Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
Kubernetes一个核心的特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着(比如用户想让apache一直运行,用户不需要关心怎么去做,Kubernetes会自动去监控,然后去重启,新建,总之,让apache一直提供服务),管理员可以加载一个微型服务,让规划器来找到合适的位置,同时,Kubernetes也系统提升工具以及人性化方面,让用户能够方便的部署自己的应用(就像canary deployments)。
Kubernetes节点有运行应用容器必备的服务,而这些都是受Master的控制。
每次个节点上当然都要运行Docker。Docker来负责所有具体的映像下载和容器运行。
Kubernetes主要由以下几个核心组件组成:
除了核心组件,还有一些推荐的Add-ons:
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是Pod,Pod是最小的,管理,创建,计划的最小单元.一个Pod(就像一群鲸鱼,或者一个豌豆夹)相当于一个共享context的配置组,在同一个context下,应用可能还会有独立的cgroup隔离机制,一个Pod是一个容器环境下的“逻辑主机”,它可能包含一个或者多个紧密相连的应用,这些应用可能是在同一个物理主机或虚拟机上。
- 同一个Pod中的应用可以共享磁盘
- 由于docker的架构,一个Pod是由多个相关的并且共享磁盘的容器组成
标签其实就一对 key/value ,被关联到对象上,比如Pod,标签的使用我们倾向于能够标示对象的特殊特点,并且对用户而言是有意义的(就是一眼就看出了这个Pod是尼玛数据库),但是标签对内核系统是没有直接意义的。标签可以用来划分特定组的对象(比如,所有女的),标签可以在创建一个对象的时候直接给与,也可以在后期随时修改,每一个对象可以拥有多个标签,但是,key值必须是唯一的
Namespace是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。常见的pods, services, replication controllers和deployments等都是属于某一个namespace的(默认是default),而node, persistentVolumes等则不属于任何namespace
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个,和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
Node是Pod真正运行的主机,可以物理机,也可以是虚拟机。为了管理Pod,每个Node节点上至少要运行container runtime(比如docker或者rkt)、kubelet和kube-proxy服务。
每个Node都包括以下状态信息
ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持新的,基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa))。在试用时官方推荐ReplicaSet。
Kubernetes Pod是平凡的,它门会被创建,也会死掉(生老病死),并且他们是不可复活的。 ReplicationControllers动态的创建和销毁Pods(比如规模扩大或者缩小,或者执行动态更新)。每个pod都由自己的ip,这些IP也随着时间的变化也不能持续依赖。这样就引发了一个问题:如果一些Pods(让我们叫它作后台,后端)提供了一些功能供其它的Pod使用(让我们叫作前台),在kubernete集群中是如何实现让这些前台能够持续的追踪到这些后台的?答案是:Service
Kubernete Service 是一个定义了一组Pod的策略的抽象,我们也有时候叫做宏观服务。这些被服务标记的Pod都是(一般)通过label Selector决定的(下面我们会讲到我们为什么需要一个没有label selector的服务)
容器中的磁盘的生命周期是短暂的,这就带来了一系列的问题,第一,当一个容器损坏之后,kubelet 会重启这个容器,但是文件会丢失-这个容器会是一个全新的状态,第二,当很多容器在同一Pod中运行的时候,很多时候需要数据文件的共享。Kubernete Volume解决了这个问题.
一个Kubernetes volume,拥有明确的生命周期,与所在的Pod的生命周期相同。因此,Kubernetes volume独立与任何容器,与Pod相关,所以数据在重启的过程中还会保留,当然,如果这个Pod被删除了,那么这些数据也会被删除。更重要的是,Kubernetes volume 支持多种类型,任何容器都可以使用多个Kubernetes volume。
Deployment为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController来方便的管理应用。典型的应用场景包括:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Secret解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。Secret可以以Volume或者环境变量的方式使用。
Secret有三种类型:
在本篇文章中你将会看到一些在其他地方被交叉使用的术语,为了防止产生歧义,我们首先来澄清下。
什么是Ingress?
