前两天老师派了个活,让下载知网上根据高级搜索得到的来源文献的参考文献及引证文献数据,网上找了一些相关博客,感觉都不太合适,因此特此记录,希望对需要的人有帮助。
切入正题,先说这次需求,高级搜索,根据中图分类号,年份,来源类别条件共检索得到5000多条文献信息。
需求一:获取这5000多篇文献的基本信息
需求二:获取这5000多篇文献的参考文献信息
需求三:获取这5000多篇文献的引证文献信息
这几个需要其实也比较明确,下面几张图是本次需求涉及到的几个页面。
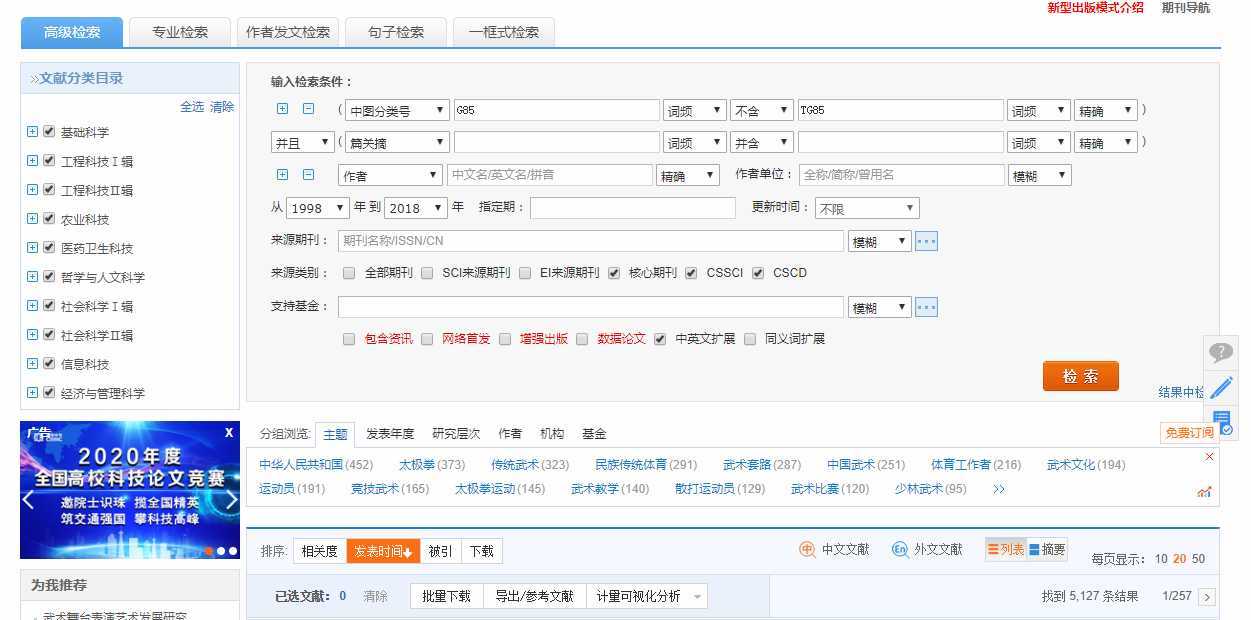
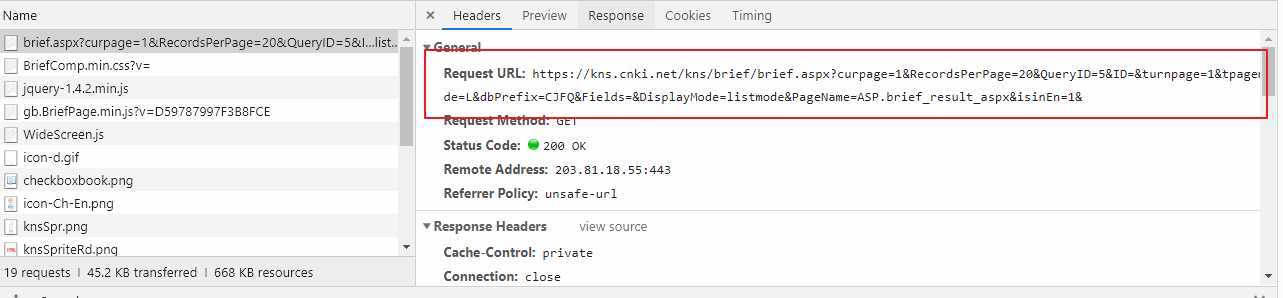
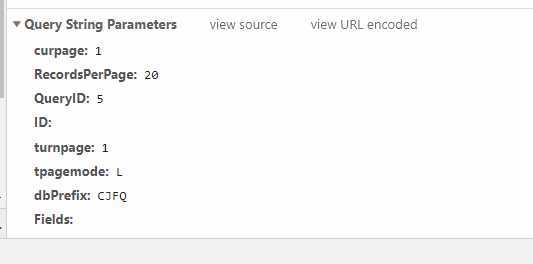
首先看一下需求一,在知网中的高级检索输入检索条件,获取检索出来的文献信息。通过点击检索按钮,发现浏览器检索框内的url并未发生变化,因此采取第二种方式,打开开发者工具->network,点击检索按钮,发现浏览器发送了两次请求,第一次是根据检索条件发送了一次post请求,返回一些参数,第二次携带参数再次发送请求获取数据。通过点击翻页按钮,可以找出变化的url信息,通过观察,发现两个重要的参数:curpage和RecordsPerPage,分别代表当前页和每页数据个数,最大个数为50,我们可以采取两次请求的方式,但显然一次检索的话直接复制浏览器中第一次请求返回的参数就可以了,只需模拟第二次请求。另外重要的一点就是,请求的时候需要携带cookie信息,否则也无法返回正确的数据。分析完成,可以开始写代码了。

def download_search_page(self): headers = { ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3‘, ‘Accept-Encoding‘: ‘gzip, deflate, br‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Cache-Control‘: ‘max-age=0‘, ‘Connection‘: ‘keep-alive‘, ‘Cookie‘: ‘Ecp_ClientId=2200630175601165678; cnkiUserKey=d6737e43-6a79-d00c-9a04-a03c2c11ee30; Ecp_IpLoginFail=200701183.202.194.16; ASP.NET_SessionId=edraumuckd12e2nqz3tywjsk; SID_kns=123113; SID_klogin=125141; SID_kinfo=125104; KNS_SortType=; SID_krsnew=125133; _pk_ref=%5B%22%22%2C%22%22%2C1593599729%2C%22https%3A%2F%2Fwww.cnki.net%2F%22%5D; _pk_ses=*; SID_kns_new=kns123113; RsPerPage=50; SID_kcms=124120; DisplaySave=0‘, ‘Host‘: ‘kns.cnki.net‘, ‘Upgrade-Insecure-Requests‘: ‘1‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘ } page = 70 while page < 104: try: url = f"https://kns.cnki.net/kns/brief/brief.aspx?curpage={page}&RecordsPerPage=50&QueryID=2&ID=&turnpage=1&tpagemode=L&dbPrefix=CJFQ&Fields=&DisplayMode=listmode&PageName=ASP.brief_result_aspx&isinEn=2&" response = requests.get(url, headers=headers) with open(f‘{self.search_html_dir}/{page}.html‘, mode=‘w‘, encoding=‘utf-8‘) as f: f.write(response.text) print(f‘{page} 下载完成‘) if self.get_file_size(f"{self.search_html_dir}/{page}.html") < 50: raise Exception("cookie失效") page += 1 except Exception as e: print(f‘{page}下载失败\t正在睡眠 请耐心等待‘, ) time.sleep(30) def parse_search_article_info(self): for file in os.listdir(self.search_html_dir): file_path = os.path.join(self.search_html_dir, file) items = [] try: text = self.read_html(file_path) response = HTML(text) tr_list = response.xpath(‘//table[@class="GridTableContent"]/tr[@bgcolor]‘) for tr in tr_list: item = {} item[‘title‘] = tr.xpath(‘td[2]/a/text()‘)[0] href = tr.xpath(‘td[2]/a/@href‘)[0] params = parse_qs(urlparse(href).query) dbcode = params[‘DbCode‘][0] dbname = params[‘dbname‘][0] filename = params[‘filename‘][0] item[‘filename‘] = filename item[ ‘article_url‘] = f‘https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode={dbcode}&dbname={dbname}&filename={filename}‘ item[‘authors‘] = ‘; ‘.join(tr.xpath(‘td[@class="author_flag"]/a/text()‘)) item[‘journal‘] = tr.xpath(‘td[@class="cjfdyxyz"]/a/text()‘)[0].strip() item[‘publish_time‘] = tr.xpath(‘td[5]/text()‘)[0].strip().split()[0] try: item[‘cited_num‘] = tr.xpath(‘td[6]/span[@class="KnowledgeNetcont"]/a/text()‘)[0] except IndexError: item[‘cited_num‘] = 0 try: item[‘download_num‘] = tr.xpath(‘td[7]/span[@class="downloadCount"]/a/text()‘)[0] except IndexError: item[‘download_num‘] = 0 items.append(item) df = DataFrame(data=items) df.set_index(keys=‘filename‘, inplace=True) df.to_sql("paper_info", con=self.conn, if_exists=‘append‘) print(f‘{file_path}\t解析完成‘) except Exception as e: print(f‘{file_path}\t插入失败‘) traceback.print_exc()
另外,这些信息还不够全面,比如关键词,摘要这些还需要通过详情页面获取,我们可以通过第一次获取的文章url来得到其他信息。
def spider_article_detail_page(self): if len(os.listdir(self.paper_html_dir)) > 0: files = {file.replace(‘.html‘, ‘‘) for file in os.listdir(self.paper_html_dir)} files = "(‘" + "‘,‘".join(files) + "‘)" paper_info = read_sql(f"SELECT article_url FROM paper_info where filename not in {files}", con=self.conn) else: paper_info = read_sql(f"SELECT article_url FROM paper_info", con=self.conn) with ThreadPoolExecutor() as pool: pool.map(self.download_article_detail, paper_info[‘article_url‘]) # paper_info[‘article_url‘].apply(self.download_article_detail) def download_article_detail(self, url): filename = parse_qs(urlparse(url).query)[‘filename‘][0] filepath = f‘{self.paper_html_dir}/{filename}.html‘ response = requests.get(url) self.write_html(response.text, filepath) if self.get_file_size(file_path=filepath) < 5: print(f‘{url}\t下载失败‘) exit() print(f‘{url}\t下载完成‘) def parse_article_detail(self): f = open(‘error.txt‘, mode=‘a‘) for file in os.listdir(self.paper_html_dir): filename = file.replace(‘.html‘, ‘‘) file_path = os.path.join(self.paper_html_dir, file) try: text = self.read_html(file_path) response = HTML(text) institution = ‘; ‘.join(response.xpath(‘//div[@class="orgn"]/span/a/text()‘)) try: summary = response.xpath(‘//span[@id="ChDivSummary"]/text()‘)[0] except IndexError: summary = ‘‘ keywords = ‘ ‘.join([word.strip() for word in response.xpath( ‘//label[@id="catalog_KEYWORD"]/following-sibling::a/text()‘)]).strip(‘;‘) try: cls_num = response.xpath(‘//label[@id="catalog_ZTCLS"]/parent::p/text()‘)[0] except IndexError: cls_num = ‘‘ self.db.execute( "update paper_info set summary=?, institution=?, keywords=?, cls_num=? where filename=?", params=(summary, institution, keywords, cls_num, filename)) print(f‘{filename} 更新完毕‘) except Exception as e: print(f‘{filename} 更新失败‘, e) f.write(f‘{file_path}\n‘) f.close()
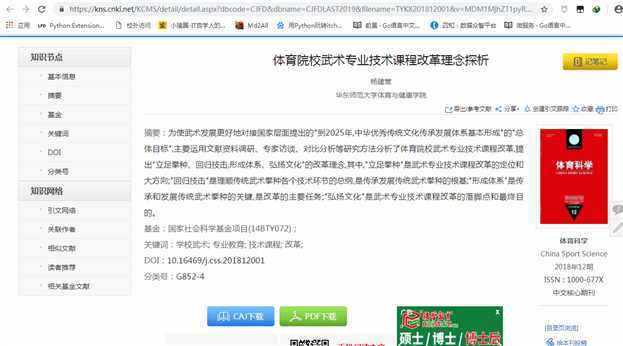

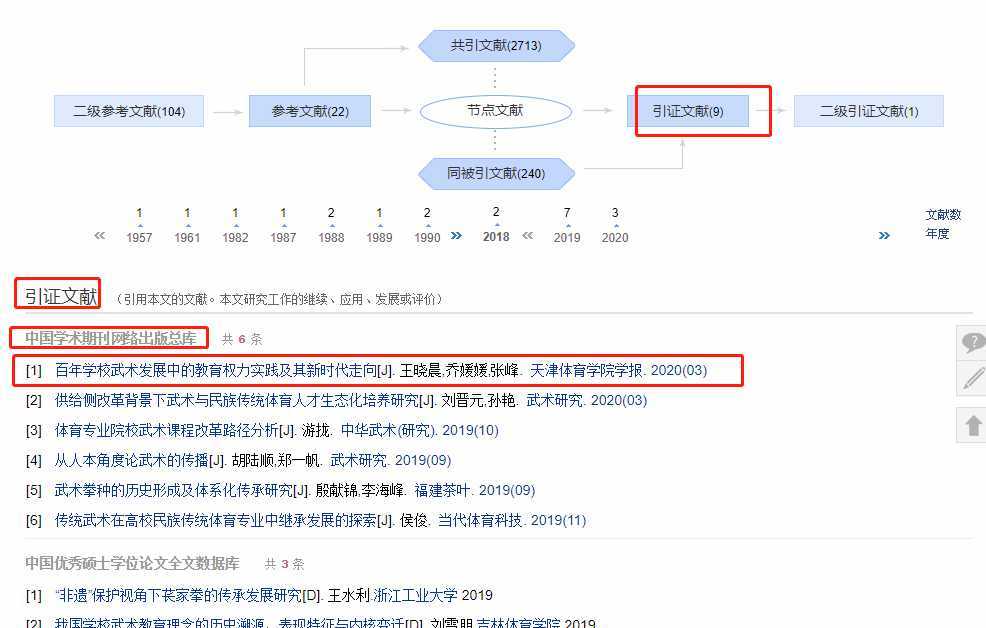
接下来看需求二和需求三,获取文献的参考文献信息,这时通过点击文章页面的参考文献,观察请求信息的变化,发现和文章url相比,参数中多了一个RefType,参考文献等于1,引证危险等于3。请求的时候需要携带refer信息,refer信息我们设置为当前文章url。开始写代码:
def download_article_refer_cited_page(self): paper_info = read_sql(f"SELECT article_url FROM paper_info", con=self.conn) self.error_f = open(‘error.txt‘, mode=‘w‘) with ThreadPoolExecutor() as pool: pool.map(self.download_reference_page, paper_info[‘article_url‘]) pool.map(self.download_cited_page, paper_info[‘article_url‘]) self.error_f.close() def download_reference_page(self, url): """ 下载指定文章参考文献页面 :param url: :return: """ query = urlparse(url).query filename = parse_qs(query)[‘filename‘][0] refer_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=1&vl=" try: headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘, ‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘, } response = requests.get(refer_url, headers=headers) if response.status_code == 200: self.write_html(response.text, f‘{self.paper_refer_html_dir}/{filename}.html‘) else: raise Exception(f"请求异常, 状态码为:{response.status_code}") except Exception as e: self.error_f.write(refer_url + ‘\n‘) print(f‘{refer_url}\t下载失败‘, e) def download_cited_page(self, url): query = urlparse(url).query filename = parse_qs(query)[‘filename‘][0] cited_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=3&vl=" try: headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘, ‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘, } response = requests.get(cited_url, headers=headers) if response.status_code == 200: self.write_html(response.text, f‘{self.paper_cited_html_dir}/{filename}.html‘) else: raise Exception(f"请求异常, 状态码为:{response.status_code}") except Exception as e: self.error_f.write(cited_url + ‘\n‘) print(f‘{cited_url}\t下载失败‘, e) def get_error_refer_cited_page(self): with open(‘error.txt‘) as f: for line in f: url = line.strip() if url.endswith("RefType=3&vl="): self.download_cited_page(url.replace("RefType=3&vl=", "")) elif url.endswith("RefType=1&vl="): self.download_reference_page(url.replace("RefType=1&vl=", "")) def get_all_refer_cited_page_url(self): f = open(‘more_refer_cited_url.txt‘, mode=‘a‘) for file_path in self.get_dir_all_files(self.paper_refer_html_dir, self.paper_cited_html_dir): filename = file_path.split(‘\\‘)[-1].replace(‘.html‘, ‘‘) req_type = 1 if file_path.__contains__(‘refer‘) else 3 response = HTML(self.read_html(file_path)) nodes = response.xpath(‘//span[@name="pcount"]‘) for node in nodes: pcount = int(node.xpath(‘text()‘)[0]) if pcount > 10: article_url = self.db.fetchone(f"select article_url from paper_info where filename=?", params=(filename,))[0] query = urlparse(article_url).query pages = int(pcount / 10) + 1 CurDBCode = node.xpath(‘@id‘)[0].replace(‘pc_‘, ‘‘) for page in range(2, pages + 1): url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType={req_type}&vl=&CurDBCode={CurDBCode}&page={page}" f.write(f‘{url}\n‘) print(f‘{url}\t写入成功‘) f.close() def download_all_refer_cited_page(self): self.error_f = open(‘error.txt‘, mode=‘w‘) def download_page(url): query = parse_qs(urlparse(url).query) page = query[‘page‘][0] CurDbCode = query[‘CurDBCode‘][0] filename = query[‘filename‘][0] refType = query[‘RefType‘][0] if refType == ‘1‘: file_path = f‘{self.paper_refer_html_dir}/{filename}_{CurDbCode}_{page}.html‘ else: file_path = f‘{self.paper_cited_html_dir}/{filename}_{CurDbCode}_{page}.html‘ try: headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘, ‘Referer‘: url, } response = requests.get(url, headers=headers) if response.status_code == 200: self.write_html(response.text, file_path) else: raise Exception(f"请求异常, 状态码为:{response.status_code}") except Exception as e: self.error_f.write(url + ‘\n‘) print(f‘{url}\t下载失败‘, e) with open(‘more_refer_cited_url.txt‘) as f: urls = [line.strip() for line in f] with ThreadPoolExecutor() as pool: pool.map(download_page, urls) self.error_f.close() def download_all_error_refer_cited_page(self): with open(‘error.txt‘) as f: for line in f: url = line.strip() query = parse_qs(urlparse(url).query) page = query[‘page‘][0] CurDbCode = query[‘CurDBCode‘][0] filename = query[‘filename‘][0] refType = query[‘RefType‘][0] if refType == ‘1‘: file_path = f‘{self.paper_refer_html_dir}/{filename}_{CurDbCode}_{page}.html‘ else: file_path = f‘{self.paper_cited_html_dir}/{filename}_{CurDbCode}_{page}.html‘ try: headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘, ‘Referer‘: url, } response = requests.get(url, headers=headers) if response.status_code == 200: self.write_html(response.text, file_path) print(f‘{url}\t下载成功‘) else: raise Exception(f"请求异常, 状态码为:{response.status_code}") except Exception as e: print(f‘{url}\t下载失败‘, e)
接下来是解析页面信息,这里面的难点是对参考文献和引证文献标注的格式不同类别不一样,需要单独进行正则匹配,不过我这里已经处理好了,可以直接拿来用。
def get_article_refer_num(self): def parse_refer_num(filename): try: response1 = HTML(self.read_html(f‘{self.paper_refer_html_dir}/{filename}.html‘)) refer_pcounts = response1.xpath(‘//span[@name="pcount"]/text()‘) if refer_pcounts: refer_num = sum(int(num) for num in refer_pcounts) else: refer_num = 0 self.db.execute("update paper_info set refer_num=? where filename=?", params=(refer_num, filename)) print(f‘{filename}\t{refer_num}‘) except Exception as e: print(f‘{filename}\t解析失败‘, e) paper_info = read_sql(f"SELECT filename FROM paper_info", con=self.conn) paper_info[‘filename‘].apply(parse_refer_num) @timeit def parse_refer_cited_info(self): self.error_f = open(‘error.txt‘, mode=‘a‘) refer_file_list = [] cited_file_list = [] for file in self.get_dir_all_files(self.paper_refer_html_dir, self.paper_cited_html_dir): if file.__contains__(‘refer‘): refer_file_list.append(file) elif file.__contains__(‘cited‘): cited_file_list.append(file) refer_data_list = [] for file in refer_file_list: self.parse_reference_cited_article_detail(file, relation=‘参考文献‘, data_list=refer_data_list) refer_data = DataFrame(data=refer_data_list) refer_data.drop_duplicates(subset=[‘origin_article‘, ‘dbcode‘, ‘pid‘, ‘relation‘], inplace=True) refer_data.to_csv(‘res/参考文献.csv‘, index=False, encoding=‘utf_8_sig‘) # refer_data.to_sql("reference_article", con=self.conn, if_exists=‘append‘, index=False) cited_data_list = [] for file in cited_file_list: self.parse_reference_cited_article_detail(file, relation=‘引证文献‘, data_list=cited_data_list) cited_data = DataFrame(data=cited_data_list) print(cited_data.info()) cited_data.drop_duplicates(subset=[‘origin_article‘, ‘dbcode‘, ‘pid‘, ‘relation‘], inplace=True) print(cited_data.info()) cited_data.to_csv(‘res/引证文献.csv‘, index=False, encoding=‘utf_8_sig‘) # cited_data.to_sql("cited_article", con=self.conn, if_exists=‘append‘, index=False) self.error_f.close() def parse_reference_cited_article_detail(self, file, relation, data_list): filename = file.split(‘\\‘)[-1].replace(‘.html‘, ‘‘) if len(filename.split(‘_‘)) > 1: filename = filename.split(‘_‘, maxsplit=1)[0] response = HTML(self.read_html(file)) essayBoxs = response.xpath(‘//div[@class="essayBox"]‘) for box in essayBoxs: db_title = box.xpath(‘div[@class="dbTitle"]/text()‘)[0] db_code = box.xpath(‘div[@class="dbTitle"]/b/span[@name="pcount"]/@id‘)[0].replace(‘pc_‘, ‘‘) essays = box.xpath(‘ul[contains(@class, "ebBd")]/li‘) for essay in essays: item = ArticleItem() item.relation = relation item.origin_article = filename item.dbcode = db_code item.dbtitle = db_title try: item.pid = essay.xpath(‘em[1]/text()‘)[0].strip().replace(‘[‘, ‘‘).replace(‘]‘, ‘‘) except IndexError: continue if db_code == ‘CBBD‘: info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘) try: res = re.search(‘(.*?)\[(.*?)\]\.(.*?),(.*?),(\d{4})‘, info) item.title = res.group(1) item.article_type = res.group(2) item.journal = res.group(3) item.author = res.group(4) item.year = res.group(5) except AttributeError as e: res = re.search(‘(.*?)\[(.*?)\]\.(.*?),(.*?),‘, info) item.title = res.group(1) item.article_type = res.group(2) item.journal = res.group(3) item.author = res.group(4) elif db_code == ‘CJFQ‘: try: item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = ‘‘ text_info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace( ‘  ‘, ‘‘).replace(‘.