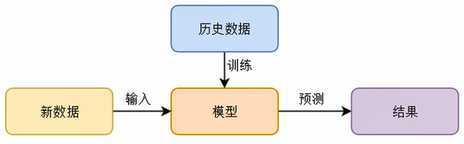
feature【特征变量】 ——》 label【结果标签】
收集问题相关的数据(feature、label)——》
选择一种数学模型建立feature和label的关系 ——》
根据选择的模型进行预测
knn
key nearest neighbor
大致步骤:
1、收集相关的数据
2、选择合适的feature 和label
3、如果不知道如何选择feature,可以先单独让每个feature计算与label的相关度
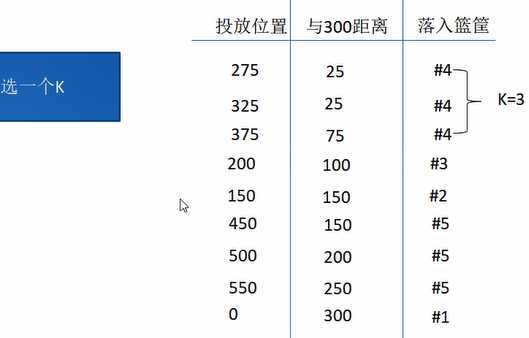
4、选择合适的k
5、使用数据集进行合适的预测
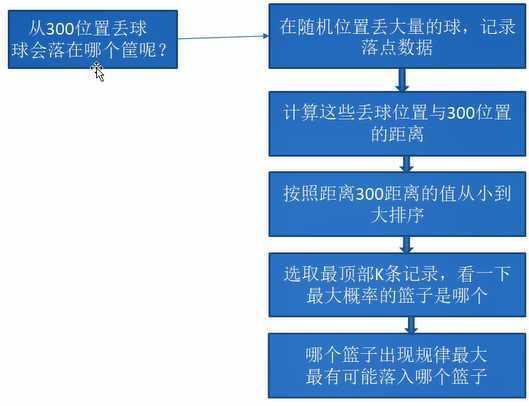
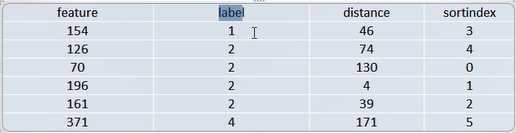
从300处丢一个球,会落到哪个窗口?

解决流程:
代码:
import numpy as np import collections as c
#数据集的准备【在这里是手动输入】 data = np.array([ [154,1], [126,2], [70,2], [196,2], [161,2], [371,4] ]) #输入值 feature = (data[:,0]) #结果label label = data[:,-1] #预测点 predictPoint = 200 #计算每一个投掷点距离predictPoint的距离 distance = list(map(lambda x: abs(predictPoint - x),feature)) #对distance的集合 元素从小到大排序(返回的是排序的下标位置) sortindex = (np.argsort(distance)) #用排序的sortindex来操作 label集合 sortlabel = (label[sortindex]) # knn算法的k :取最近的三个数据 k = 3 print(c.Counter(sortlabel[0:k]).most_common(1)[0][0])
补充:
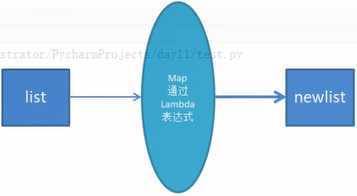
1、map函数
是python 内置的高阶函数,它接收一个函数f 和一个list ,并通过把函数f 依次作用在list的每一个元素上,并得到一个新的list,并返回
2、排序
np.sort:把集合直接按值排序
np.argsort :把集合元素按照下标,或者位置去排序,得到 sortindex
import numpy as np import collections as c def knn(k,feature,label,predictPoint): # 计算每一个投掷点距离predictPoint的距离 distance = list(map(lambda x: abs(predictPoint - x), feature)) # 对distance的集合 元素从小到大排序(返回的是排序的下标位置) sortindex = (np.argsort(distance)) # 用排序的sortindex来操作 label集合 sortlabel = (label[sortindex]) return c.Counter(sortlabel[0:k]).most_common(1)[0][0] if __name__== ‘__main__‘: data = np.array([ [154,1], [126,2], [70,2], [196,2], [161,2], [371,4] ]) #输入值 feature = (data[:,0]) #结果label label = data[:,-1] #预测点 predictPoint = 200 # knn算法的k :取最近的三个数据 k = 3 print(knn(k,feature,label,predictPoint))
导入训练集和测试集:
参考:数据集的生成
import numpy as np import collections as c #导入数据集 data = np.loadtxt("cnn0.csv",delimiter = ",") #打散数据 np.random.shuffle(data) """ 把数据集打散,拆分成训练集和测试集 训练数据是测试数据的十倍 """ testdata = data[0:100] traindata = data[100:-1] #数据集保存成csv文件,自动生成的 np.savetxt("data0-test.csv",testdata,delimiter = ",",fmt = "%d") np.savetxt("data0-train.csv",traindata,delimiter = ",",fmt = "%d") def knn(k,predictPoint,feature,label): # 计算每一个投掷点距离predictPoint的距离 distance = list(map(lambda x: abs(predictPoint - x), feature)) # 对distance的集合 元素从小到大排序(返回的是排序的下标位置) sortindex = (np.argsort(distance)) # 用排序的sortindex来操作 label集合 sortlabel = (label[sortindex]) return c.Counter(sortlabel[0:k]).most_common(1)[0][0] if __name__== ‘__main__‘: #导入训练集 traindata = np.loadtxt("data0-train.csv",delimiter = ",") #输入值 feature = (traindata[:,0]) #结果label