爬虫,又称网页蜘蛛或者网络机器人。
爬虫是模拟人操作客户端(浏览器,App) 向服务器发起网络请求 抓取数据的自动化程序或脚本。(*****)
Pyinstaller
# 说明:
1.模拟: 用爬虫程序伪装处人的行为,避免被服务器识别为爬虫程序
2.客户端:浏览器,app都可以实现人与服务器之间的交互行为,应用客户端从服务器获取数据
3.自动化:数据量较小时可以人工获取数据,但往往在公司中爬取数据量在百万条,千万条级别的,所以要程序自动化获取数据。
# 爬虫语言:PHP,C/C++,Java,Python,GoLang,nodejs
# 对比:
PHP:并发能力差,对多进程和多线程支持不好,数据列较大时,爬虫效率较低
C/C++:语言效率高,但学习成本高,对程序员的奇数能力要求较高,所以目前还停留在研究曾面,市场需求量很小
Java:Python爬虫的主要竞争对手,由于Java语言的特点,代码臃肿,代码量大,维护成本重构成本高,开发效率低,但目前市场上岗位需求比较旺盛。
Python:语法简单,学习成本较低,对新手比较友好,Python语言良好的生态,大量库和框架的支持使的Python爬虫目前处于爬虫圈的主导地位。
#### 1.3 爬虫分类
(1).通用爬虫
?(2).聚焦爬虫
?(3).增量式爬虫
?(4).深度爬虫
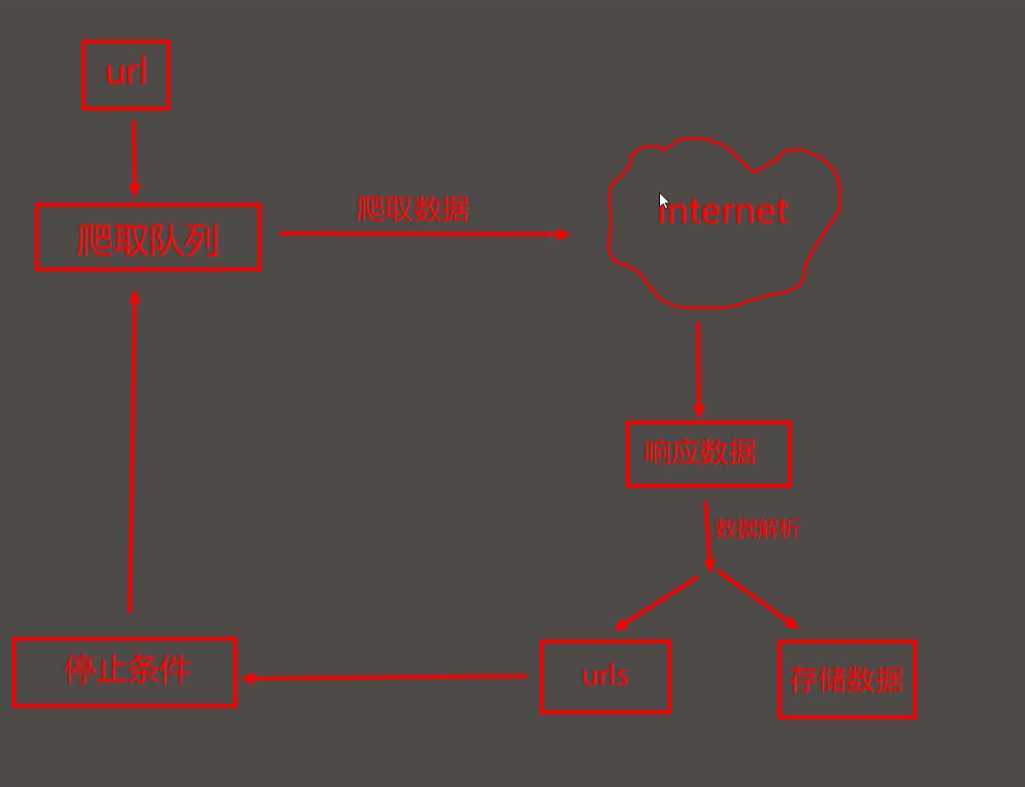
?#工作流:
? 1. 给定一个其实URL,存于爬虫队列中
2. 爬虫程序从队列中取出url,爬取数据
3. 解析爬取数据,获取网页内容的所有url,需要的数据,放入爬虫队列