‘, ‘‘).replace(‘,‘, ‘;‘) res = re.search(‘\[(.*?)\] (.*)‘, text_info) article_type, author = res.group(1), res.group(2) item.article_type = article_type.replace(‘[‘, ‘‘).replace(‘]‘, ‘‘) item.author = author.replace(‘;‘, ‘; ‘) item.journal = essay.xpath(‘a[2]/text()‘)[0] item.year = essay.xpath(‘a[3]/text()‘)[0][:4] except IndexError: text_info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace( ‘  ‘, ‘‘) try: res = re.search(‘(.*?)\[(.*?)\]\. (.*)\.(.*?)\.(\d{4})‘, text_info) item.title = res.group(1) item.article_type = res.group(2) item.author = res.group(3).replace(‘,‘, ‘; ‘) item.journal = res.group(4) item.year = res.group(5) except AttributeError: try: res = re.search(‘(.*?)\[(.*?)\]\. (.*?)\.(\d{4})‘, text_info) item.title = res.group(1) item.article_type = res.group(2) item.journal = res.group(3) item.year = res.group(4) except AttributeError: continue elif db_code == ‘CDFD‘ or db_code == ‘CMFD‘: try: item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = ‘‘ info = ‘‘.join(essay.xpath(‘text()‘)).replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘) # try: res = re.search(‘\[(.*?)\]\.(.*?)\.(\d{4})‘, info) item.article_type = res.group(1) item.author = res.group(2) item.year = res.group(3) item.institution = essay.xpath(‘a[2]/text()‘)[0] except IndexError: continue elif db_code == ‘CPFD‘: item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = ‘‘ info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘) res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?)\.(\d{4})‘, info) item.article_type = res.group(1) item.journal = res.group(3) item.author = res.group(2) item.year = res.group(4) elif db_code == ‘SSJD‘: item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = ‘‘ info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(‘  ‘, ‘‘) try: res = re.search(‘\[(.*?)\] \. (.*)\.(.*?) \.(\d{4})‘, info) item.article_type = res.group(1) item.journal = res.group(3) item.author = res.group(2).replace(‘,‘, ‘; ‘) item.year = res.group(4) except AttributeError: res = re.search(‘\[(.*?)\] \. (.*?) \.(\d{4})‘, info) item.article_type = res.group(1) item.journal = res.group(2) item.year = res.group(3) elif db_code == ‘CRLDENG‘: try: item.title = essay.xpath(‘a[1]/text()‘)[0] info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(‘  ‘, ‘‘) try: res = re.search(‘\. (.*?)\. (.*?)\. (\d{4})‘, info) item.author = res.group(1).replace(‘,‘, ‘; ‘) item.journal = res.group(2) item.year = res.group(3) except AttributeError: try: res = re.search(‘\. (.*)\. (.*?) (\d{4})‘, info) item.author = res.group(1).replace(‘,‘, ‘; ‘) item.journal = res.group(2) item.year = res.group(3) except AttributeError: try: res = re.search(‘\. (.*)\. (.*?)\.‘, info) item.author = res.group(1).replace(‘,‘, ‘; ‘) item.journal = res.group(2) except AttributeError: try: res = re.search(‘ (.*)\. (.*?)\. (\d{4})‘, info) item.author = res.group(1) item.title = res.group(2) item.year = res.group(3) except AttributeError: try: res = re.search(‘\.(.*?)\. (\d{4})‘, info) item.url = res.group(1) item.year = res.group(2) except AttributeError: try: item.year = re.search(‘(\d{4})‘, info).group(1) except AttributeError: item.url = info.strip(‘.‘) except IndexError: info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(‘  ‘, ‘‘) try: res = re.search(‘(.*)\. (.*?)\. (\d{4})‘, info) item.author = res.group(1).replace(‘,‘, ‘; ‘) item.title = res.group(2) item.year = res.group(3) except AttributeError: try: res = re.search(‘(.*)\. (\d{4})‘, info) item.title = res.group(1) item.year = res.group(2) except AttributeError: item.url = info.strip(‘.‘) elif db_code == ‘CCND‘: item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = "" info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace( ‘  ‘, ‘‘) try: res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?)\.(\d{4})‘, info) item.article_type = res.group(1) item.author = res.group(2).replace(‘,‘, ‘; ‘) item.journal = res.group(3) item.year = res.group(4) except AttributeError: res = re.search(‘\[(.*?)\]\.(.*?)\.(\d{4})‘, info) item.article_type = res.group(1) item.journal = res.group(2) item.year = res.group(3) elif db_code == ‘CYFD‘: # XNZS201112009 item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = "" info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace( ‘  ‘, ‘‘) res = re.search(‘\[(.*?)\]\. (.*?)\.‘, info) item.article_type = res.group(1) item.journal = res.group(2) elif db_code == ‘IPFD‘: item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = "" info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace( ‘  ‘, ‘‘) try: res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?)\.(\d{4})‘, info) item.article_type = res.group(1) item.author = res.group(2).replace(‘,‘, ‘; ‘) item.journal = res.group(3) item.year = res.group(4) except AttributeError: res = re.search(‘\[(.*?)\]\.(.*?)\.(\d{4})‘, info) item.article_type = res.group(1) item.journal = res.group(2) item.year = res.group(3) elif db_code == ‘SCPD‘: # TIRE20130201 item.title = essay.xpath(‘a[1]/text()‘)[0] article_url = essay.xpath(‘a[1]/@href‘) if article_url: item.article_url = ‘https://kns.cnki.net/‘ + article_url[0] else: item.article_url = "" info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace( ‘  ‘, ‘‘) res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?):(.*?),‘, info) item.article_type = res.group(1) item.author = res.group(2).replace(‘,‘, ‘; ‘) item.journal = res.group(3) item.patent_num = res.group(4) else: self.error_f.write(f‘{db_code}\t{filename}\t类型异常\n‘) print(f‘{db_code}\t{filename}\t类型异常\n‘) data_list.append(item.__dict__)
后来又有一个需求,就是获取参考文献和引证文献的详情数据,毕竟标注的参考文献和引证文献信息不全。关键是要取得这些文献的url,好在之前获取了这个字段,可以很轻松的完成本次任务。
