import pandas as pd
train = pd.read_csv(r‘./train_set.csv‘, sep=‘\t‘)
test_a = pd.read_csv(r‘./test_a.csv‘, sep=‘\t‘)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import RidgeClassifier
def do_nothing_tfidf(train_data):
import time
start = time.time()
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(train[‘text‘])
y = train[‘label‘]
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=seed)
clf = RidgeClassifier()
clf.fit(x_train, y_train)
print(clf.score(x_train, y_train))
y_pre = clf.predict(x_valid)
print(f1_score(y_valid, y_pre, average=‘macro‘))
print(‘spent 【%d】s‘%(int(time.time() - start)))
def set_ngram_tfidf(train_data):
import time
start = time.time()
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(ngram_range=(1,3))
X = tfidf.fit_transform(train[‘text‘])
y = train[‘label‘]
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=seed)
clf = RidgeClassifier()
clf.fit(x_train, y_train)
print(clf.score(x_train, y_train))
y_pre = clf.predict(x_valid)
print(f1_score(y_valid, y_pre, average=‘macro‘))
print(‘spent 【%d】s‘%(int(time.time() - start)))
def set_ngram_max_feature_tfidf(train_data):
import time
start = time.time()
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=5000)
X = tfidf.fit_transform(train[‘text‘])
y = train[‘label‘]
x_train, x_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=seed)
clf = RidgeClassifier()
clf.fit(x_train, y_train)
print(clf.score(x_train, y_train))
y_pre = clf.predict(x_valid)
print(f1_score(y_valid, y_pre, average=‘macro‘))
print(‘spent 【%d】s‘%(int(time.time() - start)))
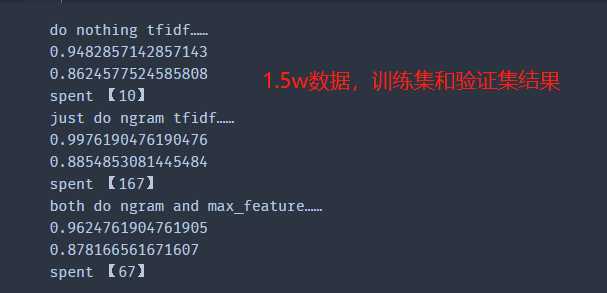
print(‘=============do nothing tfidf……================‘)
do_nothing_tfidf(train)
print(‘=============just do ngram tfidf……=============‘)
set_ngram_tfidf(train)
print(‘=============both do ngram and max_feature……============‘)
set_ngram_max_feature_tfidf(train)
]
原文:https://www.cnblogs.com/Alexisbusyblog/p/13378863.html