#%% 创建series # 传统方法创建 # index 为前10 个 大写字母 string.ascii_uppercase[:10] t = pd.Series(np.arange(10),index = list(string.ascii_uppercase[:10])) print(type(t)) # <class ‘pandas.core.series.Series‘> # 由字典转换为series a = {string.ascii_uppercase[i]: i for i in range(10)} a_s = pd.Series(a) b = pd.Series(a,index = list(string.ascii_uppercase[5:15])) print(b.dtype) #float64 因为有nan存在
#%% series 的切片和索引 print(t[1]) # 取一个值 print(t[2:10:2]) # 取索引2 - 10 步长为2 的值 print(t[[2,3,6]]) # 取 第2,3,6 的值 print(t[t>4]) # 布尔取值 print(t[‘F‘]) # 按索引自取值 print(t[[‘A‘,‘F‘,‘G‘]]) #同上
x[‘one‘,‘h‘] 直接在括号里面写索引即可
x.swaplevel()[‘h‘] 转换复合索引的等级
#%% 查看series的值 print(t.index) print(t.values) print(type(t.index)) # <class ‘pandas.core.indexes.base.Index‘> print(type(t.values)) #<class ‘numpy.ndarray‘>
df.shape 行列数
df.dtypes 列数据类型
df.ndim 数据维度
df.index 行索引
df.columns 列索引
df.values 对象值,转为数组
df.head(3) 显示头部几行,默认5行
df.tail(3) 显示尾部几行,默认5行
df.info() 相关信息浏览
df.describe() 快速显示统计结果
df.sort_values(by="Count_AnimalName",ascending=False) 排序
df= pd.DataFrame(np.arange(12).reshape((3,4))) df2 = pd.DataFrame(np.arange(12).reshape((3,4)),index = list(‘abc‘),columns = list(‘wxyz‘)) # 由字典创建 d1 = {‘name‘:[‘ady‘,‘cindy‘,‘wendy‘], ‘age‘:[11,12,13], ‘tel‘:[113,118,119]} df3 = pd.DataFrame(d1) d2 = [{‘name‘:‘selina‘,‘age‘:13,‘tel‘:1134}, {‘name‘:‘adelina‘,‘age‘:16,‘tel‘:1135}, {‘age‘:18,‘tel‘:1164}] df4 = pd.DataFrame(d2) # 上述没有填的地方会转为nan
df_sorted[:100] 选择行
df[:100][" Count_AnimalName "] 选择行+列
t.loc[‘A‘,‘W‘] 选择行+列 指定某个值
t.loc[‘A‘,[‘w‘,‘z‘]] 选择多列 单行 指定某几个值
t.loc[[‘A‘,‘C‘],[‘W‘,‘Z‘]] 选择间隔的多行多列
t.loc[‘A‘: , [‘W‘,‘Z‘]] t.loc [‘A‘:‘C‘, [‘W‘,‘Z‘]] 冒号在loc里面是指闭合的
布尔索引: df [df[‘Count_AnimalName‘]>800]
且为 & 或为| dog_name[(dog_name[‘Count_AnimalName‘]>700)&(dog_name[‘Row_Labels‘].str.len()>4)]

判断是否为nan pd.isnull(df) pd.notnull(df)
处理方式:
删除Nan 所在的行列 : dropna(axis= 0,how = ‘any‘ ,inplace = False) how = any:只要存在nan 就删掉 how = all 是指整行或整列都是nan的时候删掉 inplace 是指是否原地替换
填充数据 : t.fillna(t.mean()) t.fillna(t.median()) t.fillna(0)
处理为0的数据 : t[t==0] = np.nan
#%%数据合并 #join 把行索引相同的数据合并到一起 t2 = pd.DataFrame(np.zeros((2,5)),index = list(‘AB‘),columns = list(‘VWXYZ‘)) t1 = pd.DataFrame(np.zeros((3,4)),index = list(‘ABC‘),columns = range(4)) t3 = t1.join(t2) #%%merge 按照指定的列吧数据按照一样的方式合并到一起 t1 = pd.DataFrame(np.ones((3,4)),index = list(‘ABC‘),columns = list(‘MNOP‘)) t1[‘O‘] = list(‘abc‘) t2 = pd.DataFrame(np.zeros((2,5)),index = list(‘AB‘),columns = list(‘VWXYZ‘)) t2[‘X‘]=list(‘cd‘) # 并集 t3 = t1.merge(t2,left_on=‘O‘,right_on=‘X‘,how = ‘inner‘) # 相当于sql 的join how 不写的话 默认为inner t4 = t1.merge(t2,left_on=‘O‘,right_on=‘X‘,how = ‘outer‘) # 并集 t5 = t1.merge(t2,left_on=‘O‘,right_on=‘X‘,how = ‘left‘) # 左边为准的补全 t6 = t1.merge(t2,left_on=‘O‘,right_on=‘X‘,how = ‘right‘) #右边为准的补全
