论文:Fully Convolutional Instance-aware Semantic Segmentation
?
?
如果不懂 instance-sensitive score maps 或者说 position-sensitive score maps,建议先去看《Instance-sensitive Fully Convolutional Networks》这篇文章,或者看上一篇梳理https://www.cnblogs.com/importGPX/p/13514977.html,因为FCIS就是(应该是自家研究团队,清华+微软)在那篇的基础上研究的。
下面都按已经看过上篇来说。
?
我把这篇的改进贡献分为两部分。
一是算法原创性改进:
二是时代发展出的通用方法改进:
?
作者认为当时流行的实例分割模型存在以下问题:
作者提出解决方案:
?

卷积操作是平移不变的(translation invariant)的——同一个像素会得到相同的结果,与它的相对位置及上下文无关,但在实例分割中,相同的一个点在不同情况可能应该得到不同的结果,如上图的前两行中的红点,在原图中在相同的位置,是同一个点,但在不同的实例框应该得到不同的结果,第一行的图红点应该属于实例部分,第二行是对于右边的男孩,此点就不应该属于此实例。所以应该引入平移应变性(translation-variant property)。
position sensitive score maps就是《Instance Sensitive FCNs》那篇中的Instance Sensitive score maps,不再重复,不同的是引入了inside/outside来联合解决检测与分割问题。见下节。
?
如果只用position sensitive score maps是不能确定物理类别的,就像《Insatnce sensitive FCNs》一样,为了解决这一问题,经常在后面加一个分类的分支网络。
在本文的方法下,ROI区域内的每个像素有以下两个任务:
简单的方式就是训练两个独立分类器,本文的一种baseline FCIS(separate score maps),就是用了两个1×1卷积层当分类器。
?
FCIS设计了一个联合规则,可以融合这两个任务。首先明确上面提到的inside/outside的含义:
设计的联合规则为,对于ROI中的一个像素:
不可能有第四种 高inside& 高outside(在框内且在框外)。
?
对于检测:使用逐像素的max操作区分前第1、2种情况和第三种情况。然后通过对所有像素的概率进行平均池化,最后做一个在所有类别上的softmax,,得到整个ROI的检测分数。
对于分割:对于每个像素进行softmax区分第1种情况和第2种情况。
检测和分割这两个分数图来自两个1x1卷积层。inside/outside分类器被联合训练,因为它们接收来自于分割和检测损失的梯度。FCN的局部权重共享特性被保持,且作为一种正则化机制。

?
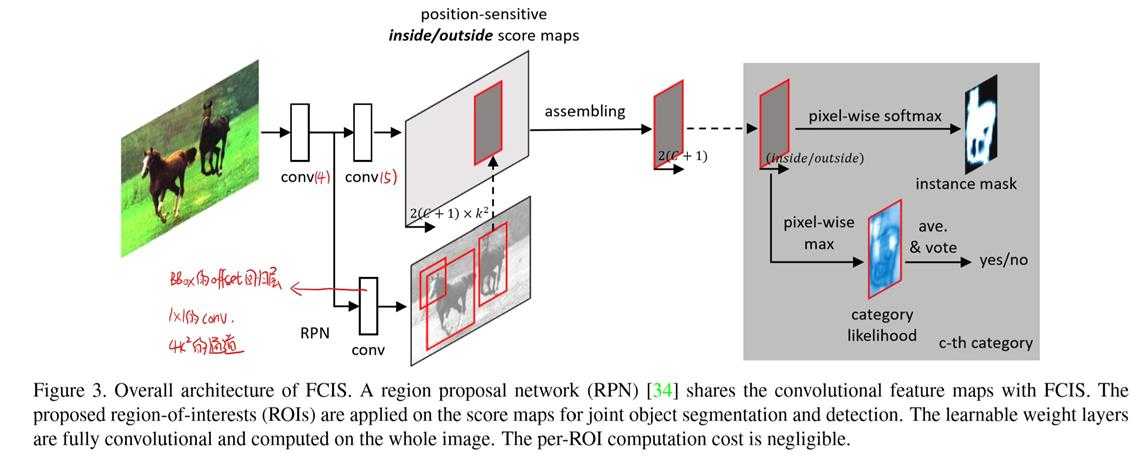
主干网络用ResNet-101,去掉最后用于分类的全连接层,只训练前面的卷积层,最后的特征图是2048通道的,通过1x1的卷积降维到1024。因为是分割要用分辨率更高的feature map,所以把stride从32降到16:conv5第一个block的stride从2降到1。为了保持感受野,使用空洞卷积,conv5所有的卷积层dilation都设置为2。
上分支:使用1x1的卷积从conv5的特征图生成\(2K^2×(C+1)\)个分数图:C类+1个背景类;默认地,k=7(因为最终的特征图相比原始图像缩小了16倍,所以在特征图上,每一个RoI相当于被投影进小16倍的区域中)。然后组装成2×(C+1)个inside/outside分数图。最后进行第二节中所述操作分别得到ROI的mask和检测分类结果。(网络预测阶段时,RPN产生、调整出300个分数最高的ROI,对每个ROI的每个类别都产生分类分数、前景mask,然后再做NMS,保留下最终的结果。)
下分支:在conv4后面接RPN网络,然后再接BBox的offset回归层(1×1的卷积,\(4K^2\)个通道),调整ROI框。
FCIS:Fully Convolutional Instance-aware Semantic Segmentation
原文:https://www.cnblogs.com/importGPX/p/13514982.html