def spider_refer_cited_detail_page(self): self.error_f = open(‘error.txt‘, mode=‘w‘) if os.path.exists("refer_url.xlsx"): refer_data = read_excel(‘refer_url.xlsx‘) refer_data[‘dir_path‘] = self.refer_paper_dir if len(os.listdir(self.refer_paper_dir)) > 0: refer_ids = {int(file.replace(‘.html‘, ‘‘)) for file in os.listdir(self.refer_paper_dir)} refer_data = refer_data[~refer_data[‘index‘].isin(refer_ids)] else: refer_data = read_sql("select distinct article_url from reference_article where article_url != ‘‘;", con=self.conn) refer_data.reset_index(inplace=True) refer_data.to_excel(‘refer_url.xlsx‘, index=False) refer_data[‘dir_path‘] = self.refer_paper_dir if os.path.exists(‘cited_url.xlsx‘): cited_data = read_excel(‘cited_url.xlsx‘) cited_data[‘dir_path‘] = self.cited_paper_dir if len(os.listdir(self.cited_paper_dir)) > 0: cited_ids = {int(file.replace(‘.html‘, ‘‘)) for file in os.listdir(self.cited_paper_dir)} cited_data = cited_data[~cited_data[‘index‘].isin(cited_ids)] else: cited_data = read_sql("select distinct article_url from cited_article where article_url != ‘‘;", con=self.conn) cited_data.reset_index(inplace=True) cited_data.to_excel(‘cited_url.xlsx‘, index=False) cited_data[‘dir_path‘] = self.cited_paper_dir def download_paper_page(row): index, url, dir_path= row[0], row[1], row[2] file_path = f‘{dir_path}/{index}.html‘ response = requests.get(url) self.write_html(response.text, file_path) if self.get_file_size(file_path=file_path) < 5: print(f‘{file_path}\t下载失败‘) self.error_f.write(f‘{index},{url},{dir_path}\n‘) else: print(f‘{file_path}\t下载完成‘) with ThreadPoolExecutor() as pool: pool.map(download_paper_page, refer_data.values) with ThreadPoolExecutor() as pool: pool.map(download_paper_page, cited_data.values) self.error_f.close() def parse_refer_cited_detail_info(self): self.error_f = open(‘error.txt‘, mode=‘w‘) refer_data = read_excel(‘refer_url.xlsx‘) refer_data[‘dir_path‘] = self.refer_paper_dir cited_data = read_excel(‘cited_url.xlsx‘) cited_data[‘dir_path‘] = self.cited_paper_dir def parse_paper_page(row): index, url, dir_path = row[0], row[1], row[2] file_path = f‘{dir_path}/{index}.html‘ try: text = self.read_html(file_path) response = HTML(text) try: title = response.xpath(‘//div[@class="wxTitle"]/h2[@class="title"]/text()‘)[0] institution = ‘; ‘.join(response.xpath(‘//div[@class="orgn"]/span/a/text()‘)) except IndexError: return try: summary = response.xpath(‘//span[@id="ChDivSummary"]/text()‘)[0] except IndexError: summary = ‘‘ keywords = ‘ ‘.join([word.strip() for word in response.xpath( ‘//label[@id="catalog_KEYWORD"]/following-sibling::a/text()‘)]).strip(‘;‘) try: cls_num = response.xpath(‘//label[@id="catalog_ZTCLS"]/parent::p/text()‘)[0] except IndexError: cls_num = ‘‘ if "refer" in dir_path: self.db.execute("update reference_article set title=?, summary=?, institution=?, keywords=?, cls_num=? where article_url=?", params=(title, summary, institution, keywords, cls_num, url)) elif "cited" in dir_path: self.db.execute("update cited_article set title=?, summary=?, institution=?, keywords=?, cls_num=? where article_url=?", params=(title, summary, institution, keywords, cls_num, url)) print(f‘{file_path} 更新完毕‘) except Exception as e: print(f‘{url} 更新失败‘, e) traceback.print_exc() self.error_f.write(f‘{index},{url},{file_path}\n‘) refer_data.apply(parse_paper_page, axis=1) cited_data.apply(parse_paper_page, axis=1) def get_refer_cited_paper_page(self): def download_refer_num(row): index, url, dir_path = row[0], row[1], row[2] query = urlparse(url).query if "refer" in dir_path: file_path = f‘{self.refer_refer}/{index}.html‘ elif "cited" in dir_path: file_path = f‘{self.cited_refer}/{index}.html‘ refer_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=1&vl=" try: headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘, ‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘, } response = requests.get(refer_url, headers=headers) if response.status_code == 200: self.write_html(response.text, file_path) print(f‘{file_path}\t下载完成‘) else: raise Exception(f"请求异常, 状态码为:{response.status_code}") except Exception as e: self.error_f.write(f‘{index},{url},{dir_path}\n‘) print(f‘{url}\t下载失败‘, e) # traceback.print_exc() def download_cited_num(row): index, url, dir_path = row[0], row[1], row[2] query = urlparse(url).query cited_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=3&vl=" if "refer" in dir_path: file_path = f‘{self.refer_cited}/{index}.html‘ elif "cited" in dir_path: file_path = f‘{self.cited_cited}/{index}.html‘ try: headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘, ‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘, } response = requests.get(cited_url, headers=headers) if response.status_code == 200: self.write_html(response.text, file_path) print(f‘{file_path}\t下载完成‘) else: raise Exception(f"请求异常, 状态码为:{response.status_code}") except Exception as e: self.error_f.write(f‘{index},{url},{dir_path}\n‘) print(f‘{url}\t下载失败‘, e) # traceback.print_exc() refer_list = [] cited_list = [] with open(‘error.txt‘) as f: for line in f: row = line.strip().split(‘,‘) if ‘html/refer_paper‘ in line: refer_list.append(row) if ‘html/cited_paper‘ in line: cited_list.append(row) if len(refer_list) > 0 or len(cited_list) > 0: self.error_f = open(‘error1.txt‘, mode=‘w‘) with ThreadPoolExecutor() as pool: pool.map(download_refer_num, refer_list) pool.map(download_cited_num, refer_list) pool.map(download_refer_num, cited_list) pool.map(download_cited_num, cited_list) else: refer_data = read_excel(‘refer_url.xlsx‘) refer_data[‘dir_path‘] = self.refer_paper_dir cited_data = read_excel(‘cited_url.xlsx‘) cited_data[‘dir_path‘] = self.cited_paper_dir with ThreadPoolExecutor() as pool: pool.map(download_refer_num, refer_data.values) pool.map(download_cited_num, refer_data.values) pool.map(download_refer_num, cited_data.values) pool.map(download_cited_num, cited_data.values) self.error_f.close() def parse_refer_cited_page_refer_cited_num(self): self.error_f = open(‘error4.txt‘, mode=‘w‘) def parse_num(file_path): if os.path.exists(file_path): text = self.read_html(file_path) html = HTML(text) pcounts = html.xpath(‘//span[@name="pcount"]/text()‘) if pcounts: cited_num = sum(int(num) for num in pcounts) else: cited_num = 0 return cited_num return ‘fne‘ def parse_refer_cited_num(row): index, url, dir_path = row[0], row[1], row[2] if "refer" in dir_path: refer_file_path = f‘{self.refer_refer}/{index}.html‘ cited_file_path = f‘{self.refer_cited}/{index}.html‘ elif "cited" in dir_path: refer_file_path = f‘{self.cited_refer}/{index}.html‘ cited_file_path = f‘{self.cited_cited}/{index}.html‘ refer_num = parse_num(refer_file_path) cited_num = parse_num(cited_file_path) try: if refer_num != ‘fne‘ and cited_num != ‘fne‘: if "refer" in dir_path: self.db.execute("update reference_article set refer_num=?, cited_num=? where article_url=?", params=(refer_num, cited_num, url)) elif "cited" in dir_path: self.db.execute("update cited_article set refer_num=?, cited_num=? where article_url=?", params=(refer_num, cited_num, url)) print(f‘{dir_path}\t{index}\t{refer_num}\t{cited_num}\t插入成功‘) else: self.error_f.write(f‘{index},{url},{dir_path}\n‘) print(refer_file_path + ‘文件不存在‘) except Exception as e: self.error_f.write(f‘{index},{url},{dir_path}\n‘) traceback.print_exc() refer_data = read_excel(‘refer_url.xlsx‘) refer_data[‘dir_path‘] = self.refer_paper_dir cited_data = read_excel(‘cited_url.xlsx‘) cited_data[‘dir_path‘] = self.cited_paper_dir refer_data.apply(parse_refer_cited_num, axis=1) cited_data.apply(parse_refer_cited_num, axis=1) self.error_f.close()
最后由于本次存储方式用的sqlite数据库,所以最后将sql数据导出数据到excel文件。大工告成!