通常情况下,service和pod的IP仅可在集群内部访问。集群外部的请求需要通过负载均衡转发到service在Node上暴露的NodePort上,然后再由kube-proxy将其转发给相关的Pod。
Ingress可以给service提供集群外部访问的URL、负载均衡、SSL终止、HTTP路由等。为了配置这些Ingress规则,集群管理员需要部署一个Ingress controller,它监听Ingress和service的变化,并根据规则配置负载均衡并提供访问入口。
ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。ConfigMap跟secret很类似,但它可以更方便地处理不包含敏感信息的字符串。
Kubernetes 通过各种 Controller 来管理 Pod 的生命周期。为了满足不同业务场景,Kubernetes 开发了 Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等多种 Controller。最常用的 Deployment用来建立Pod,以下是它的步骤
replicas的命名方式 :deployment名称+随机数
pod的命名方式:replicas名称+随机数
targetPort很好理解,targetPort是pod上的端口,从port和nodePort上到来的数据最终经过kube-proxy流入到后端pod的targetPort上进入容器。
这里的port表示:service暴露在cluster ip上的端口,:port 是提供给集群内部客户访问service的入口,而在集群内部,各个服务之间我们也可以通过服务名+Port来访问指定的服务,k8s内部会把服务解析到对应的pod上面。
nodePort是kubernetes提供给集群外部客户访问service入口的一种方式(另一种方式是LoadBalancer),所以,:nodePort 是提供给集群外部客户访问service的入口。
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
这些语法适合于rancher平台,因为rancher平台的底层也是k8s为基础的。
k8s用命名空间namespace把资源进行隔离,默认情况下,相同的命名空间里的服务可以相互通讯,反之进行隔离。
Kubernetes中一个应用服务会有一个或多个实例(Pod,Pod可以通过rs进行多复本的建立),每个实例(Pod)的IP地址由网络插件动态随机分配(Pod重启后IP地址会改变)。为屏蔽这些后端实例的动态变化和对多实例的负载均衡,引入了Service这个资源对象,如下所示:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 80
selector: #service通过selector和pod建立关联
app: nginx
根据创建Service的type类型不同,可分成4种模式:
ClusterIP: 默认方式。根据是否生成ClusterIP又可分为普通Service和Headless Service两类:
固定虚拟IP(Cluster IP),实现集群内的访问。为最常见的方式。NodePort:除了使用Cluster IP之外,还通过将service的port映射到集群内每个节点的相同一个端口,实现通过nodeIP:nodePort从集群外访问服务。LoadBalancer:和nodePort类似,不过除了使用一个Cluster IP和nodePort之外,还会向所使用的公有云申请一个负载均衡器(负载均衡器后端映射到各节点的nodePort),实现从集群外通过LB访问服务。ExternalName:是 Service 的特例。此模式主要面向运行在集群外部的服务,通过它可以将外部服务映射进k8s集群,且具备k8s内服务的一些特征(如具备namespace等属性),来为集群内部提供服务。此模式要求kube-dns的版本为1.7或以上。这种模式和前三种模式(除headless service)最大的不同是重定向依赖的是dns层次,而不是通过kube-proxy。此时k8s集群内的DNS服务会给集群内的服务名 ..svc.cluster.local 创建一个CNAME记录,其值为指定的"my.database.example.com"。
当查询k8s集群内的服务my-service.prod.svc.cluster.local时,集群的 DNS 服务将返回映射的CNAME记录"foo.bar.example.com"。
备注:
前3种模式,定义服务的时候通过selector指定服务对应的pods,根据pods的地址创建出endpoints作为服务后端;Endpoints Controller会watch Service以及pod的变化,维护对应的Endpoint信息。kube-proxy根据Service和Endpoint来维护本地的路由规则。当Endpoint发生变化,即Service以及关联的pod发生变化,kube-proxy都会在每个节点上更新iptables,实现一层负载均衡。
而ExternalName模式则不指定selector,相应的也就没有port和endpoints。
ExternalName和ClusterIP中的Headles Service同属于Headless Service的两种情况。Headless Service主要是指不分配Service IP,且不通过kube-proxy做反向代理和负载均衡的服务。
Service中主要涉及三种Port: * port 这里的port表示service暴露在clusterIP上的端口,clusterIP:Port 是提供给集群内部访问kubernetes服务的入口。
targetPort
containerPort,targetPort是pod上的端口,从port和nodePort上到来的数据最终经过kube-proxy流入到后端pod的targetPort上进入容器。
nodePort
nodeIP:nodePort 是提供给从集群外部访问kubernetes服务的入口。
