
keys * 查询当前库的所有键exists <key> 判断某个键是否存在type <key> 查看键的类型del <key> 删除某个键expire <key> <seconds> 为键值设置过期时间,单位秒ttl <key> 查看还有多少秒过期,-1 代表永不过期,-2 表示已过期dbsize 查看当前数据库的 key 的数量flushdb 清空当前库flushall 通杀所有库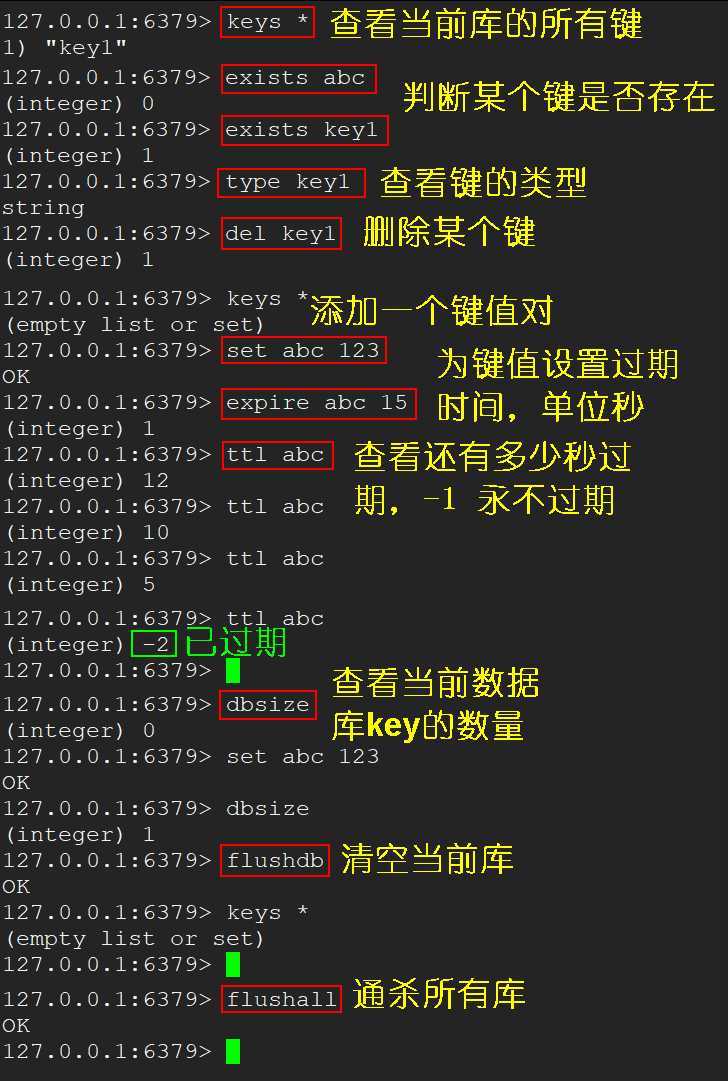
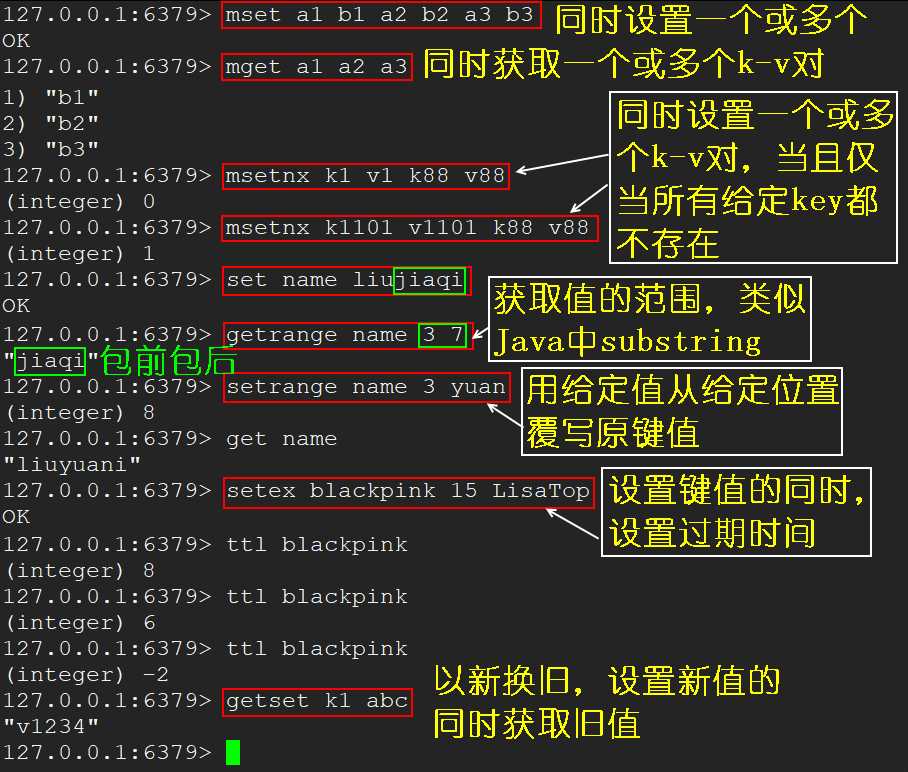
get <key> 查询对应键值set <key> <value> 添加键值对append <key> <value> 将给定的 value 追加到原值的末尾strlen <key> 获取值的长度setnx <key> <value> 只有在 key 不存在时设置 key 的值incr <key> 将 key 中储存的数字值增 1,注意只能对数字值操作,如果为空,新增值为 1decr <key> 