def export_to_file(self):
refer_data = read_sql("reference_article", con=self.conn)
refer_data.drop(columns=[‘index‘], inplace=True)
with ExcelWriter(‘res/参考文献.xlsx‘, engine=‘xlsxwriter‘, options={‘strings_to_urls‘: False}) as writer:
refer_data.to_excel(writer, sheet_name=‘Sheet1‘, index=False)
writer.save()
cited_data = read_sql("cited_article", con=self.conn)
cited_data.drop(columns=[‘index‘], inplace=True)
with ExcelWriter(‘res/引证文献.xlsx‘, engine=‘xlsxwriter‘, options={‘strings_to_urls‘: False}) as writer:
cited_data.to_excel(writer, sheet_name=‘Sheet1‘, index=False)
writer.save()
最后放上完整代码。全部代码大约1000行,哈哈,还是可以的!实际使用的过程中,需要根据自己的需求做适当修改,不过基本逻辑和实现都是现成的,可以直接拿来用。
# -*- coding: utf-8 -*-
"""
Datetime: 2020/07/02
Author: Zhang Yafei
Description:
"""
from DBUtils.PooledDB import PooledDB
import threading
lock = threading.Lock()
class DBPoolHelper(object):
def __init__(self, dbname, user=None, password=None, db_type=‘postgressql‘, host=‘localhost‘, port=5432):
"""
# sqlite3
# 连接数据库文件名,sqlite不支持加密,不使用用户名和密码
import sqlite3
config = {"datanase": "path/to/your/dbname.db"}
pool = PooledDB(sqlite3, maxcached=50, maxconnections=1000, maxusage=1000, **config)
# mysql
import pymysql
pool = PooledDB(pymysql,5,host=‘localhost‘, user=‘root‘,passwd=‘pwd‘,db=‘myDB‘,port=3306) #5为连接池里的最少连接数
# postgressql
import psycopg2
POOL = PooledDB(creator=psycopg2, host="127.0.0.1", port="5342", user, password, database)
# sqlserver
import pymssql
pool = PooledDB(creator=pymssql, host=host, port=port, user=user, password=password, database=database, charset="utf8")
:param type:
"""
if db_type == ‘postgressql‘:
import psycopg2
pool = PooledDB(creator=psycopg2, host=host, port=port, user=user, password=password, database=dbname)
elif db_type == ‘mysql‘:
import pymysql
pool = PooledDB(pymysql, 5, host=‘localhost‘, user=‘root‘, passwd=‘pwd‘, db=‘myDB‘,
port=3306) # 5为连接池里的最少连接数
elif db_type == ‘sqlite‘:
import sqlite3
config = {"database": dbname}
pool = PooledDB(sqlite3, maxcached=50, maxconnections=1000, maxusage=1000, **config)
else:
raise Exception(‘请输入正确的数据库类型, db_type="postgresql" or db_type="mysql" or db_type="sqlite"‘)
self.conn = pool.connection()
self.cursor = self.conn.cursor()
def __connect_close(self):
"""关闭连接"""
self.cursor.close()
self.conn.close()
def execute(self, sql, params=tuple()):
self.cursor.execute(sql, params) # 执行这个语句
self.conn.commit()
def execute_many(self, sql, params=tuple()):
self.cursor.executemany(sql, params)
self.conn.commit()
def fetchone(self, sql, params=tuple()):
self.cursor.execute(sql, params)
data = self.cursor.fetchone()
return data
def fetchall(self, sql, params=tuple()):
self.cursor.execute(sql, params)
data = self.cursor.fetchall()
return data
def __del__(self):
print("dbclass del ----------------")
self.__connect_close()
# -*- coding: utf-8 -*-
"""
Datetime: 2020/07/01
Author: Zhang Yafei
Description:
"""
import os
import re
import time
import traceback
from concurrent.futures import ThreadPoolExecutor
from functools import wraps
from urllib.parse import urlparse, parse_qs
import requests
from lxml.etree import HTML
from pandas import DataFrame, read_sql, read_excel, read_csv, ExcelWriter
from sqlalchemy import create_engine
from DBHelper import DBPoolHelper
def timeit(func):
"""
装饰器: 判断函数执行时间
:param func:
:return:
"""
@wraps(func)
def inner(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
end = time.time() - start
if end < 60:
print(f‘花费时间:\t{round(end, 2)}秒‘)
else:
min, sec = divmod(end, 60)
print(f‘花费时间\t{round(min)}分\t{round(sec, 2)}秒‘)
return ret
return inner
class ArticleItem(object):
def __init__(self):
self.origin_article = ""
self.dbtitle = ""
self.dbcode = ""
self.title = ""
self.article_type = ""
self.author = ""
self.journal = ""
self.institution = ""
self.article_url = ""
self.year = None
self.pid = None
self.url = ""
self.relation = None
class CnkiSpider(object):
def __init__(self, dbname=‘sqlite3.db‘, user=None, password=None, db_type=‘sqlite‘, host=‘localhost‘, port=None):
self.search_html_dir = ‘html/search‘
self.paper_html_dir = ‘html/paper‘
self.paper_refer_html_dir = ‘html/refer‘
self.paper_cited_html_dir = ‘html/cited‘
self.refer_paper_dir = ‘html/refer_paper‘
self.cited_paper_dir = ‘html/cited_paper‘
self.refer_refer = ‘html/refer_refer_paper‘
self.refer_cited = ‘html/refer_cited_paper‘
self.cited_refer = ‘html/cited_refer_paper‘
self.cited_cited = ‘html/cited_cited_paper‘
self.db = self.init_db(db_type=db_type, dbname=dbname)
self.conn = self.init_pandas_db()
self.error_f = None
@staticmethod
def init_db(db_type, dbname):
return DBPoolHelper(db_type=db_type, dbname=dbname)
@staticmethod
def init_pandas_db():
"""
‘postgresql://postgres:0000@127.0.0.1:5432/xiaomuchong‘
"mysql+pymysql://root:0000@127.0.0.1:3306/srld?charset=utf8mb4"
"sqlite: ///sqlite3.db"
"""
engine = create_engine("sqlite:///sqlite3.db")
conn = engine.connect()
return conn
@staticmethod
def get_file_size(file_path):
return int(os.path.getsize(file_path) / 1024)
@staticmethod
def get_dir_all_files(*dir_path_list):
for dir_path in dir_path_list:
for base_path, folders, files in os.walk(dir_path):
for file in files:
file_path = os.path.join(base_path, file)
yield file_path
@staticmethod
def read_html(file):
with open(file, encoding=‘utf-8‘) as f:
return f.read()
@staticmethod
def write_html(text, file):
with open(file, mode=‘w‘, encoding=‘utf-8‘) as f:
f.write(text)
def download_search_page(self):
headers = {
‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘,
‘Cache-Control‘: ‘max-age=0‘,
‘Connection‘: ‘keep-alive‘,
‘Cookie‘: ‘Ecp_ClientId=2200630175601165678; cnkiUserKey=d6737e43-6a79-d00c-9a04-a03c2c11ee30; Ecp_IpLoginFail=200701183.202.194.16; ASP.NET_SessionId=edraumuckd12e2nqz3tywjsk; SID_kns=123113; SID_klogin=125141; SID_kinfo=125104; KNS_SortType=; SID_krsnew=125133; _pk_ref=%5B%22%22%2C%22%22%2C1593599729%2C%22https%3A%2F%2Fwww.cnki.net%2F%22%5D; _pk_ses=*; SID_kns_new=kns123113; RsPerPage=50; SID_kcms=124120; DisplaySave=0‘,
‘Host‘: ‘kns.cnki.net‘,
‘Upgrade-Insecure-Requests‘: ‘1‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘
}
page = 70
while page < 104:
try:
url = f"https://kns.cnki.net/kns/brief/brief.aspx?curpage={page}&RecordsPerPage=50&QueryID=2&ID=&turnpage=1&tpagemode=L&dbPrefix=CJFQ&Fields=&DisplayMode=listmode&PageName=ASP.brief_result_aspx&isinEn=2&"
response = requests.get(url, headers=headers)
with open(f‘{self.search_html_dir}/{page}.html‘, mode=‘w‘, encoding=‘utf-8‘) as f:
f.write(response.text)
print(f‘{page} 下载完成‘)
if self.get_file_size(f"{self.search_html_dir}/{page}.html") < 50:
raise Exception("cookie失效")
page += 1
except Exception as e:
print(f‘{page}下载失败\t正在睡眠 请耐心等待‘, )
time.sleep(30)
def parse_search_article_info(self):
for file in os.listdir(self.search_html_dir):
file_path = os.path.join(self.search_html_dir, file)
items = []
try:
text = self.read_html(file_path)
response = HTML(text)
tr_list = response.xpath(‘//table[@class="GridTableContent"]/tr[@bgcolor]‘)
for tr in tr_list:
item = {}
item[‘title‘] = tr.xpath(‘td[2]/a/text()‘)[0]
href = tr.xpath(‘td[2]/a/@href‘)[0]
params = parse_qs(urlparse(href).query)
dbcode = params[‘DbCode‘][0]
dbname = params[‘dbname‘][0]
filename = params[‘filename‘][0]
item[‘filename‘] = filename
item[
‘article_url‘] = f‘https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode={dbcode}&dbname={dbname}&filename={filename}‘
item[‘authors‘] = ‘; ‘.join(tr.xpath(‘td[@class="author_flag"]/a/text()‘))
item[‘journal‘] = tr.xpath(‘td[@class="cjfdyxyz"]/a/text()‘)[0].strip()
item[‘publish_time‘] = tr.xpath(‘td[5]/text()‘)[0].strip().split()[0]
try:
item[‘cited_num‘] = tr.xpath(‘td[6]/span[@class="KnowledgeNetcont"]/a/text()‘)[0]
except IndexError:
item[‘cited_num‘] = 0
try:
item[‘download_num‘] = tr.xpath(‘td[7]/span[@class="downloadCount"]/a/text()‘)[0]
except IndexError:
item[‘download_num‘] = 0
items.append(item)
df = DataFrame(data=items)
df.set_index(keys=‘filename‘, inplace=True)
df.to_sql("paper_info", con=self.conn, if_exists=‘append‘)
print(f‘{file_path}\t解析完成‘)
except Exception as e:
print(f‘{file_path}\t插入失败‘)