# 数据来源 import pandas as pd from pymongo import MongoClient import numpy as np import string from matplotlib import pyplot as plt #%% client = MongoClient() collection = client[‘douban‘][‘tv1‘] data = list(collection.find()) t1 = data[0] t1 = pd.Series(t1) print(data) print(t1) #%% 读取数据 dog_name = pd.read_csv(‘/Users/qqb/Downloads/dogNames2.csv‘,error_bad_lines=False) #pd.read_sql(sql_sentence,connection) #%% movie = pd.read_csv(‘/Users/qqb/Downloads/datasets_1474_2639_IMDB-Movie-Data.csv‘) info = movie.info() #%%平均分 mean_score = movie[‘Rating‘].mean() #演员人数 temp_list = movie[‘Actors‘].str.split(‘,‘).tolist() # tolist 是把series变成list nums = len(set([i for j in temp_list for i in j])) # 先把大list里的每个小list 提取出来 然后再 将小list中的元素提取出来,最后用集合去除重复项 di = movie[‘Director‘].unique() # 电影时长的最大最小值 run_max = movie[‘Runtime (Minutes)‘].max() # 取出最大的那个值 run_max_index = movie[‘Runtime (Minutes)‘].argmax() # 取出最大值所对应的索引 run_min = movie[‘Runtime (Minutes)‘].min() run_min_index = movie[‘Runtime (Minutes)‘].argmin() run_median = movie[‘Runtime (Minutes)‘].median() #%% plt.figure(figsize=(20,8),dpi=80) num_bin = (movie[‘Runtime (Minutes)‘].max()- movie[‘Runtime (Minutes)‘].min())//5 plt.hist(movie[‘Runtime (Minutes)‘],num_bin) plt.xticks(range(movie[‘Runtime (Minutes)‘].min(),movie[‘Runtime (Minutes)‘].max()+5,5)) plt.show() #%% movie = pd.read_csv(‘/Users/qqb/Downloads/datasets_1474_2639_IMDB-Movie-Data.csv‘) #平均分 num_bin_list = np.arange(movie[‘Rating‘].min(),movie[‘Rating‘].max()+0.5,0.5) print(num_bin_list) num_list = np.arange(3.1,3.1+13*0.5,0.5).tolist() plt.figure(figsize=(20,8),dpi=80) plt.hist(movie[‘Rating‘],num_list) print(num_list) plt.xticks(num_list,num_list) plt.show() #%%统计分类的列表 as_movie = movie[‘Genre‘].str.split(‘,‘).tolist() genre_list = list(set(i for j in as_movie for i in j)) # 构建全为0 的数组 zero_movie = pd.DataFrame(np.zeros((movie.shape[0],len(genre_list))),columns = genre_list) print(zero_movie) # 给每个电影出现分类的地方赋值1 !!! for i in range(movie.shape[0]): zero_movie.loc[i,as_movie[i]]=1 # 统计每个电影分类的数量和 sum_movie = zero_movie.sum(axis=0) # 排序 画图 rank_movie = sum_movie.sort_values() plt.figure(figsize=(20,8),dpi = 80) plt.bar(range(len(rank_movie.index)),rank_movie) # 最好x轴先传数字,后期方便调整 plt.xticks(range(len(rank_movie.index)),rank_movie.index)
star = pd.read_csv(‘/Users/qqb/Downloads/directory.csv‘) star.info() #%%分组与聚合 c_star=star.groupby(by=‘Country‘) # 该对象可以进行遍历和调用聚合方法 # for i in c_star: # print(i) # i 为元祖类型 # for i,j in c_star: # print(i) # i 为str # print(j) # j 为dataframe cc = c_star[‘Brand‘].count() #%%美国 中国 哪个地方星巴克多 china = cc[‘CN‘] us = cc[‘US‘] #%% 中国每个省份星巴克的数量 china_data = star[star[‘Country‘]==‘CN‘] china_group = china_data.groupby(by = ‘State/Province‘).count()[‘Brand‘] plt.figure(figsize=(20,8),dpi = 80) plt.bar(china_group.index,china_group) plt.show() #%%数据按照多个条件进行分组 #返回series grouped = star[‘Brand‘].groupby(by=[star[‘Country‘],star[‘State/Province‘]]).count() # 这样之后 country 和 state 变成了索引 print(grouped) #返回Dataframe grouped1 = star.groupby(by=[star[‘Country‘],star[‘State/Province‘]])[[‘Brand‘]].count() grouped2 = star.groupby(by=[star[‘Country‘],star[‘State/Province‘]]).count()[[‘Brand‘]] # 上述 只要[‘Brand‘] 为series 如果是【[‘Brand‘]】 为Dataframe 形式 #%% 使用matplotlib 呈现出店铺总排名前10 的国家 #准备数据 top10 = star.groupby(by = ‘Country‘).count()[‘Brand‘].sort_values(ascending=False)[:10] # 画图 plt.figure(figsize=(20,8),dpi = 80) plt.bar(range(len(top10.index)),top10.values) plt.xticks(range(len(top10.index)),top10.index) #%% 呈现中国每个城市店铺的数量 china_star =star[star[‘Country‘]==‘CN‘] city_star = china_star.groupby(by = ‘City‘).count()[‘Brand‘].sort_values(ascending=False)[:50] plt.figure(figsize=(50,8),dpi = 80) plt.bar(range(len(city_star.index)),city_star.values) plt.xticks(range(len(city_star.index)),city_star.index,rotation=90) plt.show()
df.groupby(by=‘columns_name‘) 得到聚合对象, 可以调用聚合方法以及遍历
df.groupby(by=‘columns_name‘).count()

多标准分组:
grouped = df.groupby(by=[df["Country"],df["State/Province"]])
获取分组之后的某一部分数据:
df.groupby(by=["Country","State/Province"])["Country"].count()
对某几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count()
获取index:df.index
指定index :df.index = [‘x‘,‘y‘]
重新设置index : df.reindex(list("abcedf"))
指定某一列作为index :df.set_index("Country",drop=False) x = a.set_index([‘c‘,‘d‘])[[‘a‘]]
返回index的唯一值:df.set_index("Country").index.unique()
符合索引,交换索引的层级: df.swaplevel()
x.loc[‘one‘]
x.loc[‘one‘].loc[‘h‘]
pd.date_range(start=None, end=None, periods=None, freq=‘D‘) period是指列几个
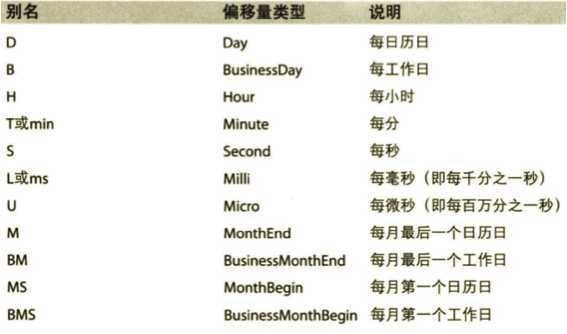
日期的重采样:t.resample(‘M‘).mean() M可换为10D之类
#%% 导入数据 https://www.kaggle.com/zygmunt/goodbooks-10k book=pd.read_csv(‘/Users/qqb/Downloads/1938_3914_bundle_archive/books.csv‘) book.info() #%% 因为年份是有缺失值的,所以先删掉哪一行 book_new = book[pd.notnull(book[‘original_publication_year‘])] book_new.info() #%% 统计不同年份输的数量 year_book = book_new.groupby(by = ‘original_publication_year‘).count()[‘id‘].sort_values(ascending=False) plt.plot(range(len(year_book.index)),year_book.values) plt.xticks(range(len(year_book.index)),year_book.index) #%%不同年份书的平均评分情况 year_rating = book_new[‘average_rating‘].groupby(by=book_new[‘original_publication_year‘]).mean() plt.plot(range(len(year_rating.index)),year_rating.values) plt.xticks(list(range(len(year_rating.index)))[::10],year_rating.index[::10].astype(int),rotation=45)
不同类型的紧急情况的次数,如果我们还想统计出不同月份不 同类型紧急电话的次数的变化情况
#%% 911 紧急电话 emergency=pd.read_csv(‘/Users/qqb/Downloads/911.csv‘) #%% print(emergency.info()) # 获取分类 type_e = emergency[‘title‘].str.split(‘:‘).tolist() type_emergency = list(set([i[0] for i in type_e])) #%% 构造全为0 的数组 ze = pd.DataFrame(np.zeros((emergency.shape[0],len(type_emergency))),columns=type_emergency) a=emergency[‘title‘].str.contains(‘EMS‘) for t in type_emergency: ze[t][emergency[‘title‘].str.contains(t)]=1 # 这个方法快很多 #%% # for i in range(emergency.shape[0]): # ze.loc[i,type_e[i][0]] = 1 # #%% sum_ret = ze.sum(axis=0) #%% 