将 key 中储存的数字值减 1,注意只能对数字值操作,如果为空,新增值为 -1incrby / decrby <key> <步长> 将 key 中储存的数字值增减,自定义步长mset <key1> <value1> [<key2> <value2> ...] 同时设置 1 个或多个 key-value 对mget <key1> [<key2> ...] 同时获取 1 个或多个 valuemsetnx <key1> <value1> [<key2> <value2> ...] 同时设置 1 个或多个 key-value 对,当且仅当所有给定 key 都不存在getrange <key> <起始位置> <结束位置> 获取指定范围的值,类似 Java 的 substring,但这里包前也包后setrange <key> <起始位置> <value> 用 value 覆写 key 所存储的字符串值,从起始位置开始setex <key> <过期时间> <value> 设置键值的同时,设置过期时间,单位秒getset <key> <value> 以新换旧,设置了新值的同时获取旧值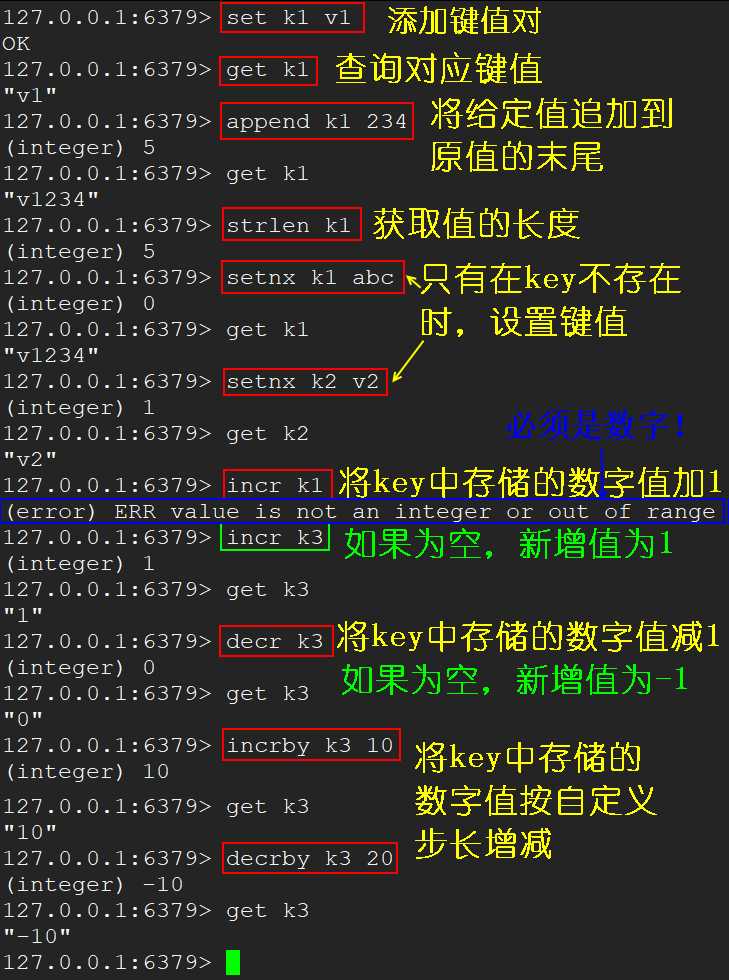