label = traindata[:,-1] #导入测试集 testdata = np.loadtxt("data0-test.csv",delimiter = ",") # knn算法的k :取最近的k个数据 for k in range(1,50): count = 0 for item in testdata: predict = knn(k,item[0],feature,label) real = item[-1] if predict == real: count = count + 1 print(f‘k = {k},准确率 : {count * 100.0 / len(testdata)}%‘) """ k = 1,准确率 : 14.0% k = 2,准确率 : 14.0% k = 3,准确率 : 17.0% k = 4,准确率 : 15.0% k = 5,准确率 : 15.0% k = 6,准确率 : 9.0% k = 7,准确率 : 13.0% k = 8,准确率 : 8.0% k = 9,准确率 : 10.0% k = 10,准确率 : 12.0% k = 11,准确率 : 8.0% k = 12,准确率 : 11.0% k = 13,准确率 : 10.0% k = 14,准确率 : 10.0% k = 15,准确率 : 11.0% k = 16,准确率 : 13.0% k = 17,准确率 : 13.0% k = 18,准确率 : 11.0% k = 19,准确率 : 9.0% k = 20,准确率 : 8.0% k = 21,准确率 : 6.0% k = 22,准确率 : 6.0% k = 23,准确率 : 6.0% k = 24,准确率 : 7.0% k = 25,准确率 : 8.0% k = 26,准确率 : 7.0% k = 27,准确率 : 9.0% k = 28,准确率 : 10.0% k = 29,准确率 : 11.0% k = 30,准确率 : 13.0% k = 31,准确率 : 13.0% k = 32,准确率 : 10.0% k = 33,准确率 : 10.0% k = 34,准确率 : 10.0% k = 35,准确率 : 11.0% k = 36,准确率 : 11.0% k = 37,准确率 : 14.0% k = 38,准确率 : 12.0% k = 39,准确率 : 13.0% k = 40,准确率 : 16.0% k = 41,准确率 : 16.0% k = 42,准确率 : 15.0% k = 43,准确率 : 16.0% k = 44,准确率 : 18.0% k = 45,准确率 : 17.0% k = 46,准确率 : 13.0% k = 47,准确率 : 13.0% k = 48,准确率 : 13.0% k = 49,准确率 : 15.0% """
注意:
经验所得,参数k值一般选为 【训练集数据的开平方】为最优
import numpy as np import collections as c def knn(k,predictPoint,feature,label): # 计算每一个投掷点距离predictPoint的距离 distance = list(map(lambda x: abs(predictPoint - x), feature)) # 对distance的集合 元素从小到大排序(返回的是排序的下标位置) sortindex = (np.argsort(distance)) # 用排序的sortindex来操作 label集合 sortlabel = (label[sortindex]) return c.Counter(sortlabel[0:k]).most_common(1)[0][0] if __name__== ‘__main__‘: #导入训练集 traindata = np.loadtxt("data0-train.csv",delimiter = ",") #输入值 feature = (traindata[:,0]) #结果label label = traindata[:,-1] #导入测试集 testdata = np.loadtxt("data0-test.csv",delimiter = ",") # knn算法的k :取最近的k个数据 count = 0 k = int(len(traindata)**0.5) for item in testdata: predict = knn(k,item[0],feature,label) real = item[1] if predict == real: count = count + 1 print(f‘k = {k},准确率 : {count * 100.0 / len(testdata)}%‘) """ k = 69,准确率 : 16.0% """
例如:特征变量增加一个颜色项,特征变量为两个
数据集获取:参考
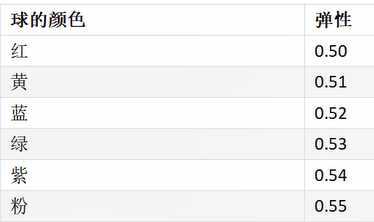
二维空间distance的计算:

代码:
