用于读取或写出基本类型的变量或字符串
public class DataInputStream extends FilterInputStream implements DataInputpublic class DataOutputStream extends FilterOutputStream implements DataOutputInputStream 和 OutputStream 子类的流上DataInputStream 中的方法
boolean readBoolean()byte readByte()char readChar()float readFloat()double readDouble()short readShort()long readLong()int readInt()String readUTF()void readFully(byte[] b)void flush():清空此数据输出流。这迫使所有缓冲的输出字节被写出到流中。底层调用其基础输出流的 flush 方法DataOutputStream 中的方法:将上述的方法的 read 改为相应的 write 即可EOFException@Test
public void write() {
DataOutputStream dos = null;
try {
// 创建连接到指定文件的数据输出流对象
dos = new DataOutputStream(new FileOutputStream("destData.dat"));
dos.writeUTF("源啊"); // 写UTF字符串
dos.writeBoolean(false); // 写入布尔值
dos.writeLong(1234567890L); // 写入长整数
System.out.println("写文件成功!");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
// 关闭流对象, 关闭过滤流时, 会自动关闭它包装的底层节点流
if (dos != null) dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Test
public void read() {
DataInputStream dis = null;
try {
dis = new DataInputStream(new FileInputStream("destData.dat"));
String info = dis.readUTF();
boolean flag = dis.readBoolean();
long time = dis.readLong();
System.out.println(info);
System.out.println(flag);
System.out.println(time);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (dis != null)
try {
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
截取:《Java语言程序设计(基础篇)》
ObjectOutputStream 类保存基本类型数据或对象的机制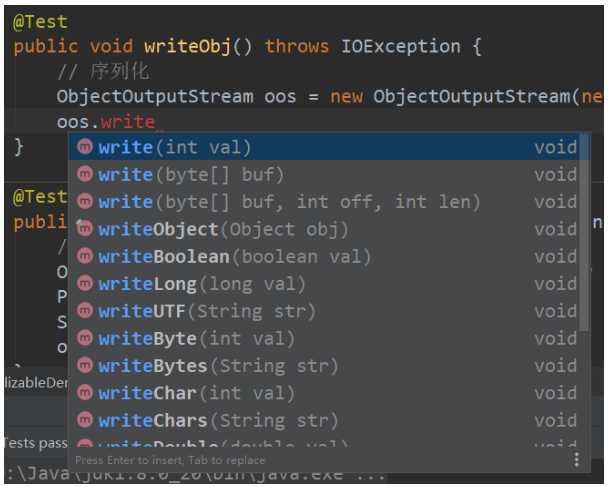
ObjectInputStream 类读取基本类型数据或对象的机制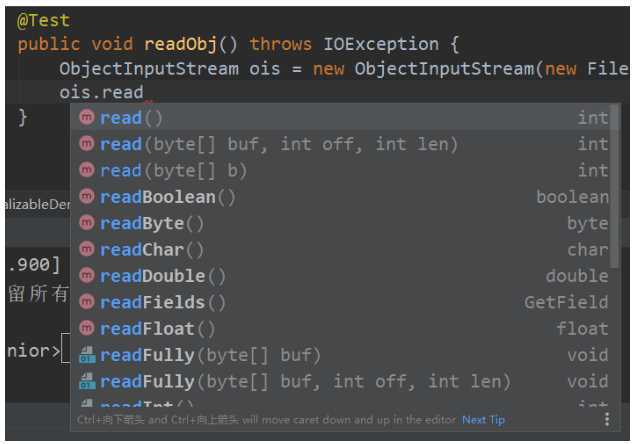
Serializable<I> 的对象转化为字节数据,使其在保存和传输时可被还原 // 序列化接口没有方法或字段,仅用于标识可序列化的语义RMI (Remote Method Invoke – 远程方法调用) 过程的参数和返回值都必须实现的机制,而 RMI 是 JavaEE 的基础。因此序列化机制是 JavaEE 平台的基础Serializable 和 Externalizable 两个接口之一。否则,会抛出 NotSerializableException
凡是实现 Serializable<I> 的类都有一个表示序列化版本标识符的静态变量:
private static final long serialVersionUID
serialVersionUID 用来表明类的不同版本间的兼容性。序列化运行时使用这个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。可序列化类可以通过声明名为 "serialVersionUID" 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID。简言之,其目的是以序列化对象进行版本控制,有关各版本反序列化时是否兼容。
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java(TM) 对象序列化规范”中所述。不过,强烈建议所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性(值是Java运行时环境根据类的内部细节自动生成的)。若类的实例变量做了修改, serialVersionUID 可能发生变化,如此一来,在反序列化过程中就有可能会导致意外的 InvalidClassException。因此,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 -- serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
