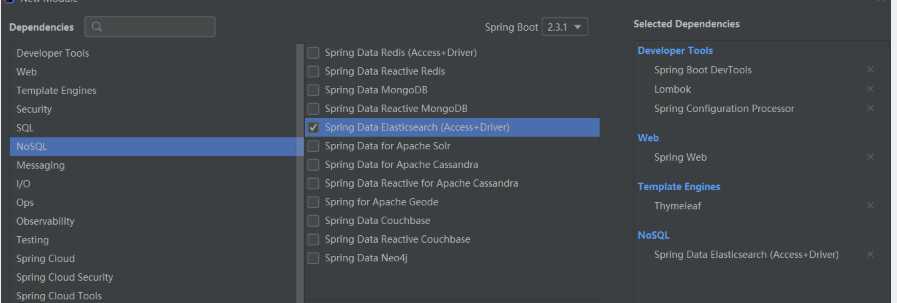
补充以下依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
注意自定义springboot中的es版本自己选择的es版本!!!
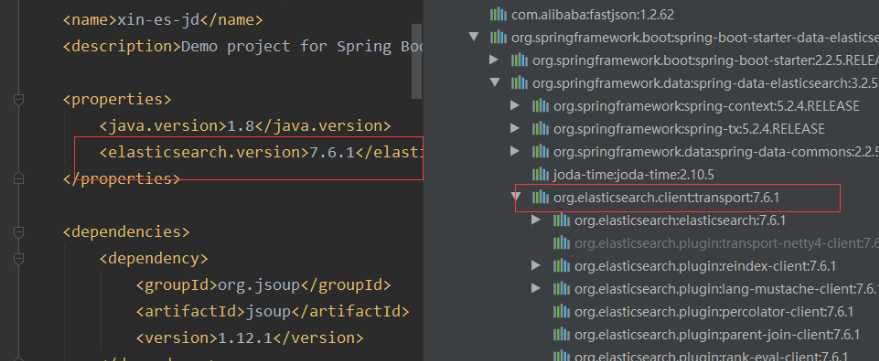
配置文件
server.port=9090 #关闭 thymeleaf缓存 spring.thymeleaf.cache=false
@Component public class HttpParseUtils { // public static void main(String[] args) throws Exception { // new HttpParseUtils().parseJD("python").forEach(System.out::println); // } public List<Content> parseJD(String keyWords) throws Exception{ //获取请求 https://search.jd.com/Search?keyword=java //前提 需要联网 ajax请求无法获取 获取需要模拟浏览器 String url ="https://search.jd.com/Search?keyword="+keyWords; //解析网页 (Jsoup返回Document就是浏览器Document对象) Document document = Jsoup.parse(new URL(url), 30000); //所有在js中的使用的方法都阔以用 Element element = document.getElementById("J_goodsList"); // System.out.println(element.html()); //获取所有li元素 Elements elements = document.getElementsByTag("li"); ArrayList<Content> goodsList = new ArrayList(); //获取每一个li元素的内容 for (Element el : elements) { String img = el.getElementsByTag("img").eq(0).attr("src"); String price = el.getElementsByClass("p-price").eq(0).text(); String title = el.getElementsByClass("p-name").eq(0).text(); Content content = new Content(); content.setImg(img); content.setPrice(price); content.setTitle(title); goodsList.add(content); } return goodsList; } }
@Configuration public class ElastricSearchClientConfig { @Bean public RestHighLevelClient client(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("127.0.0.1",9200,"http"))); return client; } }
业务逻辑
@Service public class ContentService{ @Autowired @Qualifier("client") private RestHighLevelClient restHighLevelClient; //1.解析数据放到es索引中 public Boolean parseContent(String keywords) throws Exception{ List<Content> contents = new HttpParseUtils().parseJD(keywords); //把查询的数据放到es中 BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("2m"); for (int i = 0; i < contents.size(); i++) { System.out.println(JSON.toJSONString(contents.get(i))); bulkRequest.add( new IndexRequest("jd_goods") .source(JSON.toJSONString(contents.get(i)), XContentType.JSON)); } BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); return !bulk.hasFailures(); } //2.获取这些数据实现搜索功能 public List<Map<String,Object>> searchPage(String keword , int pageNo, int pageSize) throws IOException { if (pageNo<=1) { pageNo=1; } //条件搜索 SearchRequest searchRequest = new SearchRequest("jd_goods"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //分页 sourceBuilder.from(pageNo); sourceBuilder.size(pageSize); //精准匹配 TermQueryBuilder term = QueryBuilders.termQuery("title", keword); sourceBuilder.query(term); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //执行搜素 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); //解析结果 ArrayList<Map<String,Object>> list = new ArrayList(); for (SearchHit documentFields : searchResponse.getHits().getHits()) { list.add(documentFields.getSourceAsMap()); } return list; } //2.