1、介绍
Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器。它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列
2、创建DataFrame
# -*- encoding=utf-8 -*- import pandas if __name__ == ‘__main__‘: pass test_stu = pandas.DataFrame( {‘高数‘: [66, 77, 88, 99, 85], ‘大物‘: [88, 77, 85, 78, 65], ‘英语‘: [99, 84, 87, 56, 75]}, ) print(test_stu) stu = pandas.DataFrame( {‘高数‘: [66, 77, 88, 99, 85], ‘大物‘: [88, 77, 85, 78, 65], ‘英语‘: [99, 84, 87, 56, 75]}, index=[‘小红‘, ‘小李‘, ‘小白‘, ‘小黑‘, ‘小青‘] # 指定index索引 ) print(stu)
运行
高数 大物 英语 0 66 88 99 1 77 77 84 2 88 85 87 3 99 78 56 4 85 65 75 高数 大物 英语 小红 66 88 99 小李 77 77 84 小白 88 85 87 小黑 99 78 56 小青 85 65 75
3、读取CSV或Excel(.xlsx)进行简单操作(增删改查)
data.csv
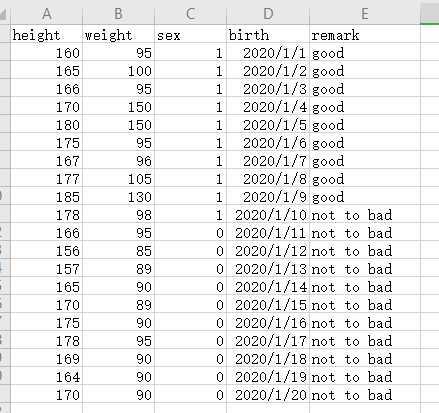
# -*- encoding=utf-8 -*- import pandas if __name__ == ‘__main__‘: pass data = pandas.read_csv(‘data.csv‘, engine=‘python‘) # 使用python分析引擎读取csv文件 print(data.head(5)) # 显示前5行, print(data.tail(5)) # 显示后5行 print(data) # 显示所有数据 print(data[‘height‘]) # 显示height列 print(data[[‘height‘, ‘weight‘]]) # 显示height和weight列 data.to_csv(‘write.csv‘) # 保存到csv文件 data.to_excel(‘write.xlsx‘) # 保存到xlsx文件 data.info() # 查看数据信息(总行数,有无空缺数据,类型) print(data.describe()) # (count非空值,mean均值、std标准差、min最小值、max最大值25%50%75%分位数。) data[‘新增列‘] = range(0, len(data)) # 类似字典直接添加即可 print(data) new_data = data.drop(‘新增列‘, axis=1, inplace=False) # 删除列,如果inplace为True则在源数据删除,返回None,否则返回新数据,不改动源数据 print(new_data) data[‘体重+身高‘] = data[‘height‘] + data[‘weight‘] print(data) data[‘remark‘] = data[‘remark‘].str.replace(‘to‘, ‘‘) # 操作字符串 print(data[‘remark‘]) data[‘birth‘] = pandas.to_datetime(data[‘birth‘]) # 转为日期类型 print(data[‘birth‘])
4、根据条件进行筛选,截取
# -*- encoding=utf-8 -*- import pandas if __name__ == ‘__main__‘: pass data = pandas.read_csv(‘data.csv‘, engine=‘python‘) # 使用python分析引擎读取csv文件 a = data.iloc[:12, ] # 截取0-12行,列全截 # print(a) b = data.iloc[:, [1, 3]] # 行全截,列1,3 # print(b) c = data.iloc[0:12, 0:4] # 截取行0-12,列0-4 # print(c) d = data[‘sex‘] == 1 # 查看性别为1(男)的 # print(d) f = data.loc[data[‘sex‘] == 1, :] # 查看性别为1(男)的 # print(f) g = data.loc[:, [‘weight‘, ‘height‘]] # 选取身高体重 # print(g) h = data.loc[data[‘height‘].isin([166, 175]), :] # 选取身高166,175的数据 # print(h) h1 = data.loc[data[‘height‘].isin([166, 175]), [‘weight‘, ‘height‘]] # 选取身高166,175的数据 # print(h1) i = data[‘height‘].mean() # 均值 j = data[‘height‘].std() # 方差 k = data[‘height‘].median() # 中位数 l = data[‘height‘].min() # 最小值 m = data[‘height‘].max() # 最大值 # print(i) # print(j) # print(k) # print(l) # print(m) n = data.loc[ (data[‘height‘] > data[‘height‘].mean()) & (data[‘weight‘] > data[‘weight‘].mean()), :] # 身高大于身高均值,且体重大于体重均值,不能用and要用&如果是或用| print(n)
5、清Nan数据,去重,分组,合并
# -*- encoding=utf-8 -*- import pandas if __name__ == ‘__main__‘: pass sheet1 = pandas.read_excel(‘data.xlsx‘, sheet_name=‘Sheet1‘) # 读取sheet1 # print(sheet1) # print(‘-------------------------‘) sheet2 = pandas.read_excel(‘data.xlsx‘, sheet_name=‘Sheet2‘) # 读取sheet2 # print(sheet2) # print(‘-------------------------‘) a = pandas.concat([sheet1, sheet2]) # 合并 # print(a) # print(‘-------------------------‘) b = a.dropna() # 删除空数据nan,有nan的就删除 # print(b) # print(‘-------------------------‘) b1 = a.dropna(subset=[‘weight‘]) # 删除指定列的空数据nan # print(b1) # print(‘-------------------------‘) c = b.drop_duplicates() # 删除重复数据 # print(c) # print(‘-------------------------‘) d = b.drop_duplicates(subset=[‘weight‘]) # 删除指定列的重复数据 # print(d) # print(‘-------------------------‘) e = b.drop_duplicates(subset=[‘weight‘], keep=‘last‘) # 删除指定列的重复数据,保存最后一个相同数据 # print(e) # print(‘-------------------------‘) f = a.sort_values([‘weight‘], ascending=False) # 从大到小排序weight # print(f) g = c.groupby([‘sex‘]).sum() # 根据sex分组,再求和 # print(g) g1 = c.groupby([‘sex‘], as_index=False).sum() # 根据sex分组,再求和,但sex不作为索引 # print(g1) g2 = c.groupby([‘sex‘, ‘weight‘]).sum() # 根据sex分组后再根据weight分组,再求和 # print(g2) h = pandas.cut(c[‘weight‘], bins=[80, 90, 100, 150, 200], ) # 根据区间分割体重 print(h) # print(‘-------------------------‘) c[‘根据体重分割‘] = h # 会有警告,未解决,但不影响结果 print(c)
学习链接:
初识pandas
灵活的pandas索引
清洗常用4板斧
优雅的apply
https://mp.weixin.qq.com/s?__biz=MzU5Mjg2OTQ1MA==&mid=2247484179&idx=1&sn=e84c5fead658438b7dde1d6e056db084&chksm=fe186236c96feb20c892d5b00c7b54333f098f62485b577c510033aab20009560ca073abdf39&scene=21#wechat_redirect
原文:https://www.cnblogs.com/rainbow-tan/p/13359649.html