1,Strom特点
进程常驻内存,数据不经过磁盘,在内存中处理,速度非常快,可以达到毫秒(秒)级别
Twitter开源的分布式实时大数据处理框架,最早开源于github
2013年,Storm进入Apache社区进行孵化
2014年9月,晋级成为了Apache顶级项目
国内外各大网站使用,例如雅虎、阿里、百度
2,Storm数据传输
ZMQ(twitter早期产品):ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty:Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
3,Storm可靠性
异常处理
消息可靠性保障机制(ACK)
4,Strom和其他框架的对比
生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止(区别于MapReduce当中的Job,MR当中的Job在计算执行完成就会终止)
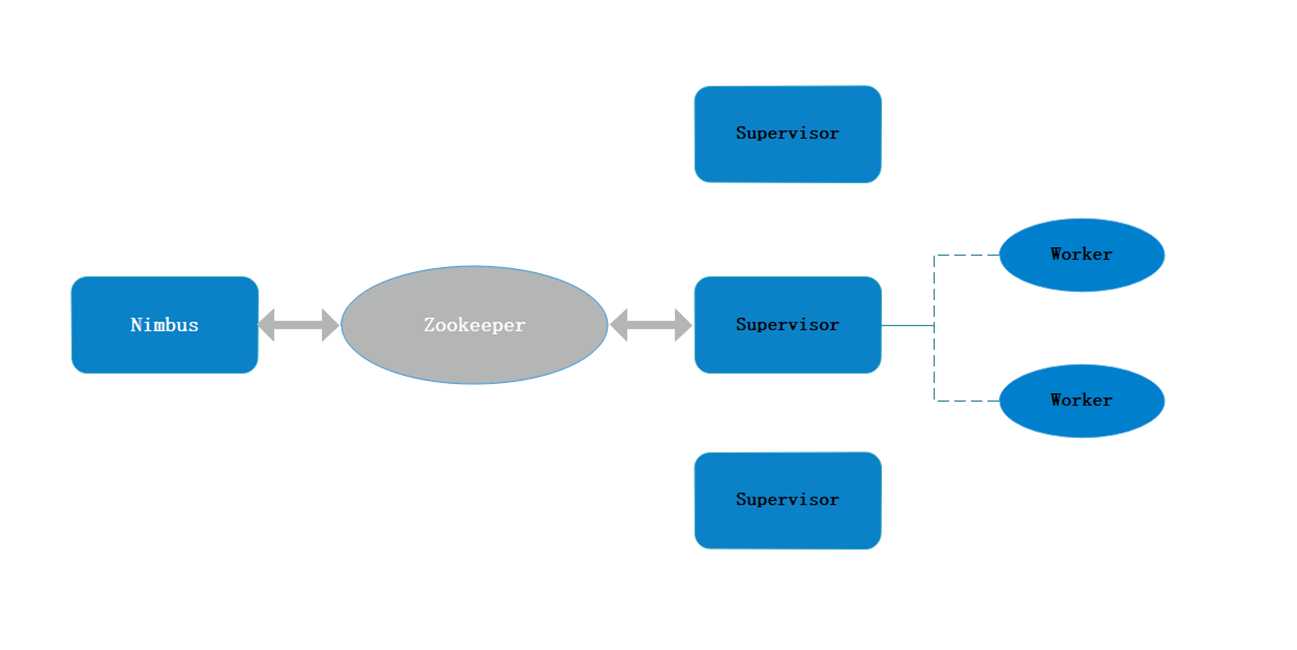
1.Nimbus 主节点的守护进程
2.Supervisor 从节点的守护进程,具体完成计算工作
接受NimBus分配的任务->监视ZK节点看是否有分配给自己的任务
启动、关闭自己管理的Worker进程,可以有多个Worker进程,Work进程的数量由配置文件设定,配置文件是Client上传jar包的配置文件,即由Client指定。
3.Worker 从节点的工作进程
由Supervisor控制启动关闭,专门用于计算,所有的拓扑作业在Worker上运行。
运行具体运算组件的进程,一个topology可能会在一个或者多个worker(工作进程)里面执行。
Worker任务的类型只有两种, Spout和Bolt。
Executor是Worker JVM内部的一个线程,一般每个Executor负责运行一个或多个任务,但仅用于特定的spout或bolt。但一般默认
每个executor只执行一个task。
Worker中可以启动多个线程Executor,执行特定的spout对应的多个task任务,提高并行度,但是注意每个task的taskid不一致,taskid起到了区分作用。
4.Zookeeper
替代了部分Nimbus的作用,也是目前storm是不支持nimbus高可用的但能保证系统不受太大影响的一个支撑。
Zookeeper本身已经是按至少三台部署的HA架构了。Supervisor进程和Nimbus进程,需要用Daemon程序如monit来启动,失效时自动重新启动。因为它们在进程内都不保存状态,状态都保存在本地文件和ZooKeeper,因此进程可以随便杀。
如果Nimbus进程所在的机器都直接倒了,需要在其他机器上重新启动,Storm目前没有自建支持,需要自己写脚本实现。即使Nimbus进程不在了,也只是不能部署新任务,有节点失效时不能重新分配而已,不影响已有的线程。同样,如果Supervisor进程失效,不影响已存在的Worker进程。

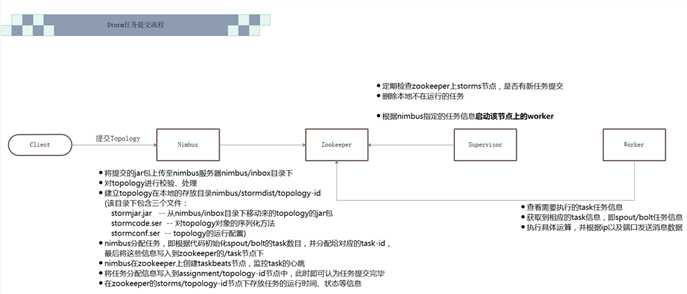
原文:https://www.cnblogs.com/dongchao3312/p/13533259.html