i++ 是否是原子操作?不是
lpush/rpush <key> <value1> <value2> ... 从左/右边插入 1 个或多个值lpop/rpop <key> 从左/右边吐出一个值(值在键在,值光键亡)rpoplpush <key1> <key2> 从 key1 列表右边吐出一个值插到 key2 列表左边lrange <key> <start> <stop> 按照索引下标获得元素(从左到右)lindex <key> <index> 按照索引下标获得元素(从左到右)llen <key> 获得列表长度linsert <key> before|after <value> <newValue> 在 value 的 前|后面 插入 newValuelrem <key> <n> <value> 删除 n 个 value
n > 0 从左往右删 n 个n < 0 从右往左删 n 个n = 0 删除全部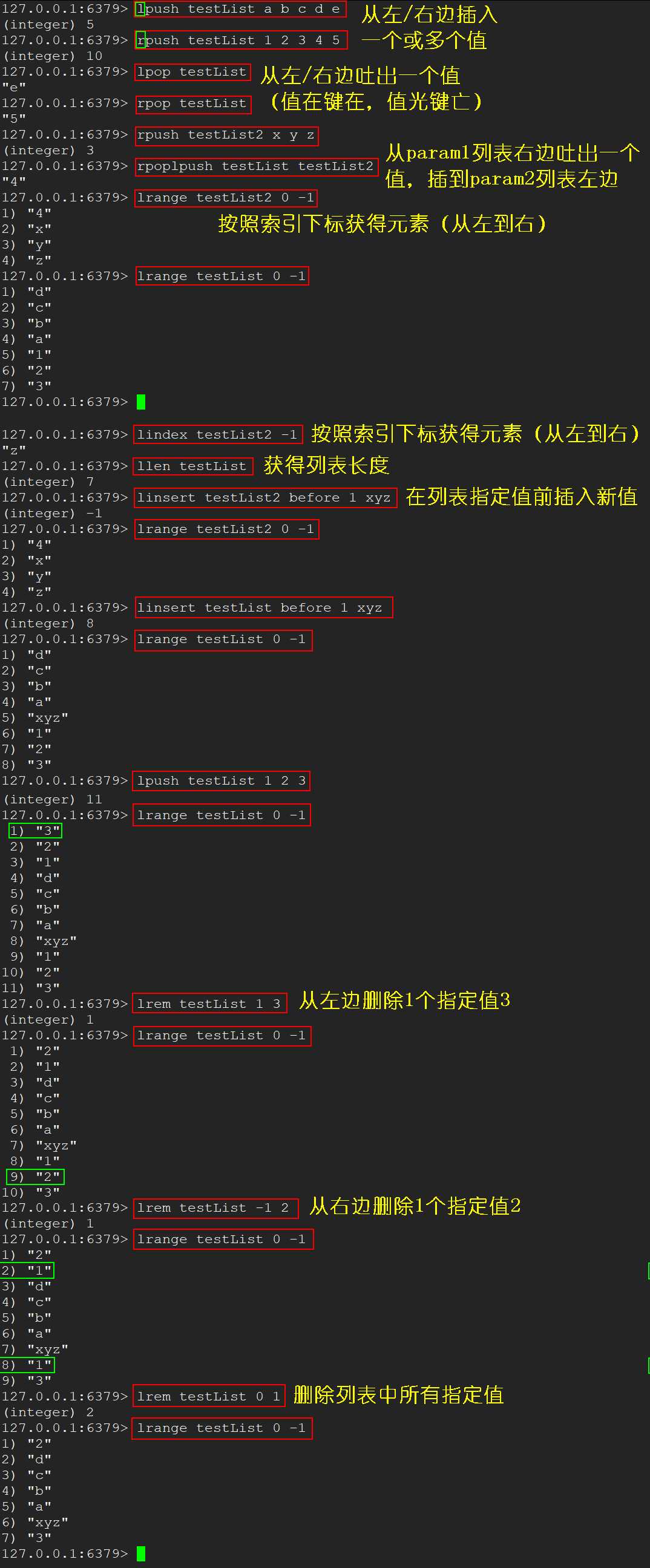