获取这些数据实现搜索功能 高亮功能 public List<Map<String,Object>> searchPageHighlighter(String keword , int pageNo, int pageSize) throws IOException { if (pageNo<=1) { pageNo=1; } //条件搜索 SearchRequest searchRequest = new SearchRequest("jd_goods"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //分页 sourceBuilder.from(pageNo); sourceBuilder.size(pageSize); //精准匹配 TermQueryBuilder term = QueryBuilders.termQuery("title", keword); sourceBuilder.query(term); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //高亮 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.field("title"); highlightBuilder.requireFieldMatch(false);//多个高亮显示! highlightBuilder.preTags("<span style=‘color:red‘>"); highlightBuilder.postTags("</span>"); sourceBuilder.highlighter(highlightBuilder ); //执行搜素 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); //解析结果 ArrayList<Map<String,Object>> list = new ArrayList(); for (SearchHit hit : searchResponse.getHits().getHits()) { Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField title = highlightFields.get("title"); Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的字段 //解析高亮字段 将原来的字段替换为我们高亮的字段 if(title!=null){ Text[] fragments = title.fragments(); String n_title=""; for (Text text : fragments) { n_title += text; } sourceAsMap.put("title",n_title); } list.add(sourceAsMap); } return list; } }
控制层
@RestController public class ContentController { @Autowired private ContentService contentService; @GetMapping("/parse/{keyword}") public Boolean parse(@PathVariable("keyword") String keywords) throws Exception { return contentService.parseContent(keywords); } @GetMapping("/search/{keyword}/{pageNo}/{pageSize}") public List<Map<String,Object>> search(@PathVariable("keyword") String keyword, @PathVariable("pageNo") int pageNo, @PathVariable("pageSize") int pageSize) throws IOException { return contentService.searchPageHighlighter(keyword,pageNo,pageSize); } }
pojo
@Data @AllArgsConstructor @NoArgsConstructor public class Content { private String title; private String img; private String price; }
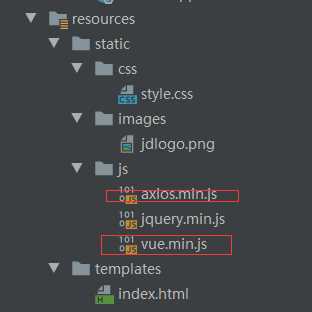
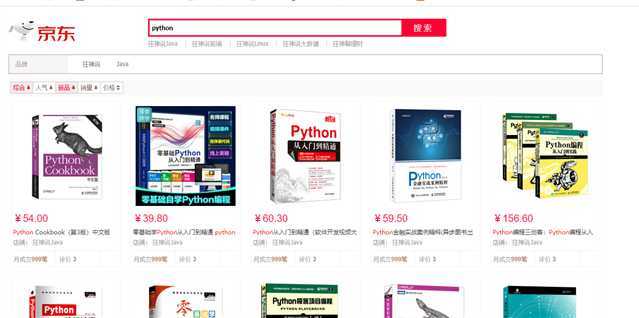
1.发现爬虫爬取的数据有一部分为空,至今没有解决,很困惑为啥?,有博友了解可以留言讨论。
2.没有自定义es版本或者maven没有加载成功 导致运行出现type is missing报错 已解决
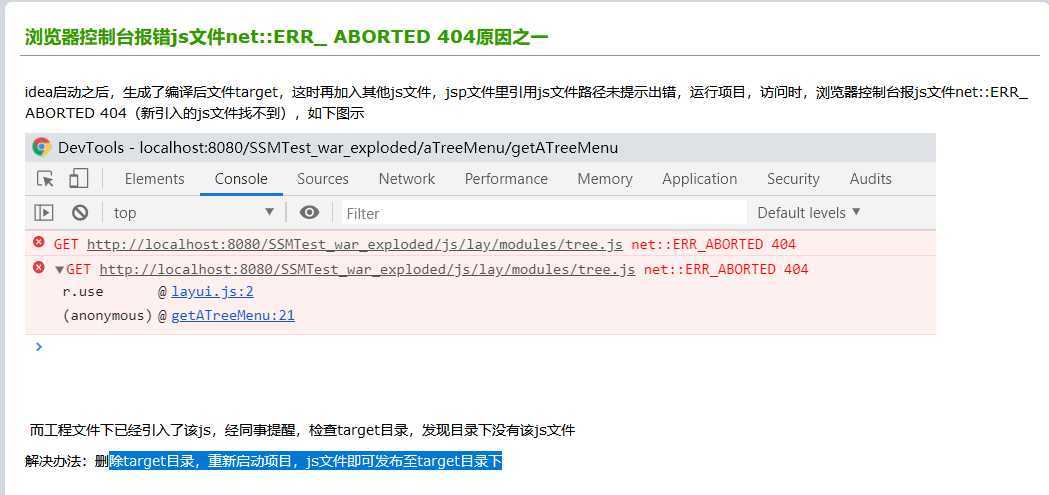
3.在前后端分离浏览器没有引入js文件 问题如下图 已解决
原文:https://www.cnblogs.com/snax/p/13367384.html