


问题 2:前台归档策略坑能会经常变化,导致数据仓库归档算法也要随之变化,维护和沟通成本较高;
总结:此方案使用于前台归档策略逻辑较为简单,且变更不频繁的情况;
通过数据库 binlog 日志解析获取每日增量;
通过增量的 merge 全量的方式获取最新的全量数据;
使用增量日志的删除标志,作为前台数据归档的标志,通过此标志对数据仓库的数据进行归档;
总结:不需要关注前台归档策略,简单异性,但对前台应用的要求是,数据库的物理删除只有在归档时才执行,应用中的删除只是逻辑删除;


特点:保留历史数据,维度值变化前的事实和过去的维度值关联,纬度值变化后的事实和当前的纬度值关联;
问题:不能将变化前后记录的事实,归一为变化前的维度或者归一为变化后的维度;
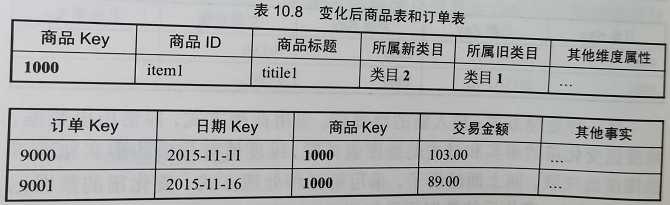
解释:因为插入新的维度行,相当于给维表添加新的商品,与维度属性变化前的商品,算做两种商品,那么事实表中也会添加新种类商品的数据;其实 “两种“ 商品只是某一属性或某几个属性不一样而已,其它属性完全一样,如果想对 “两种” 商品的历史数据进行统一统计时,此方法不便实现;


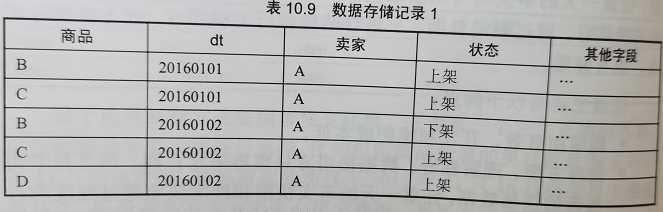
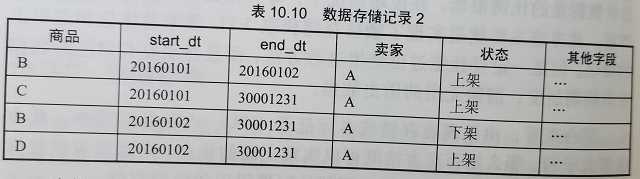


1 天为最小分区区间,31 天最长分区区间,1 个月中可能有:30 x 31 / 2 = 465 个分区;(则一年最多可能产生的分区数:465 x 12 = 5580 )
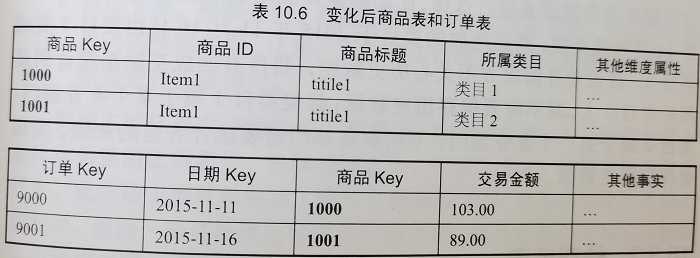
1002 产生且 1003 死亡记录:采用历史拉链存储方式,从第 2 天到第 3 天的存储数据;
1001 产生且 1031 死亡记录:采用历史拉链存储方式,从第 1 天到第 31 天的存储数据;
疑问:每月 1 日的全量数据是什么?
在做极限存储前有一个全量存储表,仅保留最近一段时间的全量分区数据,历史数据通过映射方式关联到极限存储表;(用户只访问全量存储表,通过映射,关联到极限存储表,得到最新的变更的全量数据;)(极限存储表对用户是不可见的)
对变化频率较高的字段需要过滤;
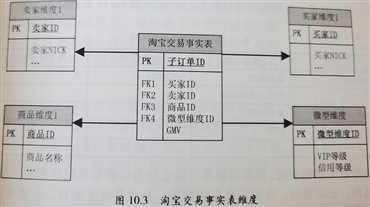
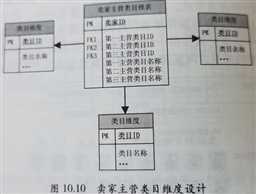
业务难题:由于很多数据仓库系统和商业智能工具不支持递归 SQL,并且用户使用递归 SQL 的成本较高,所以在维度模型中,需要对递归层次结构进行处理:

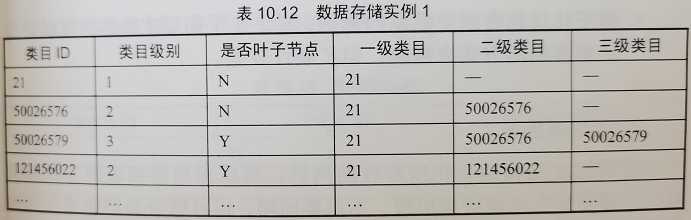
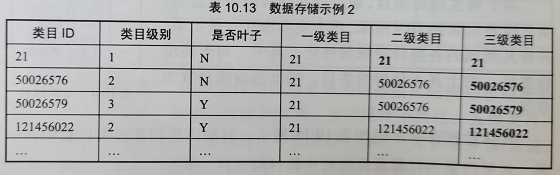
桥接表:

解决的问题:
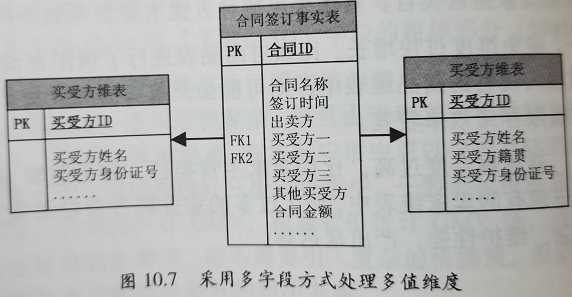
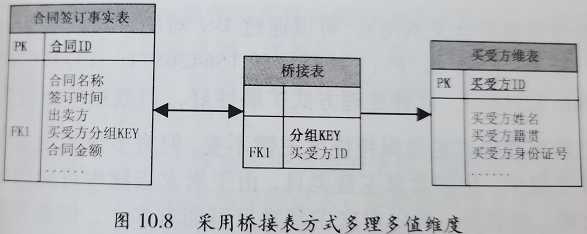

根据具体情况进行选择:
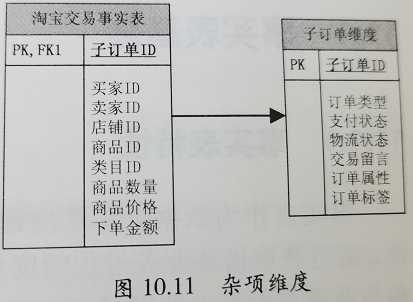
原文:https://www.cnblogs.com/volcao/p/13604853.html