总的来说,port和nodePort都是service的端口,前者暴露给从集群内访问服务,后者暴露给从集群外访问服务。从这两个端口到来的数据都需要经过反向代理kube-proxy流入后端具体pod的targetPort,从而进入到pod上的容器内。
使用Service服务还会涉及到几种IP:
ClusterIP
Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,但clusterIP就不一样了,没有网络设备承载这个地址。它是一个虚拟地址,由kube-proxy使用iptables规则重新定向到其本地端口,再均衡到后端Pod。当kube-proxy发现一个新的service后,它会在本地节点打开一个任意端口,创建相应的iptables规则,重定向服务的clusterIP和port到这个新建的端口,开始接受到达这个服务的连接。
Pod IP
Pod的IP,每个Pod启动时,会自动创建一个镜像为gcr.io/google_containers/pause的容器,Pod内部其他容器的网络模式使用container模式,并指定为pause容器的ID,即:network_mode: "container:pause容器ID",使得Pod内所有容器共享pause容器的网络,与外部的通信经由此容器代理,pause容器的IP也可以称为Pod IP。
节点IP
Node-IP,service对象在Cluster IP range池中分配到的IP只能在内部访问,如果服务作为一个应用程序内部的层次,还是很合适的。如果这个service作为前端服务,准备为集群外的客户提供业务,我们就需要给这个服务提供公共IP了。指定service的spec.type=NodePort,这个类型的service,系统会给它在集群的各个代理节点上分配一个节点级别的端口,能访问到代理节点的客户端都能访问这个端口,从而访问到服务。
在k8s里,你可以通过服务名去访问相同namespace里的服务,然后服务可以解析到对应的pod,从而再由pod转到对应的容器里,我们可以认为这个过程有两个port的概念,service port 就是服务的port,在k8s配置文件里用port表示,还有一个是pod和容器的port,用targetPort表示,其中pod和容器的port你可以认为它是一个。
我们通常会把mysql,redis,rabbitmq,mongodb这些公用组件放在一个namespace里,或者每个公用组件都有自己的namespace,而你的业务组件会统一放在自己的namespace里,这时就涉及到了跨namespace的数据通讯问题。
Kubernetes 目前使用的kube-dns来实现集群内部的service dns记录解析。默认情况下/etc/resolv.conf里,它的内容是统一的格式。
/ # more /etc/resolv.conf
nameserver 172.19.0.10
search saas.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
search doamin列表默认情况下,它只包含本地域名。这可以通过在search关键字后面列出所需的域搜索路径来添加。kubernetes为每个容器配置默认是${namespace}.svc.cluster.local svc.cluster.local cluster.local。在一次dns域名查询时,将会尝试使用每个search doamin依次搜索少于ndots点(默认值为1)的解析器查询,直到找到匹配项。对于具有多个子域的环境,建议调整选项ndots:n,以避免man-in-the-middle攻击和root-dns-servers的不必要通信。
这个我们可以把它理解成服务名dns解析的层次,例如{服务名}是一级,而{服务名}.{命名空间}为二层,{服务名}.{命名空间}.svc.cluster.local是第三层,上面的配置一共有5层,同时也开启了5层,这样做可以保证最大限度的找到你的服务,但对于解析的性能是有影响的。
请注意,如果搜索域对应的服务器不是本地的,那么这个查询过程可能会很慢,并且会产生大量的网络流量。如果其中一个搜索域域没有可用的服务器,则查询将超时。
如果你要连接namespace是redis的,服务名是redis-master的服务,你可以这样去配置你的连接:
spring:
profiles: redis-prod
redis:
host: redis-master.redis
port: 6379
password: 123456
database: 1
它采用了服务名+命名空间的格式,如果是相同的namespace,可以直接使用服务名来解析。
ClusterIP的方式只能在集群内部访问
NodePort方式的话,测试环境使用还行,当有几十上百的服务在集群中运行时,NodePort的端口管理是灾难。
LoadBalance方式受限于云平台,且通常在云平台部署ELB还需要额外的费用。
所幸k8s还提供了一种集群维度暴露服务的方式,也就是ingress。ingress可以简单理解为service的service,他通过独立的ingress对象来制定请求转发的规则,把请求路由到一个或多个service中。这样就把服务与请求规则解耦了,可以从业务维度统一考虑业务的暴露,而不用为每个service单独考虑,下面是一个简单的ingress应用图,实现了简单的请求转发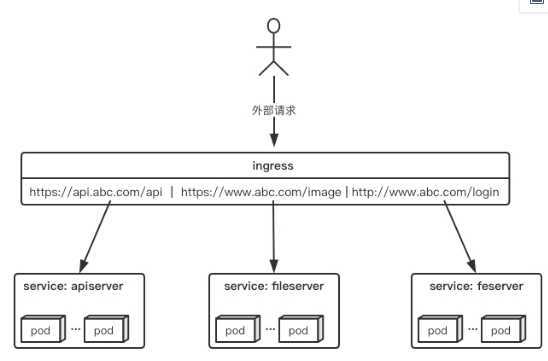
ingress对象:
指的是k8s中的一个api对象,一般用yaml配置。作用是定义请求如何转发到service的规则,可以理解为配置模板。
ingress-controller:
具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发。
简单来说,ingress-controller才是负责具体转发的组件,通过各种方式将它暴露在集群入口,外部对集群的请求流量会先到ingress-controller,而ingress对象是用来告诉ingress-controller该如何转发请求,比如哪些域名哪些path要转发到哪些服务等等。