sadd <key> <value1> [<value2> ...] 将 1 个或多个 value 加入到集合 key 当中,已经存在于集合的 value 元素将被忽略smembers <key> 取出该集合的所有值sismember <key> <value> 判断集合 key 中是否含有指定 value 值;有则返回 1,没有返回 0scard <key> 返回集合 key 的元素个数srem <key> <value1> [<value2> ...] 删除集合 key 中指定的 valuespop <key> 随机从该集合中吐出一个值srandmember <key> <n> 随机从该集合中取出 n 个值,不会从集合中删除sinter <key1> <key> 返回两个集合的交集元素sunion <key1> <key> 返回两个集合的并集元素sdiff <key1> <key> 返回两个集合的差集元素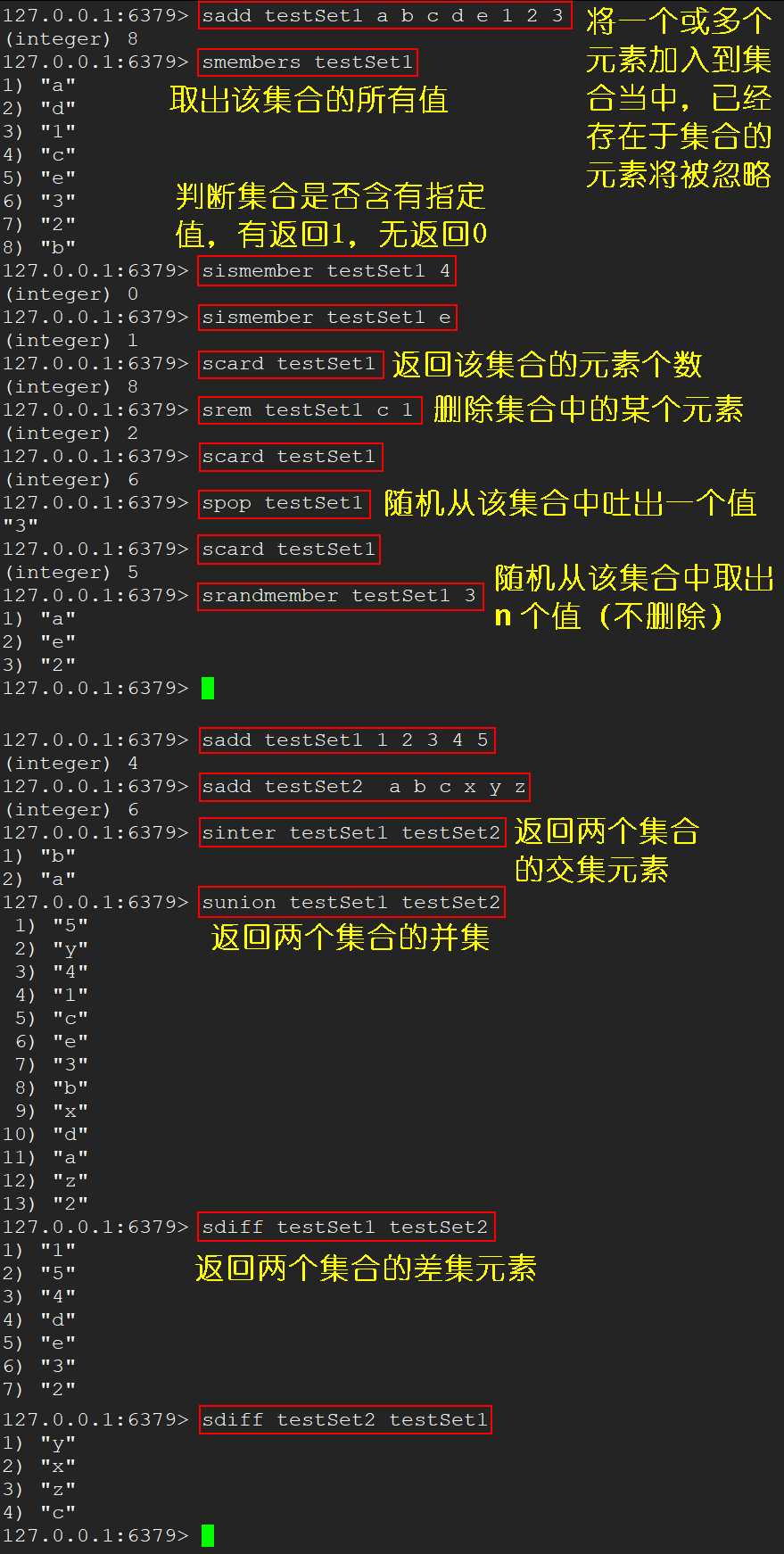
