数组抓取之二------爬虫分析
一.今日任务
根据本地网页完成爬虫爬取网页任务,分析各个电影的评分,并且求其平均分,并保留四位小数
二.任务源码分析
根据任务要求,第一步先获取网页数据,之后根据网页的相关内容获取评分信息,最后求评分信息的平均分
import re
sum = 0
num = 0
with open(r"C:\Users\liu\Desktop\arg\task0202\movie_review.htm", "r", encoding="utf-8") as file:
html = file.read()
#print(html)
pattern = re.compile("<span class=\"subject-rate\">(.*?)</span>")
str = pattern.findall(html)
for i in str:
sum += float(i.replace(" ", "")) #获取的评分数据有部分是有空格的小数字符串,先去空格,然后转为小数类型
num = len(str)
avg = sum /num
avg = format(avg, ".4f")
print(avg)
with open(r"ans0202.txt", "w", encoding="utf-8") as file:
file.write(avg)
三.遇到问题
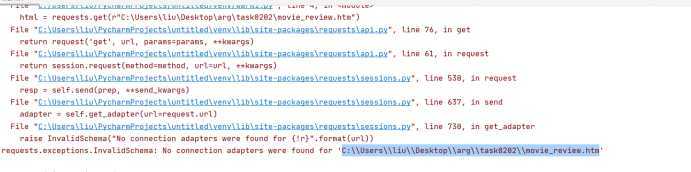
四.解决方案
使用文件读写的方式来,然后使用正则表达式匹配评分的span标签
原文:https://www.cnblogs.com/ningl666/p/13367227.html