ingress-controller并不是k8s自带的组件,实际上ingress-controller只是一个统称,用户可以选择不同的ingress-controller实现,目前,由k8s维护的ingress-controller只有google云的GCE与ingress-nginx两个,其他还有很多第三方维护的ingress-controller,具体可以参考官方文档。但是不管哪一种ingress-controller,实现的机制都大同小异,只是在具体配置上有差异。一般来说,ingress-controller的形式都是一个pod,里面跑着daemon程序和反向代理程序。daemon负责不断监控集群的变化,根据ingress对象生成配置并应用新配置到反向代理,比如nginx-ingress就是动态生成nginx配置,动态更新upstream,并在需要的时候reload程序应用新配置。为了方便,后面的例子都以k8s官方维护的nginx-ingress为例。
2 我们的ingress是支持https的,所以需要为你的域名配置对应的证书,我们在配置文件里添加
3 自动为ingress-controller里的配置文件添加nginx配置项,然后自动reload它,让它生效
当有新的ingress服务注册之后,配置文件会发生变化
4 你的服务对应的nginx是在自己服务的ymal里进行配置的,一般来说,微服务的网关层都应该建立 一个ingress-nginx来对外提供服务!

# 构建反射代理
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: hello-world-ingress
namespace: saas
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
tls:
- hosts:
- www.abc.com
secretName: saas-tls
rules:
- host: www.abc.com
http:
paths:
- backend:
serviceName: hello-world
servicePort: 9001
## start server www.abc.com
server {
server_name www.abc.com ;
listen 80 ;
listen [::]:80 ;
listen 443 ssl http2 ;
listen [::]:443 ssl http2 ;
set $proxy_upstream_name "-";
# PEM sha: c24ba9e405ed77662c0fd7546a908ef45ca76066
ssl_certificate /etc/ingress-controller/ssl/default-fake-certificate.pem;
ssl_certificate_key /etc/ingress-controller/ssl/default-fake-certificate.pem;
ssl_certificate_by_lua_block {
certificate.call()
}
location ~* "^/" {
set $namespace "saas";
set $ingress_name "hello-world-ingress";
set $service_name "hello-world";
set $service_port "{0 9001 }";
set $location_path "/";
rewrite_by_lua_block {
lua_ingress.rewrite({
force_ssl_redirect = true,
use_port_in_redirects = false,
})
balancer.rewrite()
plugins.run()
}
header_filter_by_lua_block {
plugins.run()
}
body_filter_by_lua_block {
}
log_by_lua_block {
balancer.log()
monitor.call()
plugins.run()
}
if ($scheme = https) {
more_set_headers "Strict-Transport-Security: max-age=15724800; includeSubDomains";
}
port_in_redirect off;
set $balancer_ewma_score -1;
set $proxy_upstream_name "saas-hello-world-9001";
set $proxy_host $proxy_upstream_name;
set $pass_access_scheme $scheme;
set $pass_server_port $server_port;
set $best_http_host $http_host;
set $pass_port $pass_server_port;
set $proxy_alternative_upstream_name "";
client_max_body_size 1m;
proxy_set_header Host $best_http_host;
# Pass the extracted client certificate to the backend
# Allow websocket connections
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_set_header X-Request-ID $req_id;
proxy_set_header X-Real-IP $the_real_ip;
proxy_set_header X-Forwarded-For $the_real_ip;
proxy_set_header X-Forwarded-Host $best_http_host;
proxy_set_header X-Forwarded-Port $pass_port;
proxy_set_header X-Forwarded-Proto $pass_access_scheme;
proxy_set_header X-Original-URI $request_uri;
