·可以用成对的单引号或者双引号表示
·用三个连续的单引号可表示多行字符串
>>> ‘abc‘, "abc"
(‘abc‘, ‘abc‘)
>>> ‘‘‘你好
世界!‘‘‘
‘你好\n 世界!‘
>>> ‘‘‘Hello
World!‘‘‘
‘Hello\n\n World!‘
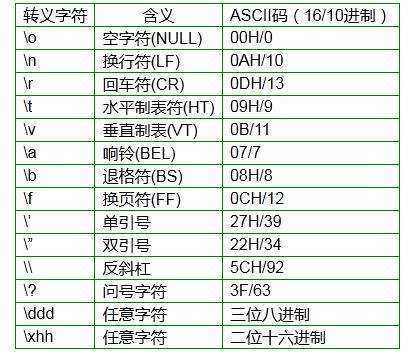
·特殊符号用转移符号“\”表示
·字符串中第一个字符的编号为0,第二个为1,……
·字符串中最后一个字符的编号为-1,倒数第二个为-2,……
>>> s = "My name is Lily" >>> s[-3] ‘i‘ >>> s[3] ‘n‘
(1)切片
· s[start : end : step](start和end表示切片范围[start, end) ,step表示步长)
>>> s = ‘Hello World!‘ >>> s[1 : 7 : 2] ‘el ‘ >>> s[1 : 8 :2] ‘el o‘
·split(sp,maxsplit),按指定字符sp(默认空格)将原字符串切割为多个字符串,用maxsplit指定最大切割次数,最终返回切割后的字符串所组成的列表
>>> s = ‘Hello World!‘ >>> sp = s.split(‘l‘) >>> sp [‘He‘, ‘‘, ‘o Wor‘, ‘d!‘]
(2)大小写转换
·upper() # 全部大写
·lower() # 全部小写
·swapcase() # 大小写互换
·capitalize() # 首字母大写,其余小写
·title() # 标题格式,单词首字母大写
>>> s = ‘Hello World!‘ >>> print(s.upper(), "\n", s.lower(), "\n", s.title()) HELLO WORLD! hello world! Hello World! >>> print(s.swapcase(), "\n", s.capitalize()) hELLO wORLD! Hello world!
(3)替换
·replace(old,new,count)
用new替换字符串中的old,count指定替换的最大次数,默认(不指定)替换全部,产生新的字符串
>>> s = ‘Hello World!‘ >>> print(s.replace(‘l‘, ‘p‘), ‘\n‘, s.replace(‘l‘, ‘p‘, 2)) Heppo Worpd! Heppo World!
(4)去空格和指定字符
·strip(),删除字符串两端的空白字符,可以指定删除的字符
·lstrip(),删除字符串左边的空白字符,可以指定删除的字符
·rstrip(),删除字符串末尾的空白字符,可以指定删除的字符
>>> s = ‘aab ccc baa‘ >>> print(s.strip(‘a‘), ‘\n‘, s.lstrip(‘a‘), ‘\n‘, s.rstrip(‘a‘)) b ccc b b ccc baa aab ccc b
(5)格式化对齐相关
·ljust(width, fillstr) 左对齐,右边用fillstr指定的字符(默认用空格)补齐
·rjust(width, fillstr) 右对齐,左边用fillstr指定的字符(默认用空格)补齐
·center(width, fillstr) 居中,两边用fillstr指定的字符(默认用空格)补齐
·zfill(10) 右对齐,左边用0补齐
>>> s = ‘a bc‘ >>> print(s.ljust(10,‘*‘), ‘\n‘, s.rjust(10,‘-‘), ‘\n‘, s.center(10), ‘\n‘, s.zfill(10)) a bc****** ------a bc a bc 000000a bc
(6)字符串查找函数
·find(str, start, end) 搜索指定字符串,没有返回-1
·index(str, start, end) 同上,但是找不到会报错,搜索区间为左闭右开
·rfind(str, start, end) 从右边开始查找
·count(str, start, end) 统计指定的字符串出现的次数
(7)字符串查找函数
·startswith(‘start‘) 是否以start开头
·endswith(‘end‘) 是否以end结尾
·isalnum() 是否全为字母或数字
·isalpha() 是否全字母
·isdigit() 是否全数字
·islower() 是否全小写
·isupper() 是否全大写
·istitle() 判断首字母是否为大写
·isspace() 判断字符是否为空格
|
1 |
capitalize() |
|
2 |
center(width, fillchar) |
|
3 |
count(str, beg= 0,end=len(string)) |
|
4 |
bytes.decode(encoding="utf-8", errors="strict") |
|
5 |
encode(encoding=‘UTF-8‘,errors=‘strict‘) |
|
6 |
endswith(suffix, beg=0, end=len(string)) |
|
7 |
expandtabs(tabsize=8) |
|
8 |
find(str, beg=0, end=len(string)) |
|
9 |
index(str, beg=0, end=len(string)) |
|
10 |
isalnum() |
|
11 |
isalpha() |
|
12 |
isdigit() |
|
13 |
islower() |
|
14 |
isnumeric() |
|
15 |
isspace() |
|
16 |
istitle() |
|
17 |
isupper() |
|
18 |
join(seq) |
|
19 |
len(string) |
|
20 |
ljust(width[, fillchar]) |
|
21 |
lower() |
|
22 |
lstrip() |
|
23 |
maketrans() |
|
24 |
max(str) |
|
25 |
min(str) |
|
26 |
replace(old, new [, max]) |
|
27 |
rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
|
28 |
rindex( str, beg=0, end=len(string)) |
|
29 |
rjust(width,[, fillchar]) |
|
30 |
rstrip() |
|
31 |
split(str="", num=string.count(str)) |
|
32 |
splitlines([keepends]) |
|
33 |
startswith(substr, beg=0,end=len(string)) |
|
34 |
strip([chars]) |
|
35 |
swapcase() |
|
36 |
title() |
|
37 |
translate(table, deletechars="") |
|
38 |
转换字符串中的小写字母为大写 |
|
39 |
zfill (width) |
|
40 |
isdecimal() |
原文:https://www.cnblogs.com/sunshine-smile-07/p/13367084.html