算法流程参考了《统计学习与方法》
import numpy as np
import pandas as pd
from graphviz import Digraph
class BaseTree(object):
def __init__(self, feature, label, title=None):
"""
树基本属性
:param feature: 特征列
:param label: 目标列
:param title: 标题列
"""
self.root = {}
self.feature = feature
self.label = label
self.title = title
self.n_classes = tuple(set(label))
self.n_features = len(feature)
self._build_tree_(self.root, self.label, self.feature, self.title)
def _build_tree_(self, n, label, feature, title):
"""
递归构建决策树
:param n: 对每一层来说该参数是树的当前节点 字典树
:param label: 每一层递归中目标列会由于上一层中做出的选择而不断减小
:param feature: 每一层递归中特征也会由于前一层中做出的选择而不断减小 对于一条路径来说 会减少特征列
:param title: 标题原理同 label
:return:
"""
if feature is not None:
gain_feature = self._solve_gain_(label, feature, tuple(set(label)), len(feature))
select_feature = np.argmax(gain_feature)
selected_feature = feature[:, select_feature]
states = set(selected_feature)
n[title[select_feature]] = {}
feature = np.delete(feature, select_feature, axis=1)
title_ = np.delete(title, select_feature)
for i, _ in enumerate(states):
inx = np.where(selected_feature == _)[0]
label_ = label[inx]
if len(set(label_)) == 1:
n[title[select_feature]][str(label_[0])] = {}
continue
feature_ = feature[inx]
self._build_tree_(n[title[select_feature]], label_, feature_, title_)
@staticmethod
def _solve_entropy_(label, n_classes, n_features):
"""
计算经验熵
:param label:
:param n_classes:
:param n_features:
:return:
"""
sigma = 0.
for _ in n_classes:
p = len(np.where(label == _)[0]) / n_features
sigma += (p * np.log2(p) if p != 0 else 0)
return -sigma
def _solve_conditional_entropy_(self, label, feature, n_classes):
"""
计算条件熵
:param label:
:param feature:
:param n_classes:
:return:
"""
group_states = [tuple(set(_)) for _ in feature.transpose()]
n_features = len(feature)
ans = []
for i, branch in enumerate(group_states):
res = 0.
for state in branch:
inx = np.where(feature[:, i] == state)[0]
n_f = len(inx)
sigma = self._solve_entropy_(label[inx], n_classes, n_f)