proxy_set_header X-Scheme $pass_access_scheme;
# Pass the original X-Forwarded-For
proxy_set_header X-Original-Forwarded-For $http_x_forwarded_for;
# mitigate HTTPoxy Vulnerability
# https://www.nginx.com/blog/mitigating-the-httpoxy-vulnerability-with-nginx/
proxy_set_header Proxy "";
# Custom headers to proxied server
proxy_connect_timeout 5s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering off;
proxy_buffer_size 4k;
proxy_buffers 4 4k;
proxy_request_buffering on;
proxy_http_version 1.1;
proxy_cookie_domain off;
proxy_cookie_path off;
# In case of errors try the next upstream server before returning an error
proxy_next_upstream error timeout;
proxy_next_upstream_timeout 0;
proxy_next_upstream_tries 3;
proxy_pass http://upstream_balancer;
proxy_redirect off;
}
}
## end server www.abc.com
查看所有 pod 列表, -n 后跟 namespace, 查看指定的命名空间
kubectl get pod
kubectl get pod -n kube
kubectl get pod -o wide
查看 RC 和 service 列表, -o wide 查看详细信息
kubectl get rc,svc
kubectl get pod,svc -o wide
kubectl get pod <pod-name> -o yaml
显示 Node 的详细信息
kubectl describe node 192.168.0.212
显示 Pod 的详细信息, 特别是查看 pod 无法创建的时候的日志
kubectl describe pod <pod-name>
eg:
kubectl describe pod redis-master-tqds9
根据 yaml 创建资源, apply 可以重复执行,create 不行
kubectl create -f pod.yaml
kubectl apply -f pod.yaml
基于 pod.yaml 定义的名称删除 pod
kubectl delete -f pod.yaml
删除所有包含某个 label 的pod 和 service
kubectl delete pod,svc -l name=<label-name>
删除所有 Pod
kubectl delete pod --all
查看 endpoint 列表
kubectl get endpoints
执行 pod 的 date 命令
kubectl exec <pod-name> -- date
kubectl exec <pod-name> -- bash
kubectl exec <pod-name> -- ping 10.24.51.9
通过bash获得 pod 中某个容器的TTY,相当于登录容器
kubectl exec -it <pod-name> -c <container-name> -- bash
eg:
kubectl exec -it redis-master-cln81 -- bash
查看容器的日志
kubectl logs <pod-name>
kubectl logs -f <pod-name> # 实时查看日志
kubectl log <pod-name> -c <container_name> # 若 pod 只有一个容器,可以不加 -c
查看注释
kubectl explain pod
kubectl explain pod.apiVersion
做为 Kubernetes 的一个包管理工具,Helm具有如下功能:
本文中讲到的是helm V2最新版本,V3版本也已经发布了beta版,在 Helm 3 中,Tiller 被移除了。
Helm
Helm 是一个命令行下的客户端工具。主要用于 Kubernetes 应用程序 Chart 的创建、打包、发布以及创建和管理本地和远程的 Chart 仓库。
Tiller
Tiller 是 Helm 的服务端,部署在 Kubernetes 集群中。Tiller 用于接收 Helm 的请求,并根据 Chart 生成 Kubernetes 的部署文件( Helm 称为 Release ),然后提交给 Kubernetes 创建应用。Tiller 还提供了 Release 的升级、删除、回滚等一系列功能。
Chart
包含了创建Kubernetes的一个应用实例的必要信息,Helm 的软件包,采用 TAR 格式。类似于 APT 的 DEB 包或者 YUM 的 RPM 包,其包含了一组定义 Kubernetes 资源相关的 YAML 文件。
Repoistory
Helm 的软件仓库,Repository 本质上是一个 Web 服务器,该服务器保存了一系列的 Chart 软件包以供用户下载,并且提供了一个该 Repository 的 Chart 包的清单文件以供查询。Helm 可以同时管理多个不同的 Repository。
Release
是一个 chart 及其配置的一个运行实例,使用 helm install 命令在 Kubernetes 集群中部署的 Chart 称为 Release。
Chart Install 过程
Helm 从指定的目录或者 TAR 文件中解析出 Chart 结构信息。