Map<String, String>1. 用户 ID 为 key,value 为 JavaBean 序列化后的字符串
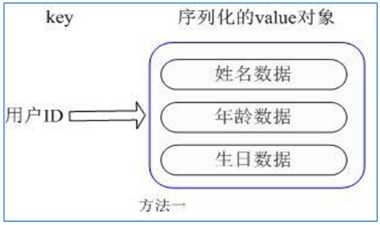
缺点:每次修改用户的某个属性需要,先反序列化改好后再序列化回去。开销较大
2. {用户ID + 属性名} 作为 key,属性值作为 value
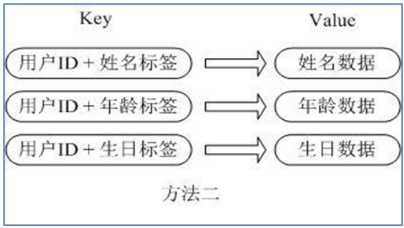
缺点:用户 ID 数据冗余
3. 通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
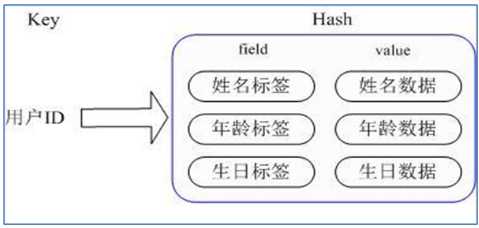
hset <key> <field> <value> 给集合 key 中的键 field 赋值 valuehmset <key> <field1> <value1> [<field2> <value2> ...] 