用双引号声明出来String对象会直接存储在常量池中。
如果不是用双引号声明的String对象,可以使用String提供的 intern() 方法。
Java6 及以前,字符串常量池存放在永久代。
Java7 中,Oracle 的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到Java堆内。
Java8 元空间,字符串常量在堆中。
public class StringTest1 {
public static void main(String[] args) {
System.out.println(); // 执行到这一步前,内存中有2134个String变量
System.out.println("1"); //2135
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10"); //2144
System.out.println(); // 2145
System.out.println("1"); // 2145
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10"); // 2145
}
}
Java 语言规范里要求完全相同的字符串字面量,应该包含同样的 Unicode 字符序列(包含同一份码点序列的常量),并且必须是指向同一个 String 类实例。
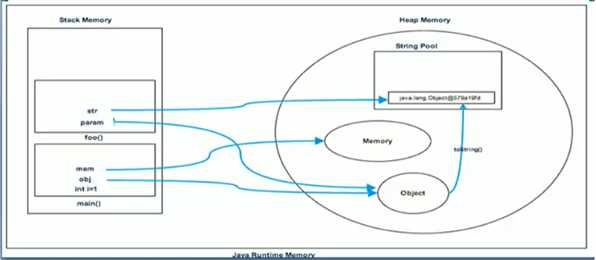
public class Memory {
public static void main(String[] args) { //line 1
int i = 1; //line 2
Object obj = new Object(); //line 3
Memory mem = new Memory(); //line 4
mem.foo(obj); //line 5
} //line 9
private void foo(Object param) { //line 6
String str = param.toString(); //line 7
System.out.println(str);
} //line 8
}
内存分配如下图:
public class StringTest5 {
@Test
public void test1() {
String s1 = "a" + "b" + "c";
String s2 = "abc"; // "abc"一定是放在字符串常量池中,将此地址赋给s2
/*
* 最终,Java编译成.class,再执行.class
* String s1 = "abc";
* String s2 = "abc";
*/
System.out.println(s1 == s2); // 返回 true
System.out.println(s1.equals(s2)); // true
}
@Test
public void test2() {
String s1 = "javaEE";
String s2 = "hadoop";
// 如果拼接符号的前后出现了变量,则相当于在堆空间中 new String(),具体的内容为拼接的结果。
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop"; // 编译期优化
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); //true
System.out.println(s3 == s5); //false
System.out.println(s3 == s6); //false
System.out.println(s3 == s7); //false
System.out.println(s5 == s6); //false
System.out.println(s5 == s7); //false
System.out.println(s6 == s7); //false
/*
* intern():判断字符串常量池中是否存在 javaEEhadoop值,如果存在,则返回常量池中 javaEEhadoop 的地址
* 如果字符串常量池中不存在javaEEhadoop,则在常量池中加载一份javaEEhadoop,并返回此对象的地址。
*/
String s8 = s6.intern();
System.out.println(s3 == s8); //true
}
@Test
public void test3() {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
/*
如下的s1 + s2的执行细节:(变量 s 是临时定义的)
1. StringBuilder s = new StringBuilder();
2. s.append("a")
3. s.append("b")
4. s.toStirng() ---> 约等于 new String("ab")
补充:在jdk5.0之后使用的是 StringBuilder,在 jdk5.0 之前使用的是 StringBuffer
*/
String s4 = s1 + s2;
System.out.println(s3 == s4); //false
}
/*
1. 字符串拼接操作不一定使用的是 StringBuilder
如果拼接符号左右两边都是字符串常量或常量引用,则仍然使用编译期优化,即非 StringBuilder 的方式。
2. 针对于 final 修饰类、方法、基本数据类型、引用数据类型的量的结构时,能使用上 final 的时候建议使用上
*/
@Test
public void test4() {
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4); //true
}
}
通过 StringBuilder 的 append() 的方式添加字符串的效率要远高于 String 的字符串拼接方式!
详情:
改进空间:在实际开发中,如果基本确定要前前后后添加的字符串长度不高于某个限定值 highLevel 的情况下,建议使用构造器 StringBuilder s = new StringBuilder(highLevel); // new char[highLevel]
/*
体会执行效率:通过 StringBuilder 的 append() 的方式添加字符串的效率要远高于 String 的字符串拼接方式!
