nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None)
其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量(嵌入向量反映了各个编号代表的符号之间的语义关系)
输入为一个编号列表,输出为对应的符号嵌入向量列表。
1 import torch 2 from torch import nn 3 4 word_to_idx = {‘hello‘:0, ‘world‘:1} #给单词编索引号 5 lookup_tensor = torch.tensor([word_to_idx[‘hello‘]], dtype=torch.long) #得到目标单词索引 6 7 embeds = nn.Embedding(2,5) 8 hello_embed = embeds(lookup_tensor) #传入单词的index,返回对应的嵌入向量 9 print(hello_embed)
tensor([[ 0.0254, 1.2267, -0.9689, -0.1929, -0.2187]],grad_fn=<EmbeddingBackward>)
Tip:上面nn.Embedding的那张表是没有初始化的,得到的嵌入向量是随机生成的,初始化一般采用现成的编码方式,把word2vec或者GloVe下载下来,数据内容填充进表。
下面直接使用GloVe方式进行查表操作(提前pip install pytorch-nlp),运行时需要漫长的等待下载。
1 from torchnlp.word_to_vector import GloVe 2 vectors = GloVe() 3 4 print(vectors[‘hello‘])
nn.RNN的数据处理如下图所示。每次向网络中输入batch个样本,每个时刻处理的是该时刻的batch个样本,因此xt?是shape为[batch,feature_len]的Tensor。例如,输入3句话,每句话10个单词,每个单词用100维的向量表示,那么seq_len=10,batch=3,feature_len=100。
隐藏记忆单元h的shape是二维的[batch,hidden_len],其中hidden_len是一个可以自定的超参数,如可以取为20,表示每个样本用20长度的向量记录。
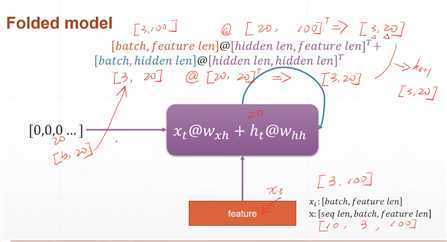
参数:
1 from torch import nn 2 3 rnn = nn.RNN(100, 10) #词向量维度100维,输出维度10 4 print(rnn._parameters.keys()) #odict_keys([‘weight_ih_l0‘, ‘weight_hh_l0‘, ‘bias_ih_l0‘, ‘bias_hh_l0‘]) 5 6 print(rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape) #torch.Size([10, 10]) torch.Size([10, 100]) 7 print(rnn.bias_hh_l0.shape, rnn.bias_ih_l0.shape) #torch.Size([10]) torch.Size([10])
Tip:bias只取hidden_len,等到作加法时会广播到所有的batch上。
1 #单层RNN 2 import torch 3 from torch import nn 4 5 rnn = nn.RNN(100, 20, 1) #feature_len=100, hidden_len=20, 层数=1 6 x = torch.randn(10, 3, 100) #单词数量(seq_len=10),句子数量(batch=3),每个特征100维度(feature_len=100) 7 out, h = rnn(x, torch.zeros(1, 3, 20)) #传入RNN处理, 另外传入h_0, shape是<层数, batch, hidden_len=20> 8 9 print(out.shape) #torch.Size([10, 3, 20]) 10 print(h.shape) #torch.Size([1, 3, 20])
相比2.1处的代码,只要改变层数即可。
1 from torch import nn 2 3 rnn = nn.RNN(100, 20, 2) #词向量维度100维,输出维度20,层数为2 4 print(rnn._parameters.keys()) #odict_keys([‘weight_ih_l0‘, ‘weight_hh_l0‘, ‘bias_ih_l0‘, ‘bias_hh_l0‘, ‘weight_ih_l1‘, ‘weight_hh_l1‘, ‘bias_ih_l1‘, ‘bias_hh_l1‘]) 5 6 print(rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape) #torch.Size([20, 20]) torch.Size([20, 100]) 7 print(rnn.weight_hh_l1.shape, rnn.weight_ih_l1.shape) #torch.Size([20, 20]) torch.Size([20, 20])
Tip:从l1层开始接受的输入都是下面层的输出,即接受的输入特征数不再是feature_len而是hidden_len,所以这里参数weight_ih_l1的shape应是[hidden_len,hidden_len]
out,ht=forward(x,h0)
1 import torch 2 from torch import nn 3 4 rnn = nn.RNN(100, 20, 4) #feature_len=100, hidden_len=20, 层数=4 5 x = torch.randn(10, 3, 100) #单词数量(seq_len=10),句子数量(batch=3),每个特征100维度(feature_len=100) 6 out, h = rnn(x, torch.zeros(4, 3, 20)) #传入RNN处理, 另外传入h_0, shape是<层数, batch, hidden_len=20> 7 8 print(out.shape) #torch.Size([10, 3, 20]) 9 print(h.shape) #torch.Size([4, 3, 20])
nn.RNN是一次性将所有时刻特征喂入的,nn.RNNCell将序列上的每个时刻分开来处理。
举例:如果要处理3个句子,每个句子10个单词,每个单词用100维的嵌入向量表示,那么nn.RNN传入的Tensor的shape是[10,3,100],nn.RNNCell传入的Tensor的shape是[3,100],将此计算单元运行10次。
初始化方法和上面一样。
1 import torch 2 from torch import nn 3 4 #单层RNN 5 cell1 = nn.RNNCell(100, 20) 6 h1 = torch.zeros(3, 20) 7 x = torch.randn(10, 3, 100) 8 for xt in x: #xt.shape=[3, 100] 9 h1 = cell1(xt, h1) 10 print(h1.shape) #torch.Size([3, 20]) 11 12 13 #多层RNN 14 cell1 = nn.RNNCell(100, 30) 15 cell2 = nn.RNNCell(30, 20) 16 17 h1 = torch.zeros(3, 30) 18 h2 = torch.zeros(3, 20) 19 x = torch.randn(10, 3, 100) 20 for xt in x: 21 h1 = cell1(xt, h1) 22 h2 = cell2(h1, h2) 23 print(h1.shape) #torch.Size([3, 30]) 24 print(h2.shape) #torch.Size([3, 20])
原文:https://www.cnblogs.com/cxq1126/p/13333899.html