Helm 将指定的 Chart 结构和 Values 信息通过 gRPC 传递给 Tiller。
Tiller 根据 Chart 和 Values 生成一个 Release。
Tiller 将 Release 发送给 Kubernetes 用于生成 Release。
Chart Update 过程
Helm 从指定的目录或者 TAR 文件中解析出 Chart 结构信息。
Helm 将需要更新的 Release 的名称、Chart 结构和 Values 信息传递给 Tiller。
Tiller 生成 Release 并更新指定名称的 Release 的 History。
Tiller 将 Release 发送给 Kubernetes 用于更新 Release。
Chart Rollback 过程
Helm 将要回滚的 Release 的名称传递给 Tiller。
Tiller 根据 Release 的名称查找 History。
Tiller 从 History 中获取上一个 Release。
Tiller 将上一个 Release 发送给 Kubernetes 用于替换当前 Release。
Chart 处理依赖说明
Tiller 在处理 Chart 时,直接将 Chart 以及其依赖的所有 Charts 合并为一个 Release,同时传递给 Kubernetes。因此 Tiller 并不负责管理依赖之间的启动顺序。Chart 中的应用需要能够自行处理依赖关系。
上一讲说了一些helm的基本概念,而今天主要说一下如何把helm部署到服务器上,在helm3之前的版本里,它由客户端helm和服务端tiller组成,而helm3.0之后它去掉了tiller,而直接与k8s通讯,可以说在部署上更简单了,而今天我们主要还是部署2.x版本的helm.
https://get.helm.sh/helm-v2.16.5-linux-amd64.tar.gz
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
kubectl create -f rbac-config.yaml
helm init --service-account tiller --skip-refresh
对于 Kubernetes v1.16.0 以上的版本,有可能会碰到 Error: error installing: the server could not find the requested resource 的错误。这是由于 extensions/v1beta1 已经被 apps/v1 替代。相信在2.15 或者 3 版本发布之后, 应该就不会遇到这个问题了。还是生态比较慢的原因。
helm init -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.3 --stable-repo-url http://mirror.azure.cn/kubernetes/charts/ --service-account tiller --override spec.selector.matchLabels.‘name‘=‘tiller‘,spec.selector.matchLabels.‘app‘=‘helm‘ --output yaml | sed ‘s@apiVersion: extensions/v1beta1@apiVersion: apps/v1@‘ | kubectl apply -f -
kubectl get pods -n kube-system | grep tiller
tiller-deploy-7c7b67c9fd-kxh6p 1/1 Running 0 4m58s
到现在为止,我们的helm就安装功能了,之后我们装运行helm来进行charts的安装
上级讲了helm2的安装,并且在安装过程中可能会出现问题,主要是与k8s版本冲突的问题,而最新的helm3对整个helm的架构都有了一个改进,它只有一个客户端的helm程序,由它进行连接k8s集群,完成对charts的部署工作。
https://get.helm.sh/helm-v3.0.0-linux-amd64.tar.gz
[root@i-pcwovafu bin]# helm env
HELM_NAMESPACE="default"
HELM_KUBECONTEXT=""
HELM_BIN="helm"
HELM_DEBUG="false"
HELM_PLUGINS="/root/.local/share/helm/plugins"
HELM_REGISTRY_CONFIG="/root/.config/helm/registry.json"
HELM_REPOSITORY_CACHE="/root/.cache/helm/repository"
HELM_REPOSITORY_CONFIG="/root/.config/helm/repositories.yaml"
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
helm repo update
这一步非常关键,它是helm与k8s通讯的保证,这一步就是把k8s环境变量KUBECONFIG进行配置
export KUBECONFIG=/root/.kube/config #可以写到/etc/profile里
[root@i-pcwovafu ~]# helm search hub nginx
URL CHART VERSION APP VERSION DESCRIPTION
https://hub.helm.sh/charts/choerodon/nginx-file... 0.1.0 1.13.5-alpine A Helm chart for Kubernetes
https://hub.helm.sh/charts/cloudposse/nginx-ing... 0.1.8 A Helm chart for Nginx Ingress
https://hub.helm.sh/charts/cloudposse/nginx-def... 0.5.0 A Helm chart for nginx-default-backend to be us...
