训练神经网络的时候,基本就是三个步骤:
在小的训练集上联系的时候,通常每次对所有样本计算Loss之后通过梯度下降的方式更新参数(批量梯度下降),但是在大的训练集时,这样每次计算所有样本的Loss再计算一次梯度更新参数的方式效率是很低的。因此就有了随机梯度下降和mini-batch梯度下降的方式。下面来具体讲讲。
上面说了,批量梯度下降就是每个epoch计算所有样本的Loss,进而计算梯度进行反向传播、参数更新:

其中,\(m\) 为训练集样本数,\(l\) 为损失函数,\(\epsilon\) 表示学习率。批量梯度下降的优缺点如下:
先贴上随机梯度下降的伪代码

随机梯度下降每次迭代(iteration)计算单个样本的损失并进行梯度下降更新参数,这样在每轮epoch就能进行 \(m\) 次参数更新。看优缺点吧:
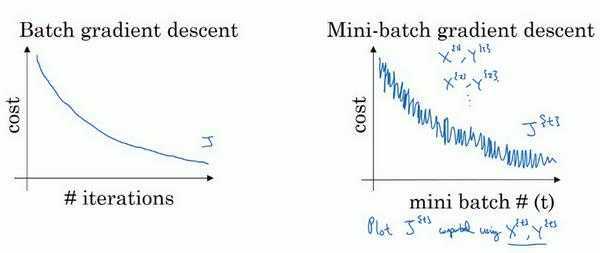
似乎随机梯度下降和批量梯度下降走向了两个计算,那么将这两种方法中和一下呢?这就得到了min-Batch Gradient Descent。

小批量梯度下降将所有的训练样本划分到 \(batches\) 个min-batch中,每个mini-batch包含 \(batch_size\) 个训练样本。每个iteration计算一个mini-batch中的样本的Loss,进而进梯度下降和参数更新,这样兼顾了批量梯度下降的准确度和随机梯度下降的更新效率。
可以看到,当 \(batch\_size=m\) 时,小批量梯度下降就变成了批量梯度下降;当 \(batch\_size=1\) ,就退化为了SGD。一般来说 \(batch\_size\) 取2的整数次方的值。
事实上,我们平时用梯度下降的时候说的最多的SGD指的是小批量梯度下降,各种论文里所说的SGD也大都指的mini-batch梯度下降这种方式。tensorflow中也是通过定义batch_size的方式在优化过程中使用小批量梯度下降的方式(当然,也取决于batch_size的设置)。
随机梯度下降、mini-batch梯度下降以及batch梯度下降
原文:https://www.cnblogs.com/rezero/p/13281899.html