traceback.print_exc()
def spider_article_detail_page(self):
if len(os.listdir(self.paper_html_dir)) > 0:
files = {file.replace(‘.html‘, ‘‘) for file in os.listdir(self.paper_html_dir)}
files = "(‘" + "‘,‘".join(files) + "‘)"
paper_info = read_sql(f"SELECT article_url FROM paper_info where filename not in {files}", con=self.conn)
else:
paper_info = read_sql(f"SELECT article_url FROM paper_info", con=self.conn)
with ThreadPoolExecutor() as pool:
pool.map(self.download_article_detail, paper_info[‘article_url‘])
# paper_info[‘article_url‘].apply(self.download_article_detail)
def download_article_detail(self, url):
filename = parse_qs(urlparse(url).query)[‘filename‘][0]
filepath = f‘{self.paper_html_dir}/{filename}.html‘
response = requests.get(url)
self.write_html(response.text, filepath)
if self.get_file_size(file_path=filepath) < 5:
print(f‘{url}\t下载失败‘)
exit()
print(f‘{url}\t下载完成‘)
def parse_article_detail(self):
f = open(‘error.txt‘, mode=‘a‘)
for file in os.listdir(self.paper_html_dir):
filename = file.replace(‘.html‘, ‘‘)
file_path = os.path.join(self.paper_html_dir, file)
try:
text = self.read_html(file_path)
response = HTML(text)
institution = ‘; ‘.join(response.xpath(‘//div[@class="orgn"]/span/a/text()‘))
try:
summary = response.xpath(‘//span[@id="ChDivSummary"]/text()‘)[0]
except IndexError:
summary = ‘‘
keywords = ‘ ‘.join([word.strip() for word in response.xpath(
‘//label[@id="catalog_KEYWORD"]/following-sibling::a/text()‘)]).strip(‘;‘)
try:
cls_num = response.xpath(‘//label[@id="catalog_ZTCLS"]/parent::p/text()‘)[0]
except IndexError:
cls_num = ‘‘
self.db.execute(
"update paper_info set summary=?, institution=?, keywords=?, cls_num=? where filename=?",
params=(summary, institution, keywords, cls_num, filename))
print(f‘{filename} 更新完毕‘)
except Exception as e:
print(f‘{filename} 更新失败‘, e)
f.write(f‘{file_path}\n‘)
f.close()
def download_article_refer_cited_page(self):
paper_info = read_sql(f"SELECT article_url FROM paper_info", con=self.conn)
self.error_f = open(‘error.txt‘, mode=‘w‘)
with ThreadPoolExecutor() as pool:
pool.map(self.download_reference_page, paper_info[‘article_url‘])
pool.map(self.download_cited_page, paper_info[‘article_url‘])
self.error_f.close()
def download_reference_page(self, url):
"""
下载指定文章参考文献页面
:param url:
:return:
"""
query = urlparse(url).query
filename = parse_qs(query)[‘filename‘][0]
refer_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=1&vl="
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘,
‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘,
}
response = requests.get(refer_url, headers=headers)
if response.status_code == 200:
self.write_html(response.text, f‘{self.paper_refer_html_dir}/{filename}.html‘)
else:
raise Exception(f"请求异常, 状态码为:{response.status_code}")
except Exception as e:
self.error_f.write(refer_url + ‘\n‘)
print(f‘{refer_url}\t下载失败‘, e)
def download_cited_page(self, url):
query = urlparse(url).query
filename = parse_qs(query)[‘filename‘][0]
cited_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=3&vl="
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘,
‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘,
}
response = requests.get(cited_url, headers=headers)
if response.status_code == 200:
self.write_html(response.text, f‘{self.paper_cited_html_dir}/{filename}.html‘)
else:
raise Exception(f"请求异常, 状态码为:{response.status_code}")
except Exception as e:
self.error_f.write(cited_url + ‘\n‘)
print(f‘{cited_url}\t下载失败‘, e)
def get_error_refer_cited_page(self):
with open(‘error.txt‘) as f:
for line in f:
url = line.strip()
if url.endswith("RefType=3&vl="):
self.download_cited_page(url.replace("RefType=3&vl=", ""))
elif url.endswith("RefType=1&vl="):
self.download_reference_page(url.replace("RefType=1&vl=", ""))
def get_all_refer_cited_page_url(self):
f = open(‘more_refer_cited_url.txt‘, mode=‘a‘)
for file_path in self.get_dir_all_files(self.paper_refer_html_dir, self.paper_cited_html_dir):
filename = file_path.split(‘\\‘)[-1].replace(‘.html‘, ‘‘)
req_type = 1 if file_path.__contains__(‘refer‘) else 3
response = HTML(self.read_html(file_path))
nodes = response.xpath(‘//span[@name="pcount"]‘)
for node in nodes:
pcount = int(node.xpath(‘text()‘)[0])
if pcount > 10:
article_url = self.db.fetchone(f"select article_url from paper_info where filename=?", params=(filename,))[0]
query = urlparse(article_url).query
pages = int(pcount / 10) + 1
CurDBCode = node.xpath(‘@id‘)[0].replace(‘pc_‘, ‘‘)
for page in range(2, pages + 1):
url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType={req_type}&vl=&CurDBCode={CurDBCode}&page={page}"
f.write(f‘{url}\n‘)
print(f‘{url}\t写入成功‘)
f.close()
def download_all_refer_cited_page(self):
self.error_f = open(‘error.txt‘, mode=‘w‘)
def download_page(url):
query = parse_qs(urlparse(url).query)
page = query[‘page‘][0]
CurDbCode = query[‘CurDBCode‘][0]
filename = query[‘filename‘][0]
refType = query[‘RefType‘][0]
if refType == ‘1‘:
file_path = f‘{self.paper_refer_html_dir}/{filename}_{CurDbCode}_{page}.html‘
else:
file_path = f‘{self.paper_cited_html_dir}/{filename}_{CurDbCode}_{page}.html‘
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘,
‘Referer‘: url,
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
self.write_html(response.text, file_path)
else:
raise Exception(f"请求异常, 状态码为:{response.status_code}")
except Exception as e:
self.error_f.write(url + ‘\n‘)
print(f‘{url}\t下载失败‘, e)
with open(‘more_refer_cited_url.txt‘) as f:
urls = [line.strip() for line in f]
with ThreadPoolExecutor() as pool:
pool.map(download_page, urls)
self.error_f.close()
def download_all_error_refer_cited_page(self):
with open(‘error.txt‘) as f:
for line in f:
url = line.strip()
query = parse_qs(urlparse(url).query)
page = query[‘page‘][0]
CurDbCode = query[‘CurDBCode‘][0]
filename = query[‘filename‘][0]
refType = query[‘RefType‘][0]
if refType == ‘1‘:
file_path = f‘{self.paper_refer_html_dir}/{filename}_{CurDbCode}_{page}.html‘
else:
file_path = f‘{self.paper_cited_html_dir}/{filename}_{CurDbCode}_{page}.html‘
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘,
‘Referer‘: url,
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
self.write_html(response.text, file_path)
print(f‘{url}\t下载成功‘)
else:
raise Exception(f"请求异常, 状态码为:{response.status_code}")
except Exception as e:
print(f‘{url}\t下载失败‘, e)
def get_article_refer_num(self):
def parse_refer_num(filename):
try:
response1 = HTML(self.read_html(f‘{self.paper_refer_html_dir}/{filename}.html‘))
refer_pcounts = response1.xpath(‘//span[@name="pcount"]/text()‘)
if refer_pcounts:
refer_num = sum(int(num) for num in refer_pcounts)
else:
refer_num = 0
self.db.execute("update paper_info set refer_num=? where filename=?", params=(refer_num, filename))
print(f‘{filename}\t{refer_num}‘)
except Exception as e:
print(f‘{filename}\t解析失败‘, e)
paper_info = read_sql(f"SELECT filename FROM paper_info", con=self.conn)
paper_info[‘filename‘].apply(parse_refer_num)
@timeit
def parse_refer_cited_info(self):
self.error_f = open(‘error.txt‘, mode=‘a‘)
refer_file_list = []
cited_file_list = []
for file in self.get_dir_all_files(self.paper_refer_html_dir, self.paper_cited_html_dir):
if file.__contains__(‘refer‘):
refer_file_list.append(file)
elif file.__contains__(‘cited‘):
cited_file_list.append(file)
refer_data_list = []
for file in refer_file_list:
self.parse_reference_cited_article_detail(file, relation=‘参考文献‘, data_list=refer_data_list)
refer_data = DataFrame(data=refer_data_list)
refer_data.drop_duplicates(subset=[‘origin_article‘, ‘dbcode‘, ‘pid‘, ‘relation‘], inplace=True)
refer_data.to_csv(‘res/参考文献.csv‘, index=False, encoding=‘utf_8_sig‘)
# refer_data.to_sql("reference_article", con=self.conn, if_exists=‘append‘, index=False)
cited_data_list = []
for file in cited_file_list:
self.parse_reference_cited_article_detail(file, relation=‘引证文献‘, data_list=cited_data_list)
cited_data = DataFrame(data=cited_data_list)
print(cited_data.info())
cited_data.drop_duplicates(subset=[‘origin_article‘, ‘dbcode‘, ‘pid‘, ‘relation‘], inplace=True)
print(cited_data.info())