详情:
1. StringBuilder 的 append() 的方式:自始至终只创建过一个 StringBuilder 的对象
使用String 的字符串拼接方式:创建过多个 StringBuilder 和 String 的对象
2. 使用String 的字符串拼接方式:内存中由于创建了较多的 StringBuilder 和 String 的对象,内存占用更大;如果进行GC,需要花费额外的时间。
改进空间:在实际开发中,如果基本确定要前前后后添加的字符串长度不高于某个限定值 highLevel 的情况下,
建议使用构造器 StringBuilder s = new StringBuilder(highLevel); // new char[highLevel]
*/
@Test
public void test5() {
long start = System.currentTimeMillis();
// method1(100000); // 需要时间 4014 毫秒
method2(100000) // 7 毫秒
long end = System.currentTimeMillis();
}
public void method1(int highLevel) {
String src = "";
for (int i = 0; i < highLevel; i++) {
src = src + "a"; // 每次循环都会创建一个 StringBuilder、String
}
}
public void method2(int highLevel) {
// 只需要创建一个StringBuilder
StringBuilder src = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
src.append("a");
}
}
如果不是用双引号声明的String对象,可以使用 String 提供的 intern 方法:intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
也就是说,如果在任意字符串上调用 String.intern 方法,那么其返回结果所指向的那个类实例,必须和直接以常量形式出现的字符串实例完全相同。因此,下列表达式的值必定是 true:
通俗点讲,Interned String 就是确保字符串在内存里只有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度。注意,这个值会被存放在字符串内部池(String Intern Pool)。
如何保证变量s指向的是字符串常量池中的数据呢?
public class StringNewTest {
public static void main(String[] args) {
String str = new String("ab");
// String str = new String("a") + new String("b");
}
}
上述程序的字节码:
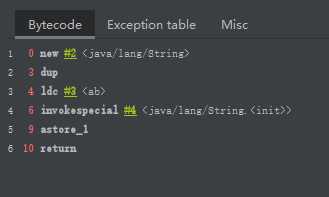
从字节码中可以看出创建了两个对象:
public class StringNewTest {
public static void main(String[] args) {
// String str = new String("ab");
String str = new String("a") + new String("b");
}
}
上述程序的字节码:
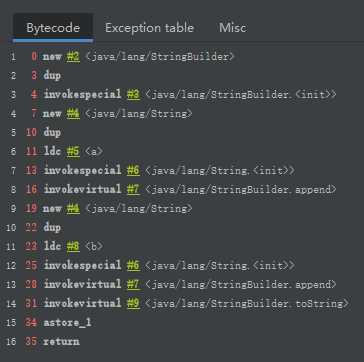
StringBuilder 的 toString() 的字节码:
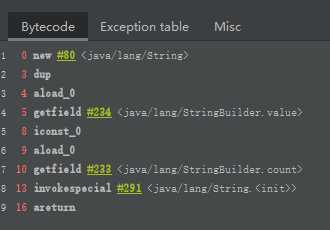
从字节码看出,toString() 的调用,会new 一个 String 类,且不会将字符串放入字符串常量池中,即在字符串常量池中,没有生成 "ab"。
故有:
public class StringIntern1 {
public static void main(String[] args) {
String s = new String("1");
s.intern(); // 调用此方法之前,字符串常量池中已经存在 "1" 了。
String s2 = "1";
System.out.println(s == s2);//输出: jdk6: false jdk7/8: false
String s3 = new String("1") + new String("1"); // s3变量记录的地址为:new String("11")
//执行完上一行代码以后,字符串常量池中还不存在”11“。
s3.intern(); // 在字符串常量池中生成”11“
/*