简单来说,Java的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常:InvalidCastException
Serializable<I>ObjectOutputStream 和 ObjectInputStream 不能序列化 static 和 transient 修饰的成员变量
RandomAccessFile 虽声明在 java.io 包下,但直接继承于 java.lang.Object 类。并且它实现了 DataInput、DataOutput 这两个接口,也就意味着这个类既可以读也可以写RandomAccessFile 类支持 “随机访问” 的方式,程序可以直接跳到文件的任意地方来读、写文件
RandomAccessFile 对象包含一个记录指针,用以标示当前读写处的位置。类对象可以自由移动记录指针:
long getFilePointer():获取文件记录指针的当前位置void seek(long pos):将文件记录指针定位到 pos 位置public RandomAccessFile(File file, String mode)public RandomAccessFile(String name, String mode)实现向指定位置进行数据插入:
public void test3() throws IOException {
RandomAccessFile raf = new RandomAccessFile("src.txt", "rw");
raf.seek(3);
int len;
byte[] buf = new byte[1024];
// 1. 插入位置往后的数据先存起来
StringBuilder builder = new StringBuilder((int) new File("src.txt").length());
while((len = raf.read(buf)) != -1)
builder.append(new String(buf, 0, len));
// 2. 插入
raf.seek(3);
raf.write("1101".getBytes());
// 3. 将原尾部数据再写回去
raf.write(builder.toString().getBytes());
raf.close();
}
我们可以用RandomAccessFile这个类,来实现一个多线程断点下载的功能,用过下载工具的朋友们都知道,下载前都会建立两个临时文件,一个是与被下载文件大小相同的空文件,另一个是记录文件指针的位置文件,每次暂停的时候,都会保存上一次的指针,然后断点下载的时候,会继续从上一次的地方下载,从而实现断点下载或上传的功能。
public class ByteArrayOutputStream extends OutputStreamtoByteArray() 和 toString() 获取数据。相当于一个中间缓冲层,将类写入到文件等其他 OutputStream。它是对字节进行操作,属于内存操作流protected byte buf[]; // 存储数据的缓冲区
protected int count; // 缓冲区中的有效字节数
int size() 将指定的字节写入此 byte 数组输出流String toString() 用平台默认的字符集,通过解码字节将缓冲区内容转换为字符串String toString(String charsetName) 使用指定的 charsetName,通过解码字节将缓冲区内容转换为字符串void write(int b) 将指定的字节写入此 byte 数组输出流void write(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此 byte 数组输出流void writeTo(OutputStream out) 将此 byte 数组输出流的全部内容写入到指定的输出流参数中,这与使用 out.write(buf, 0, count) 调用该输出流的 write() 效果一样void close() 关闭 ByteArrayOutputStream 无效。此类中的方法在关闭此流后仍可被调用,而不会产生任何 IOException
Path<I>,代表一个平台无关的平台路径,描述了目录结构中文件的位置。Path可以看成是File类的升级版本,实际引用的资源也可以不存在。import java.io.File;
File file = new File("index.html");
import java.nio.file.Path;
import java.nio.file.Paths;
Path path = Paths.get("index.html");
java.nio.file 包下还提供了 Files、Paths 工具类,Files 包含了大量静态的工具方法来操作文件。Paths 则包含了两个返回 Path 的静态工厂方法get() 用来获取 Path 对象:
static Path get(String first, String … more) 用于将多个字符串串连成路径static Path get(URI uri):返回指定 uri 对应的 Path 路径
原文:https://www.cnblogs.com/liujiaqi1101/p/13340662.html