import numpy as np import collections as c #将颜色转换为弹性数 def color2num(str): dict = {"红":0.50,"黄":0.51,"蓝":0.52,"绿":0.53,"紫":0.54,"粉":0.55} return dict[str] #导入数据集 data = np.loadtxt("cnn1.csv",delimiter = ",",converters={1:color2num},encoding="gbk") #打散数据 np.random.shuffle(data) """ 把数据集打散,拆分成训练集和测试集 训练数据是测试数据的十倍 """ testdata = data[0:100] traindata = data[100:-1] #数据集保存成csv文件,自动生成的 np.savetxt("data1-test.csv",testdata,delimiter = ",",fmt = "%.2f") np.savetxt("data1-train.csv",traindata,delimiter = ",",fmt = "%.2f") def knn(k,predictPoint,ballcolor,feature,label): # 计算每一个投掷点距离predictPoint的距离 # 此时的feature: [ [130.0.55],[200,0.52],...] distance = list(map(lambda item:((item[0] - predictPoint)**2 + (item[1] - ballcolor)**2)**0.5, feature)) # 对distance的集合 元素从小到大排序(返回的是排序的下标位置) sortindex = (np.argsort(distance)) # 用排序的sortindex来操作 label集合 sortlabel = (label[sortindex]) return c.Counter(sortlabel[0:k]).most_common(1)[0][0] if __name__== ‘__main__‘: #导入训练集 traindata = np.loadtxt("data1-train.csv",delimiter = ",") #输入值,取第一列和第二列 feature = (traindata[:,0:2]) #结果label label = traindata[:,-1] #导入测试集 testdata = np.loadtxt("data1-test.csv",delimiter = ",") # knn算法的k :取最近的k个数据 count = 0 k = int(len(traindata)**0.5) for item in testdata: predict = knn(k,item[0],item[1],feature,label) real = item[-1] if predict == real: count = count + 1 print(f‘k = {k},准确率 : {count * 100.0 / len(testdata)}%‘) """ k = 69,准确率 : 19.0% """

代码:
import numpy as np import collections as c #将颜色转换为弹性数 def color2num(str): dict = {"红":0.50,"黄":0.51,"蓝":0.52,"绿":0.53,"紫":0.54,"粉":0.55} return dict[str] #导入数据集 data = np.loadtxt("cnn1.csv",delimiter = ",",converters={1:color2num},encoding="gbk") #打散数据 np.random.shuffle(data) """ 把数据集打散,拆分成训练集和测试集 训练数据是测试数据的十倍 """ testdata = data[0:100] traindata = data[100:-1] #数据集保存成csv文件,自动生成的 np.savetxt("data1-test.csv",testdata,delimiter = ",",fmt = "%.2f") np.savetxt("data1-train.csv",traindata,delimiter = ",",fmt = "%.2f") def knn(k,predictPoint,ballcolor,feature,label): # 计算每一个投掷点距离predictPoint的距离 # 此时的feature: [ [130.0.55],[200,0.52],...] # 数据归一化 distance = list(map(lambda item:(((item[0]-1)/799 - (predictPoint-1)/799)**2 + ((item[1]-0.50)/0.05 - (ballcolor-0.50)/0.05)**2)**0.5, feature)) # 对distance的集合 元素从小到大排序(返回的是排序的下标位置) sortindex = (np.argsort(distance)) # 用排序的sortindex来操作 label集合 sortlabel = (label[sortindex]) return c.Counter(sortlabel[0:k]).most_common(1)[0][0] if __name__== ‘__main__‘: #导入训练集 traindata = np.loadtxt("data1-train.csv",delimiter = ",") #输入值,取第一列和第二列 feature = (traindata[:,0:2]) #结果label label = traindata[:,-1] #导入测试集 testdata = np.loadtxt("data1-test.csv",delimiter = ",") # knn算法的k :取最近的k个数据 count = 0 k = int(len(traindata)**0.5) for item in testdata: predict = knn(k,item[0],item[1],feature,label) real = item[-1] if predict == real: count = count + 1 print(f‘k = {k},准确率 : {count * 100.0 / len(testdata)}%‘) """ k = 69,准确率 : 21.0% """
原文:https://www.cnblogs.com/pam-sh/p/13172487.html