简便方式 emergency[‘cate‘]=[i[0] for i in type_e] grouped = emergency.groupby(by=‘cate‘).count()[‘‘] #%% 不同月份不同类型的紧急电话的分布情况 # https://blog.csdn.net/shomy_liu/article/details/44141483 emergency[‘timeStamp‘]=pd.to_datetime(emergency["timeStamp"],format=‘%Y-%m-%d‘) #%% emergency.set_index(‘timeStamp‘,inplace=True) #%% mon = emergency.resample(‘M‘).count()[‘title‘] print(emergency.head()) print(mon) #%% 画图 plt.figure(figsize=(20,8),dpi=80) x = [i.strftime(‘%Y-%m-%d‘) for i in mon.index] plt.plot(range(len(mon.index)),mon.values) plt.xticks(range(len(mon.index)),x,rotation=90) #%% 不同月份不同种类的紧急电话 # 将时间设置为索引 emergency[‘timeStamp‘]=pd.to_datetime(emergency["timeStamp"],format=‘%Y-%m-%d‘) emergency.set_index(‘timeStamp‘,inplace=True) #%%添加列表示分类 type_e = emergency[‘title‘].str.split(‘:‘).tolist() emergency[‘cate‘]=[i[0] for i in type_e]
#%% 不同月份不同紧急 #导入数据 emergency=pd.read_csv(‘/Users/qqb/Downloads/911.csv‘) emergency.info() #%% type_e = emergency[‘title‘].str.split(‘:‘) emergency[‘cate‘]=[i[0] for i in type_e] #%% 转为时间时间格式并设置为索引 emergency[‘timeStamp‘]=pd.to_datetime(emergency["timeStamp"],format=‘%Y-%m-%d‘) emergency.set_index(‘timeStamp‘,inplace = True) #%% plt.figure(figsize=(20,8),dpi=80) for a,b in emergency.groupby(by = ‘cate‘): _x = [i.strftime(‘%Y-%m-%d‘) for i in b.index] c = b.resample(‘M‘).count()[‘title‘] plt.plot(range(len(c.index)),c.values,label=a) plt.xticks(range(len(c.index)),_x,rotation=90) plt.legend() plt.show()
bj = pd.read_csv(‘/Users/qqb/Downloads/2168_3650_bundle_archive/BeijingPM20100101_20151231.csv‘) cd = pd.read_csv(‘/Users/qqb/Downloads/2168_3650_bundle_archive/ChengduPM20100101_20151231.csv‘) gz = pd.read_csv(‘/Users/qqb/Downloads/2168_3650_bundle_archive/GuangzhouPM20100101_20151231.csv‘) sh = pd.read_csv(‘/Users/qqb/Downloads/2168_3650_bundle_archive/ShanghaiPM20100101_20151231.csv‘) sy = pd.read_csv(‘/Users/qqb/Downloads/2168_3650_bundle_archive/ShenyangPM20100101_20151231.csv‘) #%% bj.info() bj_new.info() #%% periodindex 时间段 # periods = pd.PeriodIndex(year=data["year"],month=data["month"],day=data["day"],hour=data["hour"],freq="H") # data = df.set_index(periods).resample("10D").mean() bj_hour = pd.PeriodIndex(year = bj[‘year‘],month = bj[‘month‘],day = bj[‘day‘],hour=bj[‘hour‘],freq=‘H‘) bj[‘bj_hour‘]=bj_hour cd_hour = pd.PeriodIndex(year = cd[‘year‘],month = cd[‘month‘],day = cd[‘day‘],hour=cd[‘hour‘],freq=‘H‘) cd[‘bj_hour‘]=cd_hour bj.set_index(‘bj_hour‘,inplace=True) #%% # 处理缺失数据,删除缺失数据 bj_new = bj[pd.notnull(bj[‘PM_US Post‘])] bj_to = bj[‘PM_US Post‘] #%%重采样 bj = bj.resample(‘M‘).mean() #%% 中国数据 bj_china = bj[‘PM_Dongsi‘] #%%绘图 plt.figure(figsize = (20,8),dpi=80) plt.plot(range(len(bj.index)),bj[‘PM_US Post‘]) plt.plot(range(len(bj_china.index)),bj_china.values) plt.xticks(range(len(bj.index)),bj.index,rotation=90) plt.show()
原文:https://www.cnblogs.com/adelinebao/p/13388665.html