我们在写爬虫的时候,偶尔会遇到一些内容是通过js获取,或者加密等一些情况,那么这种情况就需要使用selenium了。
Selenium是一个web自动化测试工具,简单理解就是通过指令模拟在浏览器中的点击、拖拽、输入、执行js脚本等功能。现在很多网页中包含大量js脚本,分析并构造http请求变得非常复杂,这时候selenium的优势就体现出来了:无需考虑复杂的get/post请求,仅需要模拟各类点击、输入等动作,代替人力完成重复、繁琐的工作,可以作为一种网络爬虫的工具。当然,其缺点也非常明显:速度慢,无法胜任大规模数据的快速获取工作。
直接用命令安装:python -m pip install selenium
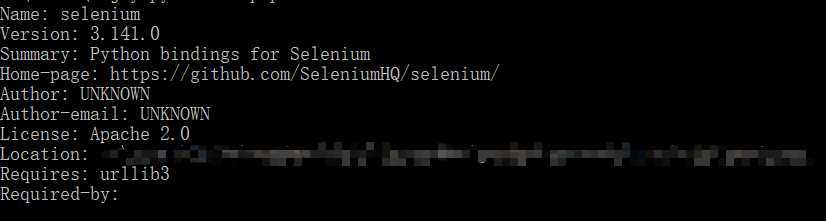
安装完成后,输入python -m pip show selenium可查看当前的selenium版本
不同的浏览器需要安装不同的驱动程序且版本需对应。
IE浏览器驱动_______下载地址:http://docs.seleniumhq.org/download/
Firfox浏览器驱动____下载地址:https://github.com/mozilla/geckodriver/releases
Chrome浏览器驱动__下载地址:http://chromedriver.storage.googleapis.com/index.html
Edge浏览器驱动____下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
将刚刚下载下来的驱动文件解压出来,得到一个exe文件,然后新建一个文件夹用来保存这些驱动文件,例:
D:\webdriver
随后我们将该文件夹路径添加进系统的环境变量里
我的电脑 —— 右键属性 —— 高级系统设置 —— 环境变量 —— 系统变量
找到path值,将D:\webdriver路径添加进去
完成了webdriver的安装配置,便可以通过selenium来控制浏览器了
from selenium import webdriver
import time
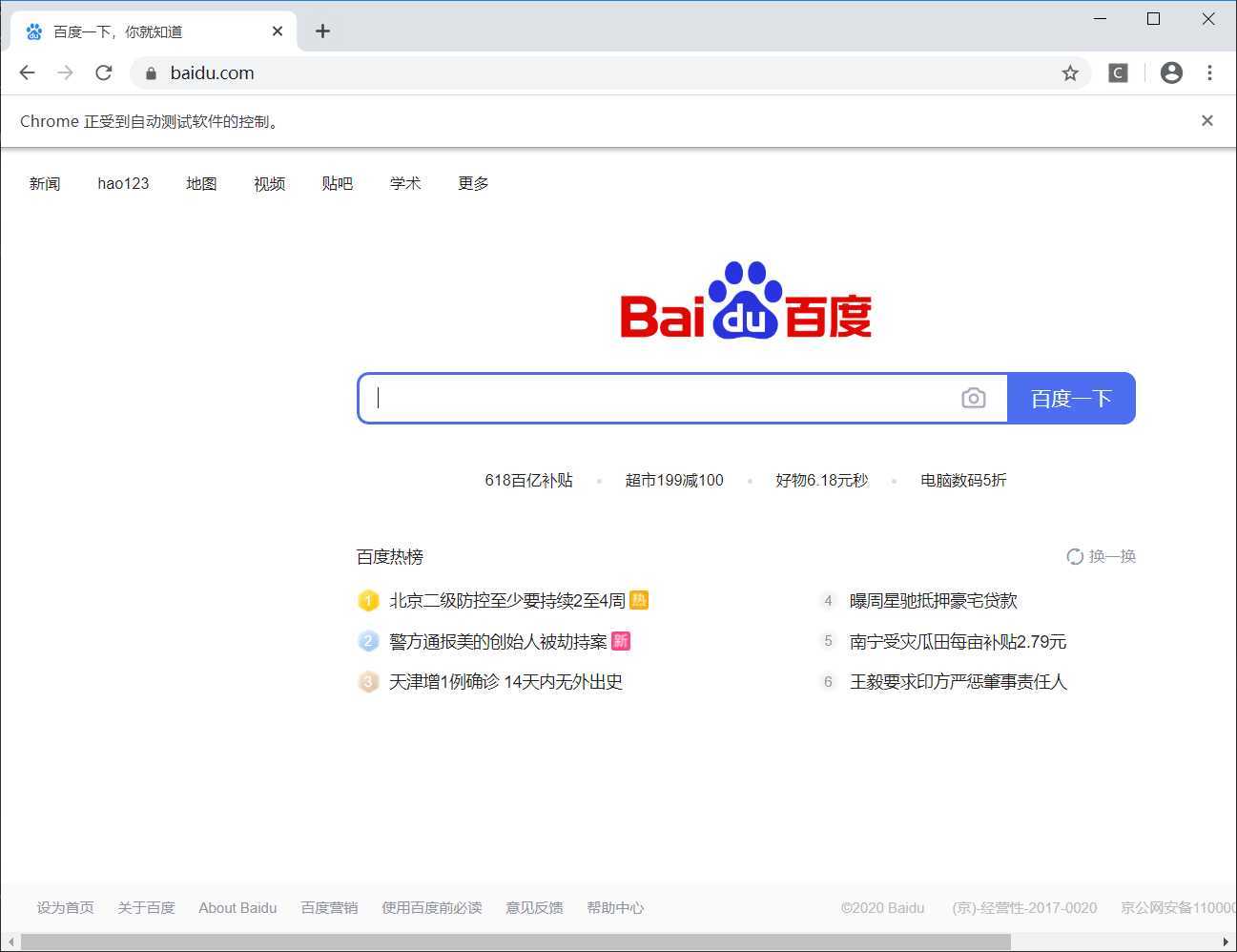
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com‘)
time.sleep(5)
browser.close()
运行这段代码,浏览器会打开百度首页,在等待5秒之后,将会自动关闭,程序结束
原文:https://www.cnblogs.com/myquark/p/13156992.html