res += n_f / n_features * sigma
ans.append(res)
return np.array(ans)
def _solve_gain_(self, label, feature, n_classes, n_features):
"""
计算信息增益
:param label:
:param feature:
:param n_classes:
:param n_features:
:return:
"""
return self._solve_entropy_(label, n_classes, n_features) - self._solve_conditional_entropy_(label, feature, n_classes)
def get_root(self):
"""
获取决策树
:return:
"""
return self.root
class DecisionTree(object):
def __init__(self, title=None):
self.tree = None
self.title = title
self.que = []
self.nums = []
self.count = 1
def fit(self, X, y):
"""
拟合接口
:param X: 数据集的特征
:param y: 数据集的目标
:return:
"""
self.tree = BaseTree(X, y, self.title)
def predict(self, X):
pass
def decision_tree_struct(self):
"""
获取决策树
:return:
"""
return self.tree.get_root()
def _travl_dict_(self, dot, node):
"""
层序遍历字典树以生成 graph
:param dot:
:param node:
:return:
"""
for _ in node.keys():
s = str(self.nums.pop(0) if self.nums else ‘0‘)
self.que.append(node[_])
for i, k in enumerate(node[_].keys()):
dot.edge(_ + ‘_‘ + s, k + ‘_‘ + str(self.count),
label=‘Yes‘ if i & 1 else ‘No‘)
self.nums.append(self.count)
self.count += 1
if self.que:
self._travl_dict_(dot, self.que.pop(0))
def generate_graph(self):
"""
生成决策树图
:return:
"""
dot = Digraph(name=‘tree‘, node_attr={‘shape‘: ‘circle‘}, format=‘png‘)
self._travl_dict_(dot, self.tree.get_root())
dot.render(‘decision.gv‘, view=True)
data = pd.read_csv(‘data.csv‘, encoding=‘gbk‘)
y = data[‘index‘].astype(np.int)
train_x = data.drop([‘index‘, ‘name‘], axis=1)
for _ in train_x.keys():
train_x[_] = train_x[_].map({‘是‘: 1, ‘否‘: 0})
title = list(train_x.keys())
dt = DecisionTree(title)
X = train_x.values.reshape((-1, len(title)))
dt.fit(X, y.values)
d = dt.decision_tree_struct()
print(d)
dt.generate_graph()
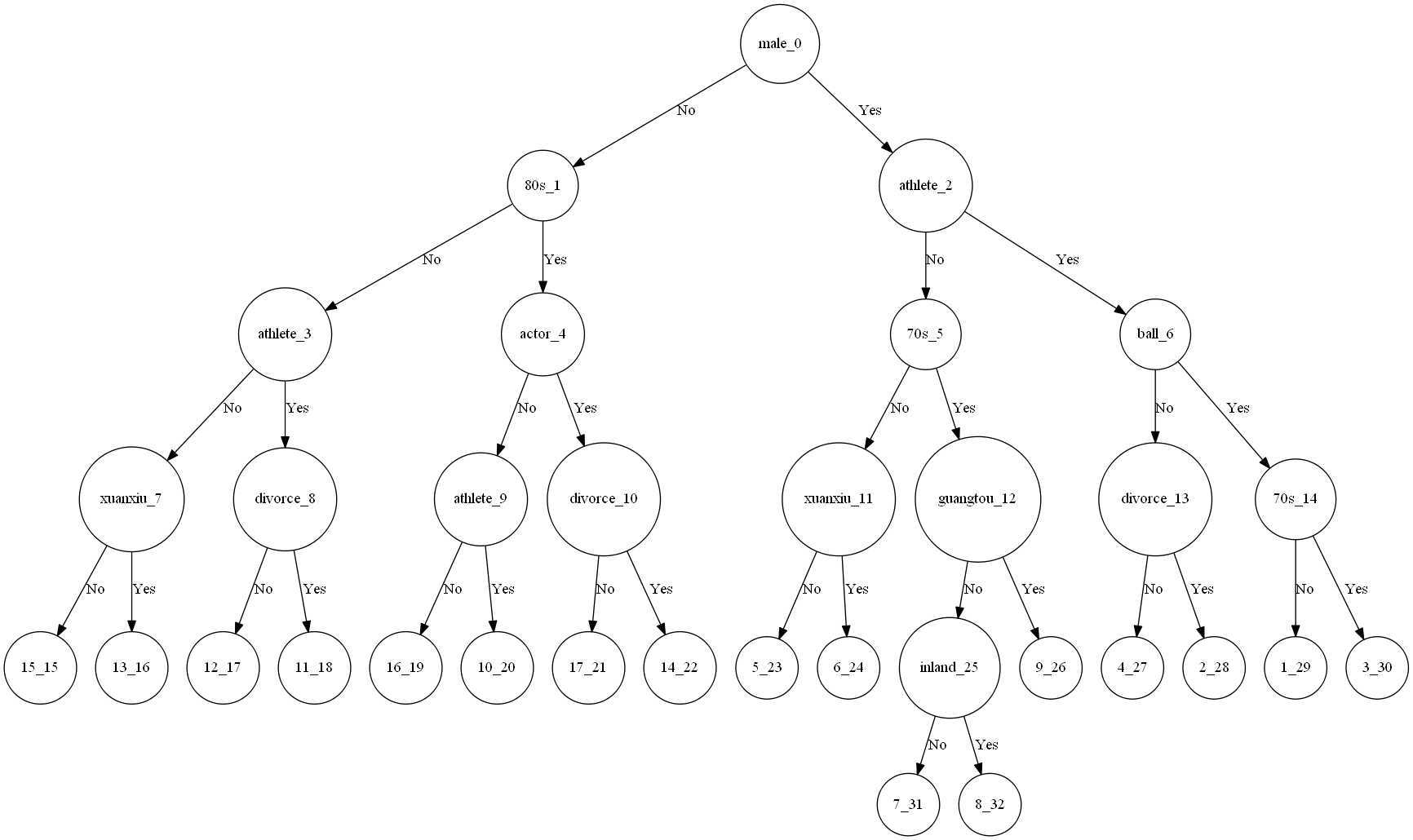
因为没有设置 graphviz 中文字体,所以无法正常显示,使用 index 代替了。
测试数据:
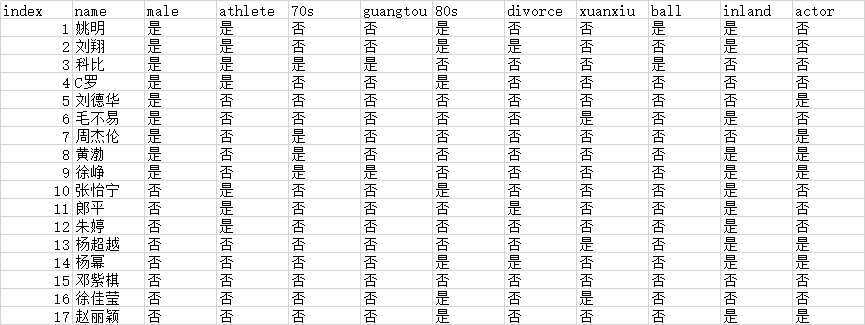
graphviz 查看生成的决策树结构:
原文:https://www.cnblogs.com/darkchii/p/13207599.html