MySQL 数据库在 5.1 版本时添加了对分区(partitioning)的支持。分区的过程是将一个表或索引分解成多个更小、更可管理的部分。就访问数据库的应用而言,从逻辑上来讲,只有一个表或一个索引,但是在物理上这个表或索引可能由数十个物理分区组成。
MySQL 分区功能并不是在存储引擎层完成的,因此不是只有 InnoDB 存储引擎支持分区,常见的存储引擎 MyISAM、NDB 等都支持。
MySQL 数据库支持的分库类型为水平分区(指将同一表中不同行的记录分配到不同的物理文件中),并不支持垂直分区(指将同一表中不同列的记录分配到不同的物理文件中)。
MySQL 数据库的分区是局部分区索引,一个分区中既存放了数据又存放了索引。而全局分区是指,数据存放在各个分区中,但是所有数据的索引放在一个对象中。MySQL 数据库目前不支持全局分区。
MySQL 查看数据库分区。
SHOW VARIABLES LIKE ‘%partitions%‘;
MySQL 数据库支持以下几种类型的分区。1 如果表中存在主键/唯一索引时,分区列必须是主键/唯一索引的一个组成部分。2 对于 RANGE、LIST、HASH 和 KEY 这四种分区中,分区的条件是:数据必须是整型,如果不是整型,那应该需要通过函数将其转化为整型,如 YEAR(),TO_DAYS(),MONTH() 等函数。
子分区(subpartitioning)是在分区的基础上再进行分区,有时也称为这种分区为复合分区(composite partitioning)。MySQL 数据库允许在 RANGE 和 LIST 的分区上再进行 HASH 或 KEY 的子分区。进行子分区后,分区的数量应该为(分区数量 X 子分区数量)个。
MySQL 数据库允许对 NULL 值做分区,视 NULL 值小于任何一个非 NULL 值(和 ORDER BY 处理 NULL 值的规则一致)。
对于 OLAP(在线分析处理) 的应用,分区的确是可以很好地提高查询的性能,因为 OLAP 应用大多数查询需要频繁地扫描一张很大的表。假设有一张 1 亿行的表,其中有一个时间戳属性列。用户的查询依据时间为维度,如果按照时间戳进行分区,则只需要扫描对应的分区即可。
对于 OLTP(在线事务处理)的应用,通常不可能会获取一张大表中 10% 的数据,大部分都是通过索引返回几条记录即可。因此分区应该非常小心,对于一张大表,一般的 B+ 树需要 2~3 次 IO 就能检索到数据。通过根据主键 ID 做 10 个 HASH 的分区后,对于查询就需要扫描所有的 10 个分区,这无疑加重了 IO 的负担。
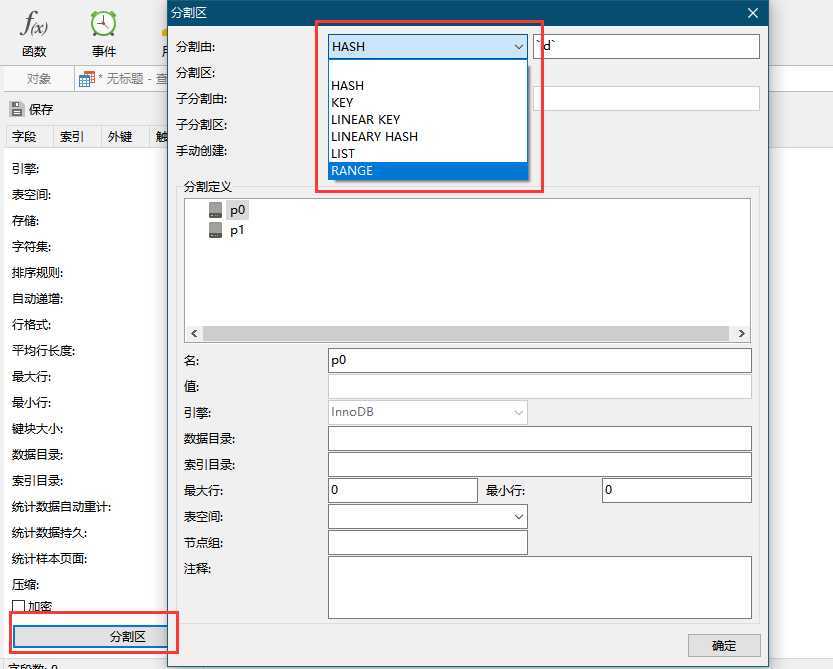
我们通过 Navicat 来操作下数据库分区,表 -> 右键点击‘设计表‘ -> 选项 -> 分割区,可以看到如下内容。
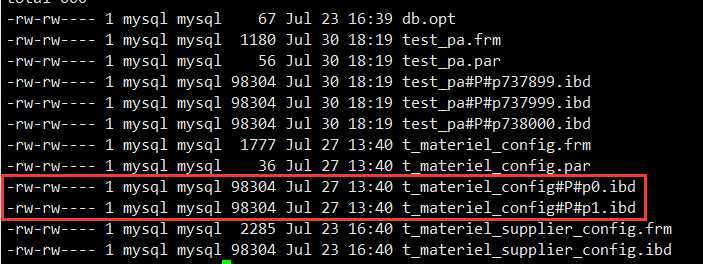
来看看分区后,磁盘中 MySQL 数据库是怎么存储的。
通过 EXPLAIN 分析数据检索的分区。
EXPLAIN PARTITIONS SELECT * FROM t_materiel_config

原文:https://www.cnblogs.com/jmcui/p/13398210.html