批量设置集合 key 的键值对hget <key> <field> 从集合 key 中取出键 field 对应的 valuehexists <key> <field> 查看集合 key 中,给定 field 是否存在hkeys <key> 列出集合 key 的所有 fieldhvals <key> 列出集合 key 的所有 valuehincrby <key> <field> <increment> 为集合 key 中给定 field 的 value 加上增量hsetnx <key> <field> <value> 将集合 key 的 field 值设为 value,当且仅当 field 不存在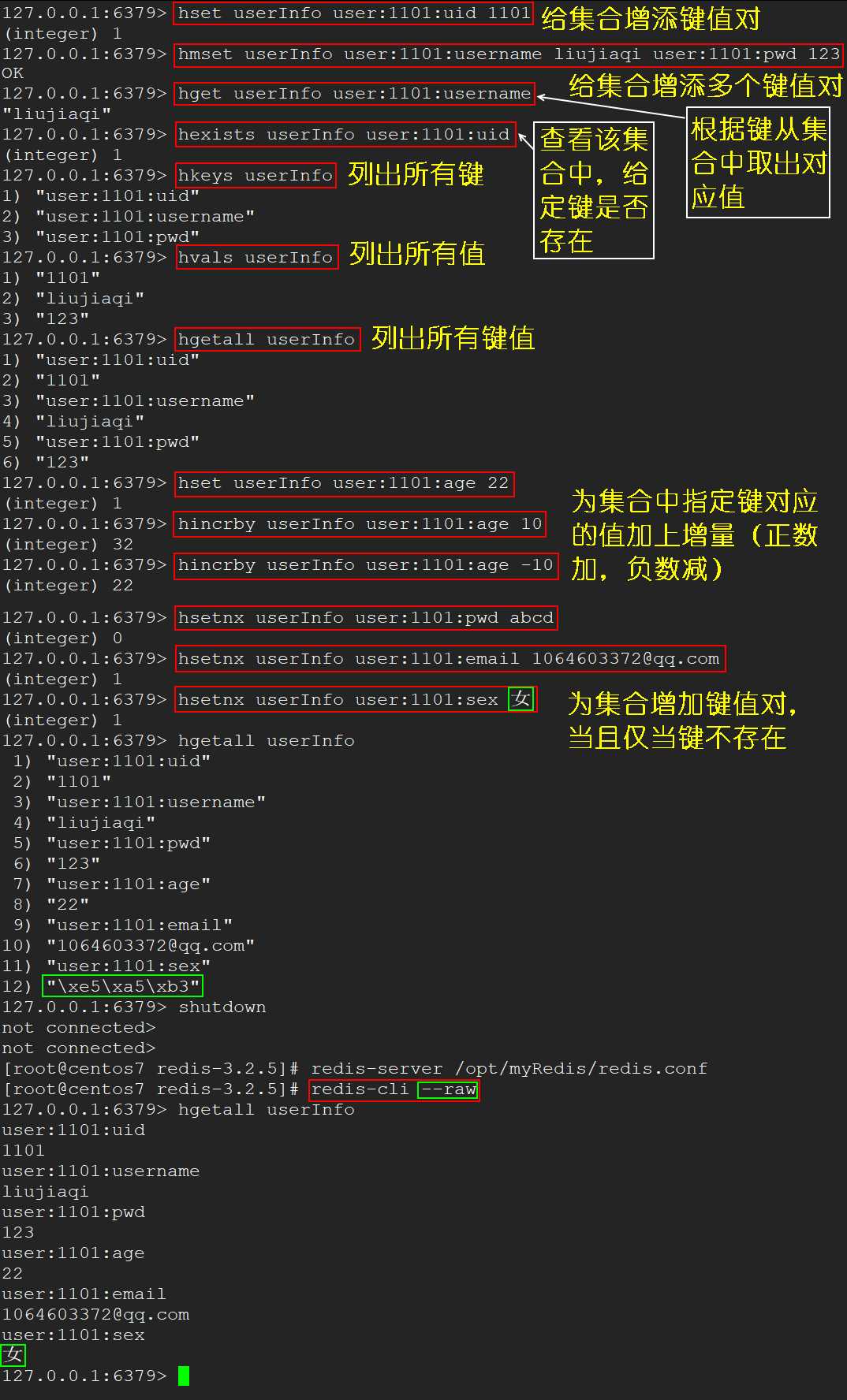
zadd <key> <score1> <value1> [<score2> <value2> ...] 将 1 个或多个 value 及其 score 值加入到有序集 key 中zrange <key> <start <stop> [withscores]