https://hub.helm.sh/charts/cloudposse/fail-whale 0.1.1 A Helm chart that provides a mainte
helm create nginx
helm nignx-demo ./nginx
[root@i-pcwovafu bin]# rancher kubectl get pods -n default
NAME READY STATUS RESTARTS AGE
web-nginx-858f7d9cc5-hlhkj 1/1 Running 0 2m14s
也可以使用helm命令来查看
[root@i-pcwovafu bin]# helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
web-nginx default 1 2020-04-07 17:09:53.480335758 +0800 CST deployed nginx-0.1.0 1.16.0
这样一个最简单的helm应用就建立好了!
helm create hello-world
Chart.yaml 用于描述这个Chart的相关信息,包括名字、描述信息以及版本等。
仅仅是一些简单的文本描述
values.yaml 用于存储 templates 目录中模板文件中用到变量的值。
NOTES.txt 用于介绍 Chart 部署后的一些信息,例如:如何使用这个 Chart、列出缺省的设置等。
Templates 目录下是 YAML 文件的模板,该模板文件遵循 Go template 语法。
Templates 目录下 YAML 文件模板的值默认都是在 values.yaml 里定义的,比如在 deployment.yaml 中定义的容器镜像。
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
其中的 .Values.image.repository 的值就是在 values.yaml 里定义的 nginx,.Values.image.tag 的值就是 stable。
以上两个变量值是在 create chart 的时候就自动生成的默认值,你可以根据实际情况进行修改。实际上都是静态文本,只在是执行的时候才被解析.
打开 Chart.yaml,可以看到内容如下,配置名称和版本
apiVersion: v1
appVersion: "1.0"
description: A Helm chart for Kubernetes
name: mychart
version: 0.1.0
编辑 values.yaml,它默认会在 Kubernetes 部署一个 Nginx。下面是 mychart 应用的 values.yaml 文件的内容:
$ cat mychart/values.yaml
# Default values for mychart.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
image:
repository: nginx
tag: stable
pullPolicy: IfNotPresent
service:
type: ClusterIP
port: 80
ingress:
enabled: false
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
path: /
hosts:
- chart-example.local
tls: []
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
resources: {}
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after ‘resources:‘.