4. 重读第二个
?#使搜索引擎获取网站链接:
1. 主动将url提交给搜索引擎 (https://ziyuan.baidu.com/linksubmit/url)
? ? 2.在其他热门网站设置友情链接
? ? 3.百度和DNS服务合作,收录新网站
# 网站排名(SEO):
? 1.根据PageRank值进行拍名(流量,点击率)
? 2.百度竞价排名,钱多就靠前
#缺点:
1.抓取的内容多数无用
2.无法精确获取数据
#协议:robots协议 --> 规定哪些内容不允许哪些爬虫抓取
1.无需遵守,该协议适用于同用爬虫也适用于拒绝爬虫,而我们写的是聚焦爬虫
? 2.查看方法:网站url/robots/txt,例如https://ww.baidu.com/robots.txt
2.聚焦爬虫
# 概念:
聚焦爬虫指对某一领域根据特定要求实现的爬虫程序,抓取需要的数据(垂直领域爬取)
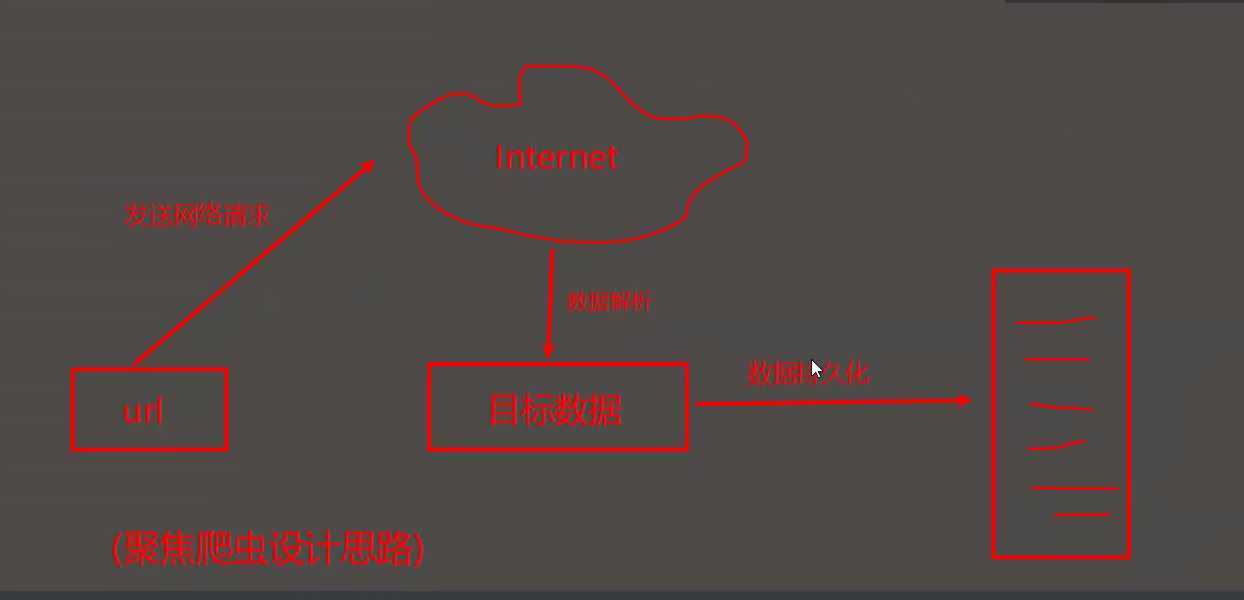
# 设计思路: *****
(1). 确定爬取的url,模拟浏览器向服务器发送请求获取响应数据
(2). 进行数据解析--> 目标数据
(3). 将目标数据持久化到本地--> 存起来了
1.请求库的学习
2.解析库的学习
3.反爬机制与反反爬策略
UA检测
动态数据加载:JS 动态数据加载,Ajax数据加载
IP封禁
账号封禁
验证码
数据加密
图片懒加载
4. scrapy爬虫框架
5. 增量式爬虫,全栈数据爬去
6. 总结与串讲原文:https://www.cnblogs.com/xiangnuan/p/13207703.html