算法步骤:
Python实现:
import pylab as pl
def calc_e_squire(a, b):
return (a[0]-b[0]) ** 2 + (a[1]-b[1]) ** 2
# 20 data points
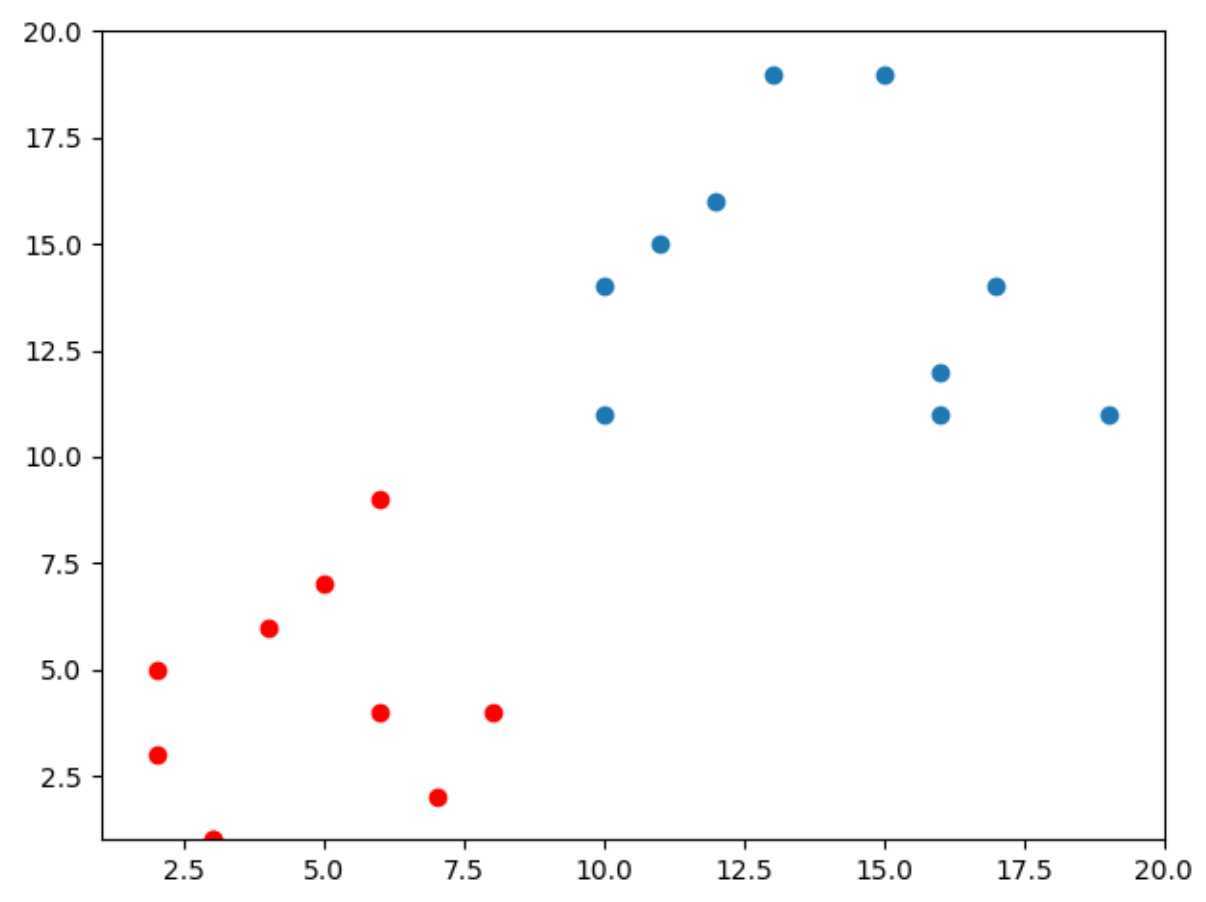
a = [2,4,3,6,7,8,2,3,5,6,12,10,15,16,11,10,19,17,16,13]
b = [5,6,1,4,2,4,3,1,7,9,16,11,19,12,15,14,11,14,11,19]
# initialize two points as the center of the clusters
k1 = [6, 3]
k2 = [6, 1]
# store clusters in lists
sse_k1 = []
sse_k2 = []
while True:
sse_k1 = []
sse_k2 = []
for i in range(20):
e_squire1 = calc_e_squire(k1, [a[i], b[i]])
e_squire2 = calc_e_squire(k2, [a[i], b[i]])
if (e_squire1 <= e_squire2):
sse_k1.append(i)
else:
sse_k2.append(i)
# change the centers of the clusters
k1_x = sum([a[i] for i in sse_k1]) / len(sse_k1)
k1_y = sum([b[i] for i in sse_k1]) / len(sse_k1)
k2_x = sum([a[i] for i in sse_k2]) / len(sse_k2)
k2_y = sum([b[i] for i in sse_k2]) / len(sse_k2)
if k1 != [k1_x, k1_y] or k2 != [k2_x, k2_y]:
k1 = [k1_x, k1_y]
k2 = [k2_x, k2_y]
else: # the centers of the clusters don‘t change any more
break
kv1_x = [a[i] for i in sse_k1]
kv1_y = [b[i] for i in sse_k1]
kv2_x = [a[i] for i in sse_k2]
kv2_y = [b[i] for i in sse_k2]
pl.plot(kv1_x, kv1_y, ‘o‘)
pl.plot(kv2_x, kv2_y, ‘or‘)
pl.xlim(1, 20)
pl.ylim(1, 20)
pl.show()
运行结果:
参考资料:
原文:https://www.cnblogs.com/picassooo/p/13221328.html