<start> 和 <stop> 之间的元素withscores 的,可以让 score 和 value 一起返回到结果集zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key max min [withscores] [limit offset count] 同上,改为降序排列zincrby <key> <increment> <value> 为 value 的 score 加上指定增量zrem <key> <value> 删除该集合下,指定值的元素zcount <key> <min> <max> 统计该集合中指定分数区间内的元素个数zrank <key> <value> 返回 value 在集合中的排名,从 0 开始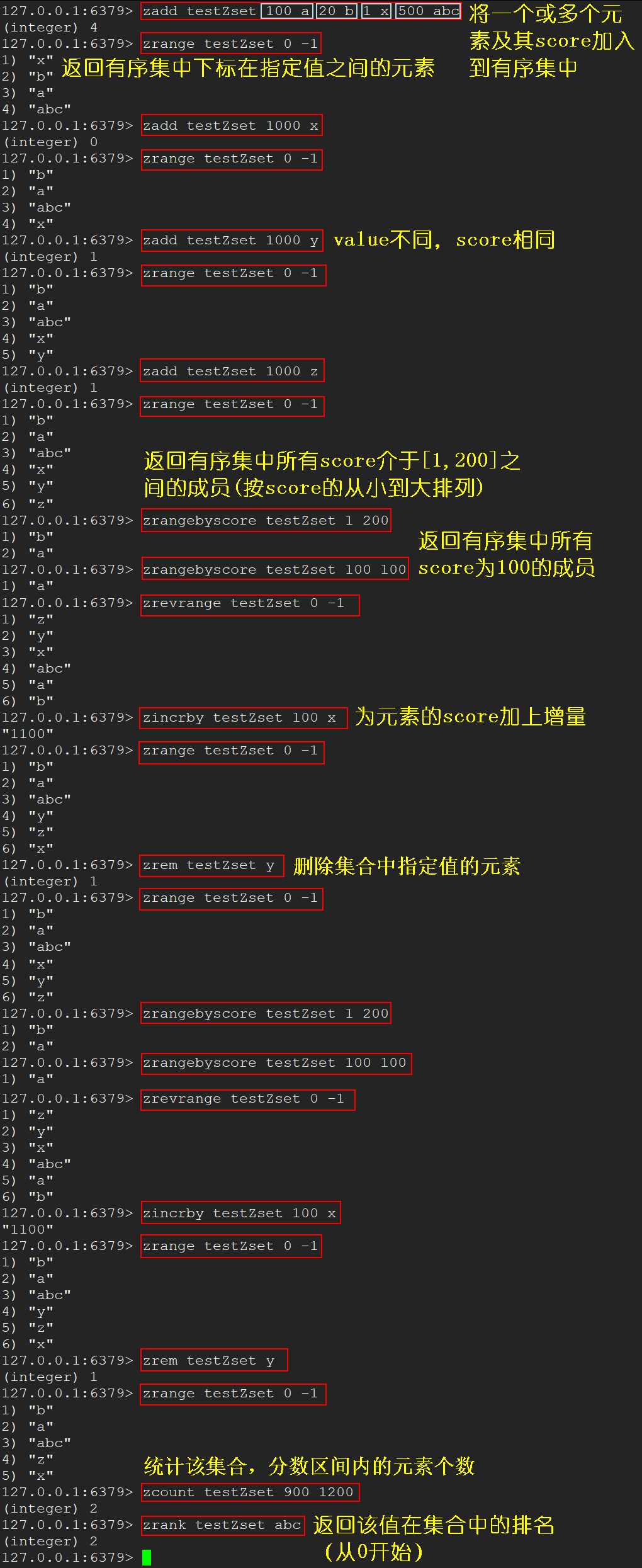
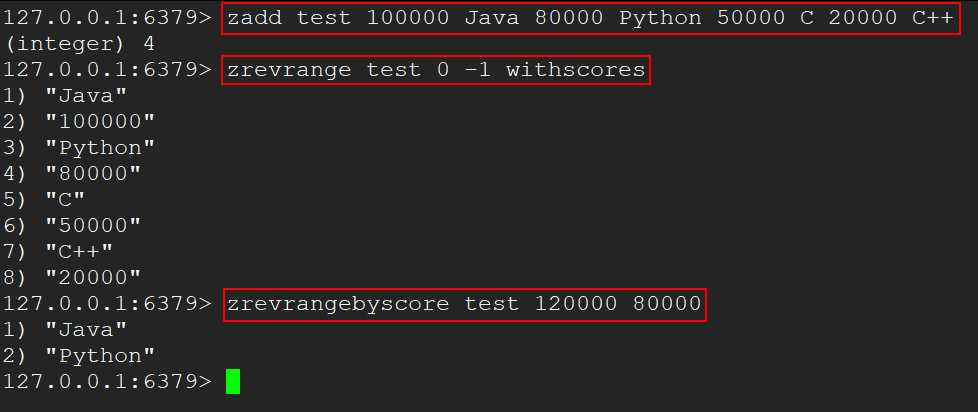
如何利用 zset 实现一个文章访问量的排行榜?
原文:https://www.cnblogs.com/liujiaqi1101/p/13613185.html