在jdk6里使用 intern():再常量池里创建了一个新的”11“,也就有新的地址。
在 jdk7 里:并不在常量池中创建新的”11“,而是创建一个指向堆空间中 new String("11") 的地址。
*/
String s4 = "11"; //s4变量记录的地址:使用的是上一行代码执行时,在常量池中生成的”11“的地址
System.out.println(s3 == s4);//jdk6: false jdk7/8: true
}
}
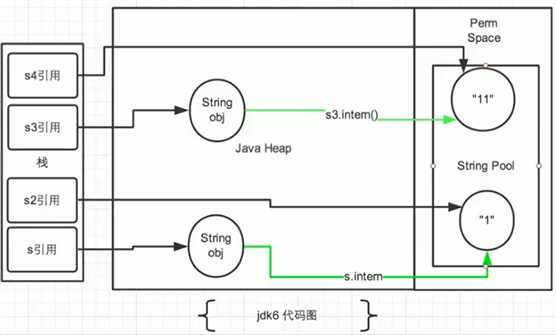
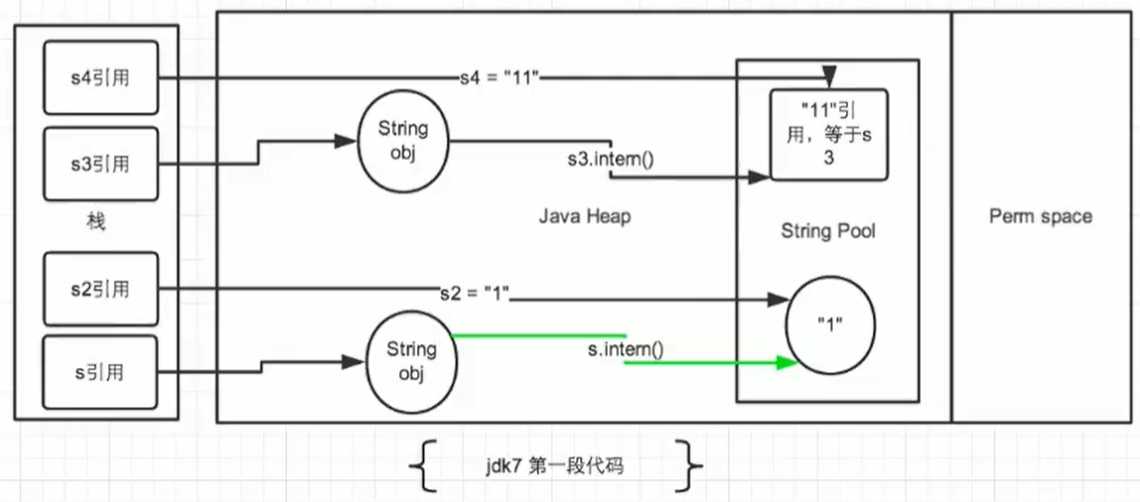
总结String发 intern() 的使用:
public class StringExer1 {
public static void main(String[] args) {
// String x = "ab";
String s = new String("a") + new String("b"); // new String("ab")
// 在上一行代码执行完以后,字符串常量池中并没有”ab“
String s2 = s.intern(); // jdk6中:在串池中创建一个字符串”ab“
// jdk8中:串池中没有创建字符串”ab“,而是创建一个引用,指向new String("ab")
System.out.println(s2 == "ab"); //jdk6: true jdk8: true
System.out.println(s == "ab"); //jdk6: false jdk8: true
}
}
如果上述代码中 String x = "ab" 取消注释,那么 System.out.println(s == "ab") 在 jdk6 和 jdk8 中的结果都是 false。
public class StringExer2 {
public static void main(String[] args) {
String s1 = new String("ab"); //执行完以后,在字符串常量池中会生成”ab”
// String s1 = new String("a") + new String("b"); //执行完以后,不会在字符串常量池中会生成”ab”
s1.intern();
String s2 = "ab";
System.out.println(s1 == s2);
}
}
public class StringIntern2 {
static final int MAX_COUNT = 1000 * 10000;
static final String[] arr = new String[MAX_COUNT];
public static void main(String[] agrs) {
Integer[] data = new Integer[]{1,2,3,4,5,6,7,8,9,10};
long start = System.currentTimeMillis();
for (int i = 0; i < MAX_COUNT; i++) {
arr[i] = new String(String.valueOf(data[i % data.length]));
// arr[i] = new String(String.valueOf(data[i % data.length])).intern();
}
long end = System.currentTimeMillis();
System.out.println("花费时间为:" + (end - start));
try [
Thread.sleep(1000000);
] catch (InterruptedException e) {
e.printlnStackTrace();
}
System.gc();
}
}
结论:对于程序中大量存在的字符串,尤其是其中存在很多重复字符串时,使用 intern() 可以节省内存空间。
大的网站平台,需要内存中存储大量的字符串。比如社交网站,很多人都存储:北京市、海淀区等信息。这时候如果字符串都调用 intern() 方法,就会明显降低内存的大小。
背景:堆许多java应用(有大的也有小的)做的测试得出以下结果:
许多大规模的Java应用的瓶颈在于内存,测试表明,在这些类型的应用里面,java堆中存活的数据集合差不多25%是String对象。更进一步,这里面差不多一半String对象是重复的,重复的意思是说,string1.equals(string2)=true。堆上存在重复的String对象必然是一种内存的浪费。这个项目将在G1垃圾收集器中实现自动持续对重复的String对象进行去重,这样就能避免浪费内存。
实现:
命令行选项:
原文:https://www.cnblogs.com/pensieve/p/13657358.html