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi
nodeSelector: {}
tolerations: []
affinity: {}
$ helm lint hello-world/
helm package hello-world
helm package mychart --debug #显示详细信息
helm serve --repo-path /data/helm/repository/ --url http://172.17.0.22:8879/charts/ &
$ helm repo update
$ helm search mychart
NAME CHART VERSION APP VERSION DESCRIPTION
local/hello-world 0.1.0 1.0 A Helm chart for Kubernetes
Chart 被发布到仓储后,就可以通过 helm install 命令部署该 Chart。
helm install hello local/hello-world
helm status wordpress
helm upgrade wordpress stable/wordpress
helm upgrade --install --force hello-world ./hello.tgz --namespace test # 也可以指定命名空间和它的taz包
helm rollback hello-world 1 # 向上归滚一个版本
可以在requirements.yaml里去配置它的依赖关系, 它支持两种方式表示依赖关系,可以使用requirements.yaml或者直接将依赖的Chart放置到charts目录中。
dependencies:
- name: mariadb
version: 7.x.x
repository: https://kubernetes-charts.storage.googleapis.com/
condition: mariadb.enabled
tags:
- wordpress-database
templates目录下的yaml文件,遵循Go template语法。使用过Hugo的静态网站生成工具的人应该对此很熟悉。
templates目录中存放了Kubernetes部署文件的模版,比如deployment.yaml,service.yaml等,它里面引用的变量来自values.yaml里
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
上面的{{ .Values.image.repository }}表示values.yaml文件里的image节点下的repository元素的内容
k8s应用(包括有状态跟无状态应用),需要使用数据卷的话,需要在存储卷中进行设置和声明,下面列出持久化数据卷的声明跟设置的模板:
数据卷设置:
apiVersion: v1
kind: PersistentVolume -这里说明是持久化数据卷
metadata:
finalizers:
- kubernetes.io/pv-protection
labels:
alicloud-pvname: {{ .Values.volumes.name }} -数据卷标签,eg:XXX-data
name: {{ .Values.volumes.name }} -数据卷名称,eg:XXX-data
spec:
accessModes:
- ReadWriteMany -权限
capacity:
storage: {{ .Values.volumes.storage }} -容量大小,eg:10Gi
flexVolume:
driver: alicloud/nas -数据卷类型是nas
options:
path: {{ .Values.volumes.path }} -数据卷路径,eg:/tmp
server: {{ .Values.volumes.server }} -数据卷服务商,eg:xxxxx.nas.aliyuncs.com
vers: ‘3‘
persistentVolumeReclaimPolicy: Retain
storageClassName: nas
数据卷声明:
apiVersion: v1
kind: PersistentVolumeClaim -持久化数据卷声明
metadata:
annotations:
pv.kubernetes.io/bind-completed: ‘yes‘
pv.kubernetes.io/bound-by-controller: ‘yes‘
finalizers:
- kubernetes.io/pvc-protection
name: {{ .Values.volumes.name }}
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: {{ .Values.volumes.storage }} -容量,eg:10Gi
selector:
matchLabels:
alicloud-pvname: {{ .Values.volumes.name }}
storageClassName: nas
volumeName: {{ .Values.volumes.name }}
应用弹性伸缩配置,这个可以配置最大、最小副本集跟伸缩条件的参数到values.yaml文件里面
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v1
metadata:
name: {{ include "admin.appname" . }}-hpa -admin.appname就是后面执行helm命令的时候倒数第二个参数,为什么前面是admin呢,admin就是你配置Chart.yaml的时候里面的name变量的值
spec:
scaleTargetRef:
kind: Deployment
name: {{ include "admin.appname" . }}
apiVersion: apps/v1beta2
minReplicas: 1 -最小副本集
maxReplicas: 10 -最大副本集
targetCPUUtilizationPercentage: 70 -伸缩条件
配置项设置,一般每个项目有都对应的环境参数,比如:数据库、redis等这些账号密码类的参数,这些可以抽离出来当成一个配置项处理
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Values.envConfigName }} -每个环境就配置一个配置项
data:
{{- range $k, $v := .Values.configDatas }} -这里是循环遍历configDatas这个变量
{{ $k | indent 2 }}.yml: >- -下面这两行配置一个key->value的配置项(即文件名->文件内容)
{{ $v | indent 4 }}
{{- end -}}
将镜像的密码配置到保密字典中
apiVersion: v1
kind: Secret
metadata:
name: image-secret -name随意写
data:
.dockerconfigjson: {{ .Files.Get "image.pwd" | b64enc }} -内容
type: kubernetes.io/dockerconfigjson
TLs证书配置(后面配置ingress的时候要用到,不然无法用https)
apiVersion: v1
kind: Secret
metadata:
name: tls-secret
data:
tls.crt: {{ .Files.Get "XXXXX.com.pem" | b64enc }}
tls.key: {{ .Files.Get "XXXXX.com.key" | b64enc }}
type: Opaque
下次主要说一下几个重要的yaml文件的模板。
原文:https://www.cnblogs.com/xinfang520/p/13221203.html