cited_data.to_csv(‘res/引证文献.csv‘, index=False, encoding=‘utf_8_sig‘)
# cited_data.to_sql("cited_article", con=self.conn, if_exists=‘append‘, index=False)
self.error_f.close()
def parse_reference_cited_article_detail(self, file, relation, data_list):
filename = file.split(‘\\‘)[-1].replace(‘.html‘, ‘‘)
if len(filename.split(‘_‘)) > 1:
filename = filename.split(‘_‘, maxsplit=1)[0]
response = HTML(self.read_html(file))
essayBoxs = response.xpath(‘//div[@class="essayBox"]‘)
for box in essayBoxs:
db_title = box.xpath(‘div[@class="dbTitle"]/text()‘)[0]
db_code = box.xpath(‘div[@class="dbTitle"]/b/span[@name="pcount"]/@id‘)[0].replace(‘pc_‘, ‘‘)
essays = box.xpath(‘ul[contains(@class, "ebBd")]/li‘)
for essay in essays:
item = ArticleItem()
item.relation = relation
item.origin_article = filename
item.dbcode = db_code
item.dbtitle = db_title
try:
item.pid = essay.xpath(‘em[1]/text()‘)[0].strip().replace(‘[‘, ‘‘).replace(‘]‘, ‘‘)
except IndexError:
continue
if db_code == ‘CBBD‘:
info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘)
try:
res = re.search(‘(.*?)\[(.*?)\]\.(.*?),(.*?),(\d{4})‘, info)
item.title = res.group(1)
item.article_type = res.group(2)
item.journal = res.group(3)
item.author = res.group(4)
item.year = res.group(5)
except AttributeError as e:
res = re.search(‘(.*?)\[(.*?)\]\.(.*?),(.*?),‘, info)
item.title = res.group(1)
item.article_type = res.group(2)
item.journal = res.group(3)
item.author = res.group(4)
elif db_code == ‘CJFQ‘:
try:
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ‘‘
text_info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(
‘  ‘, ‘‘).replace(‘.‘, ‘‘).replace(‘,‘, ‘;‘)
res = re.search(‘\[(.*?)\] (.*)‘, text_info)
article_type, author = res.group(1), res.group(2)
item.article_type = article_type.replace(‘[‘, ‘‘).replace(‘]‘, ‘‘)
item.author = author.replace(‘;‘, ‘; ‘)
item.journal = essay.xpath(‘a[2]/text()‘)[0]
item.year = essay.xpath(‘a[3]/text()‘)[0][:4]
except IndexError:
text_info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(
‘  ‘, ‘‘)
try:
res = re.search(‘(.*?)\[(.*?)\]\. (.*)\.(.*?)\.(\d{4})‘, text_info)
item.title = res.group(1)
item.article_type = res.group(2)
item.author = res.group(3).replace(‘,‘, ‘; ‘)
item.journal = res.group(4)
item.year = res.group(5)
except AttributeError:
try:
res = re.search(‘(.*?)\[(.*?)\]\. (.*?)\.(\d{4})‘, text_info)
item.title = res.group(1)
item.article_type = res.group(2)
item.journal = res.group(3)
item.year = res.group(4)
except AttributeError:
continue
elif db_code == ‘CDFD‘ or db_code == ‘CMFD‘:
try:
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ‘‘
info = ‘‘.join(essay.xpath(‘text()‘)).replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘)
# try:
res = re.search(‘\[(.*?)\]\.(.*?)\.(\d{4})‘, info)
item.article_type = res.group(1)
item.author = res.group(2)
item.year = res.group(3)
item.institution = essay.xpath(‘a[2]/text()‘)[0]
except IndexError:
continue
elif db_code == ‘CPFD‘:
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ‘‘
info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘)
res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?)\.(\d{4})‘, info)
item.article_type = res.group(1)
item.journal = res.group(3)
item.author = res.group(2)
item.year = res.group(4)
elif db_code == ‘SSJD‘:
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ‘‘
info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(‘  ‘, ‘‘)
try:
res = re.search(‘\[(.*?)\] \. (.*)\.(.*?) \.(\d{4})‘, info)
item.article_type = res.group(1)
item.journal = res.group(3)
item.author = res.group(2).replace(‘,‘, ‘; ‘)
item.year = res.group(4)
except AttributeError:
res = re.search(‘\[(.*?)\] \. (.*?) \.(\d{4})‘, info)
item.article_type = res.group(1)
item.journal = res.group(2)
item.year = res.group(3)
elif db_code == ‘CRLDENG‘:
try:
item.title = essay.xpath(‘a[1]/text()‘)[0]
info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(‘  ‘, ‘‘)
try:
res = re.search(‘\. (.*?)\. (.*?)\. (\d{4})‘, info)
item.author = res.group(1).replace(‘,‘, ‘; ‘)
item.journal = res.group(2)
item.year = res.group(3)
except AttributeError:
try:
res = re.search(‘\. (.*)\. (.*?) (\d{4})‘, info)
item.author = res.group(1).replace(‘,‘, ‘; ‘)
item.journal = res.group(2)
item.year = res.group(3)
except AttributeError:
try:
res = re.search(‘\. (.*)\. (.*?)\.‘, info)
item.author = res.group(1).replace(‘,‘, ‘; ‘)
item.journal = res.group(2)
except AttributeError:
try:
res = re.search(‘ (.*)\. (.*?)\. (\d{4})‘, info)
item.author = res.group(1)
item.title = res.group(2)
item.year = res.group(3)
except AttributeError:
try:
res = re.search(‘\.(.*?)\. (\d{4})‘, info)
item.url = res.group(1)
item.year = res.group(2)
except AttributeError:
try:
item.year = re.search(‘(\d{4})‘, info).group(1)
except AttributeError:
item.url = info.strip(‘.‘)
except IndexError:
info = essay.xpath(‘text()‘)[0].replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(‘  ‘, ‘‘)
try:
res = re.search(‘(.*)\. (.*?)\. (\d{4})‘, info)
item.author = res.group(1).replace(‘,‘, ‘; ‘)
item.title = res.group(2)
item.year = res.group(3)
except AttributeError:
try:
res = re.search(‘(.*)\. (\d{4})‘, info)
item.title = res.group(1)
item.year = res.group(2)
except AttributeError:
item.url = info.strip(‘.‘)
elif db_code == ‘CCND‘:
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ""
info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(
‘  ‘, ‘‘)
try:
res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?)\.(\d{4})‘, info)
item.article_type = res.group(1)
item.author = res.group(2).replace(‘,‘, ‘; ‘)
item.journal = res.group(3)
item.year = res.group(4)
except AttributeError:
res = re.search(‘\[(.*?)\]\.(.*?)\.(\d{4})‘, info)
item.article_type = res.group(1)
item.journal = res.group(2)
item.year = res.group(3)
elif db_code == ‘CYFD‘: # XNZS201112009
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ""
info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(
‘  ‘, ‘‘)
res = re.search(‘\[(.*?)\]\. (.*?)\.‘, info)
item.article_type = res.group(1)
item.journal = res.group(2)
elif db_code == ‘IPFD‘:
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ""
info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(
‘  ‘, ‘‘)
try:
res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?)\.(\d{4})‘, info)
item.article_type = res.group(1)
item.author = res.group(2).replace(‘,‘, ‘; ‘)
item.journal = res.group(3)
item.year = res.group(4)
except AttributeError:
res = re.search(‘\[(.*?)\]\.(.*?)\.(\d{4})‘, info)
item.article_type = res.group(1)
item.journal = res.group(2)
item.year = res.group(3)
elif db_code == ‘SCPD‘: # TIRE20130201
item.title = essay.xpath(‘a[1]/text()‘)[0]
article_url = essay.xpath(‘a[1]/@href‘)
if article_url:
item.article_url = ‘https://kns.cnki.net/‘ + article_url[0]
else:
item.article_url = ""
info = ‘‘.join(essay.xpath(‘text()‘)).strip().replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘).replace(
‘  ‘, ‘‘)
res = re.search(‘\[(.*?)\]\.(.*?)\.(.*?):(.*?),‘, info)
item.article_type = res.group(1)
item.author = res.group(2).replace(‘,‘, ‘; ‘)
item.journal = res.group(3)
item.patent_num = res.group(4)
else:
self.error_f.write(f‘{db_code}\t{filename}\t类型异常\n‘)
print(f‘{db_code}\t{filename}\t类型异常\n‘)
data_list.append(item.__dict__)
def spider_refer_cited_detail_page(self):
self.error_f = open(‘error.txt‘, mode=‘w‘)
if os.path.exists("refer_url.xlsx"):
refer_data = read_excel(‘refer_url.xlsx‘)
refer_data[‘dir_path‘] = self.refer_paper_dir
if len(os.listdir(self.refer_paper_dir)) > 0:
refer_ids = {int(file.replace(‘.html‘, ‘‘)) for file in os.listdir(self.refer_paper_dir)}
refer_data = refer_data[~refer_data[‘index‘].isin(refer_ids)]
else:
refer_data = read_sql("select distinct article_url from reference_article where article_url != ‘‘;", con=self.conn)
refer_data.reset_index(inplace=True)
refer_data.to_excel(‘refer_url.xlsx‘, index=False)
refer_data[‘dir_path‘] = self.refer_paper_dir
if os.path.exists(‘cited_url.xlsx‘):
cited_data = read_excel(‘cited_url.xlsx‘)
cited_data[‘dir_path‘] = self.cited_paper_dir
if len(os.listdir(self.cited_paper_dir)) > 0:
cited_ids = {int(file.replace(‘.html‘, ‘‘)) for file in os.listdir(self.cited_paper_dir)}
cited_data = cited_data[~cited_data[‘index‘].isin(cited_ids)]
else:
cited_data = read_sql("select distinct article_url from cited_article where article_url != ‘‘;", con=self.conn)
cited_data.reset_index(inplace=True)
cited_data.to_excel(‘cited_url.xlsx‘, index=False)
cited_data[‘dir_path‘] = self.cited_paper_dir
def download_paper_page(row):
index, url, dir_path= row[0], row[1], row[2]
file_path = f‘{dir_path}/{index}.html‘
response = requests.get(url)
self.write_html(response.text, file_path)
if self.get_file_size(file_path=file_path) < 5:
print(f‘{file_path}\t下载失败‘)
self.error_f.write(f‘{index},{url},{dir_path}\n‘)
else:
print(f‘{file_path}\t下载完成‘)
with ThreadPoolExecutor() as pool:
pool.map(download_paper_page, refer_data.values)
with ThreadPoolExecutor() as pool:
pool.map(download_paper_page, cited_data.values)
self.error_f.close()
def parse_refer_cited_detail_info(self):
self.error_f = open(‘error.txt‘, mode=‘w‘)
refer_data = read_excel(‘refer_url.xlsx‘)
refer_data[‘dir_path‘] = self.refer_paper_dir
cited_data = read_excel(‘cited_url.xlsx‘)
cited_data[‘dir_path‘] = self.cited_paper_dir
def parse_paper_page(row):
index, url, dir_path = row[0], row[1], row[2]
file_path = f‘{dir_path}/{index}.html‘
try:
text = self.read_html(file_path)
response = HTML(text)
try:
title = response.xpath(‘//div[@class="wxTitle"]/h2[@class="title"]/text()‘)[0]
institution = ‘; ‘.join(response.xpath(‘//div[@class="orgn"]/span/a/text()‘))
except IndexError:
return
try:
summary = response.xpath(‘//span[@id="ChDivSummary"]/text()‘)[0]
except IndexError:
summary = ‘‘
keywords = ‘ ‘.join([word.strip() for word in response.xpath(
‘//label[@id="catalog_KEYWORD"]/following-sibling::a/text()‘)]).strip(‘;‘)
try:
cls_num = response.xpath(‘//label[@id="catalog_ZTCLS"]/parent::p/text()‘)[0]
except IndexError:
cls_num = ‘‘
if "refer" in dir_path:
self.db.execute("update reference_article set title=?, summary=?, institution=?, keywords=?, cls_num=? where article_url=?", params=(title, summary, institution, keywords, cls_num, url))
elif "cited" in dir_path:
self.db.execute("update cited_article set title=?, summary=?, institution=?, keywords=?, cls_num=? where article_url=?", params=(title, summary, institution, keywords, cls_num, url))
print(f‘{file_path} 更新完毕‘)
except Exception as e:
print(f‘{url} 更新失败‘, e)
traceback.print_exc()
self.error_f.write(f‘{index},{url},{file_path}\n‘)
refer_data.apply(parse_paper_page, axis=1)
cited_data.apply(parse_paper_page, axis=1)
def get_refer_cited_paper_page(self):
def download_refer_num(row):
index, url, dir_path = row[0], row[1], row[2]
query = urlparse(url).query
if "refer" in dir_path:
file_path = f‘{self.refer_refer}/{index}.html‘
elif "cited" in dir_path:
file_path = f‘{self.cited_refer}/{index}.html‘
refer_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=1&vl="
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘,
‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘,
}
response = requests.get(refer_url, headers=headers)
if response.status_code == 200:
self.write_html(response.text, file_path)
print(f‘{file_path}\t下载完成‘)
else:
raise Exception(f"请求异常, 状态码为:{response.status_code}")
except Exception as e:
self.error_f.write(f‘{index},{url},{dir_path}\n‘)
print(f‘{url}\t下载失败‘, e)
# traceback.print_exc()
def download_cited_num(row):
index, url, dir_path = row[0], row[1], row[2]
query = urlparse(url).query
cited_url = f"https://kns.cnki.net/kcms/detail/frame/list.aspx?{query}&RefType=3&vl="
if "refer" in dir_path:
file_path = f‘{self.refer_cited}/{index}.html‘
elif "cited" in dir_path:
file_path = f‘{self.cited_cited}/{index}.html‘
try:
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘,
‘Referer‘: f‘https://kns.cnki.net/KCMS/detail/detail.aspx?{query}‘,
}
response = requests.get(cited_url, headers=headers)
if response.status_code == 200:
self.write_html(response.text, file_path)
print(f‘{file_path}\t下载完成‘)
else:
raise Exception(f"请求异常, 状态码为:{response.status_code}")
except Exception as e:
self.error_f.write(f‘{index},{url},{dir_path}\n‘)
print(f‘{url}\t下载失败‘, e)
# traceback.print_exc()
refer_list = []
cited_list = []
with open(‘error.txt‘) as f:
for line in f:
row = line.strip().split(‘,‘)
if ‘html/refer_paper‘ in line:
refer_list.append(row)
if ‘html/cited_paper‘ in line:
cited_list.append(row)
if len(refer_list) > 0 or len(cited_list) > 0:
self.error_f = open(‘error1.txt‘, mode=‘w‘)
with ThreadPoolExecutor() as pool:
pool.map(download_refer_num, refer_list)
pool.map(download_cited_num, refer_list)
pool.map(download_refer_num, cited_list)
pool.map(download_cited_num, cited_list)
else:
refer_data = read_excel(‘refer_url.xlsx‘)
refer_data[‘dir_path‘] = self.refer_paper_dir
cited_data = read_excel(‘cited_url.xlsx‘)
cited_data[‘dir_path‘] = self.cited_paper_dir
with ThreadPoolExecutor() as pool:
pool.map(download_refer_num, refer_data.values)
pool.map(download_cited_num, refer_data.values)
pool.map(download_refer_num, cited_data.values)
pool.map(download_cited_num, cited_data.values)
self.error_f.close()
def parse_refer_cited_page_refer_cited_num(self):
self.error_f = open(‘error4.txt‘, mode=‘w‘)
def parse_num(file_path):
if os.path.exists(file_path):
text = self.read_html(file_path)
html = HTML(text)
pcounts = html.xpath(‘//span[@name="pcount"]/text()‘)
if pcounts:
cited_num = sum(int(num) for num in pcounts)
else:
cited_num = 0
return cited_num
return ‘fne‘
def parse_refer_cited_num(row):
index, url, dir_path = row[0], row[1], row[2]
if "refer" in dir_path:
refer_file_path = f‘{self.refer_refer}/{index}.html‘
cited_file_path = f‘{self.refer_cited}/{index}.html‘
elif "cited" in dir_path:
refer_file_path = f‘{self.cited_refer}/{index}.html‘
cited_file_path = f‘{self.cited_cited}/{index}.html‘
refer_num = parse_num(refer_file_path)
cited_num = parse_num(cited_file_path)
try:
if refer_num != ‘fne‘ and cited_num != ‘fne‘:
if "refer" in dir_path:
self.db.execute("update reference_article set refer_num=?, cited_num=? where article_url=?",
params=(refer_num, cited_num, url))
elif "cited" in dir_path:
self.db.execute("update cited_article set refer_num=?, cited_num=? where article_url=?",
params=(refer_num, cited_num, url))
print(f‘{dir_path}\t{index}\t{refer_num}\t{cited_num}\t插入成功‘)
else:
self.error_f.write(f‘{index},{url},{dir_path}\n‘)
print(refer_file_path + ‘文件不存在‘)
except Exception as e:
self.error_f.write(f‘{index},{url},{dir_path}\n‘)
traceback.print_exc()
refer_data = read_excel(‘refer_url.xlsx‘)
refer_data[‘dir_path‘] = self.refer_paper_dir
cited_data = read_excel(‘cited_url.xlsx‘)
cited_data[‘dir_path‘] = self.cited_paper_dir
refer_data.apply(parse_refer_cited_num, axis=1)
cited_data.apply(parse_refer_cited_num, axis=1)
self.error_f.close()
def export_to_file(self):
refer_data = read_sql("reference_article", con=self.conn)
refer_data.drop(columns=[‘index‘], inplace=True)
with ExcelWriter(‘res/参考文献.xlsx‘, engine=‘xlsxwriter‘, options={‘strings_to_urls‘: False}) as writer:
refer_data.to_excel(writer, sheet_name=‘Sheet1‘, index=False)
writer.save()
cited_data = read_sql("cited_article", con=self.conn)
cited_data.drop(columns=[‘index‘], inplace=True)
with ExcelWriter(‘res/引证文献.xlsx‘, engine=‘xlsxwriter‘, options={‘strings_to_urls‘: False}) as writer:
cited_data.to_excel(writer, sheet_name=‘Sheet1‘, index=False)
writer.save()
if __name__ == ‘__main__‘:
cnki = CnkiSpider()
cnki.download_search_page()
# cnki.parse_search_article_info()
# cnki.spider_article_detail_page()
# cnki.parse_article_detail()
# cnki.download_article_refer_cited_page()
# cnki.get_error_refer_cited_page()
# cnki.get_all_refer_cited_page_url()
# cnki.download_all_refer_cited_page()
# cnki.download_all_error_refer_cited_page()
# cnki.get_article_refer_num()
# cnki.parse_refer_cited_info()
# cnki.spider_refer_cited_detail_page()
# cnki.parse_refer_cited_detail_info()
# cnki.get_refer_cited_paper_page()
# cnki.parse_refer_cited_page_refer_cited_num()
# cnki.export_to_file()
关注我,定期分享自己的实战经验和积累的代码。
原文:https://www.cnblogs.com/zhangyafei/p/13236226.html
