1.栈 先进后出
2.队列 先进先出
3.数组 查询快,增删慢
因为有索引,可以快速定位, 但凡要添加或者删除一个元素,都要重新创建新的数组, 还要将老的数据原封不动的拷贝,非常耗时
4.链表 查询慢,增删快
因为每次都从头或者从尾开始查, 只需要断开或者链接一个节点就可以增删, 没必要动全身
5.红黑树---> TreeSet, TreeMap 查询快, 可以排序
因为底层趋近于平衡树, 类似折半查找, 查找速率特别快
底层在取出来的时候,有自己的规则
6.哈希表--->HashSet 查询快
1.8之前: 数组和链表 1.8之后(包含1.8):数组和链表+红黑树
首先会拿到元素的hashCode的返回值, 去数组去看有没有hash冲突,如果没有,直接存入, 如果有, 就挂在该数组对应的hash值的链表下面
由于通过hashcode的值来分组,所以在查询的时候特别快
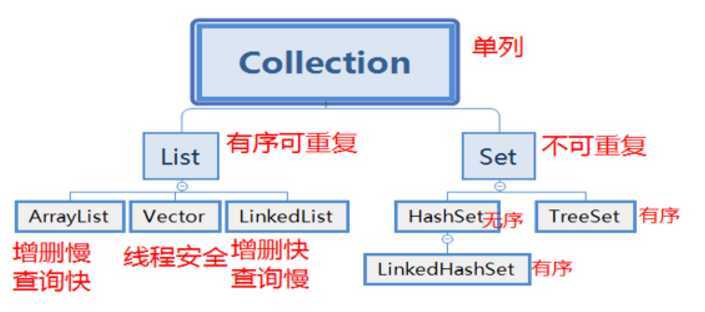
1.有序(元素存入集合的顺序和取出的顺序一致。
2.元素都有索引。
3.元素可以重复。
|--ArrayList:底层的数据结构是数组,线程不同步,ArrayList替代了Vector,查询元素的速度非常快。
|--LinkedList:底层的数据结构是链表,线程不同步,增删元素的速度非常快。
|--Vector:底层的数据结构就是数组,线程同步的,Vector无论查询和增删都巨慢。
可变长度数组的原理:
当元素超出数组长度,会产生一个新数组,将原数组的数据复制到新数组中,再将新的元素添加到新数组中。
ArrayList:是按照原数组的50%延长。构造一个初始容量为 10 的空列表。
Vector:是按照原数组的100%延长。
注意:对于list集合,底层判断元素是否相同,其实用的是元素自身的equals方法完成的。所以建议元素都要复写equals方法,建立元素对象自己的比较相同的条件依据。
1. 没有索引 --->不可以用普通for循环遍历
2.不可以重复
3.大部分都是无序
|--HashSet:底层数据结构是哈希表,线程是不同步的。无序,高效;
|--LinkedHashSet:有序,hashset的子类。
|--TreeSet:对Set集合中的元素的进行指定顺序的排序。不同步。TreeSet底层的数据结构就是二叉树。
HashSet集合保证元素唯一性:
通过元素的hashCode方法,和equals方法完成的。
当元素的hashCode值相同时,才继续判断元素的equals是否为true。
如果为true,那么视为相同元素,不存。如果为false,那么不判断equals直接存储,从而提高对象比较的速度。
TreeSet集合的指定顺序排序:
Comparable和Comparator
1:让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
2:让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。
对于ArrayList集合,判断元素是否存在,或者删元素底层依据都是equals方法。
对于HashSet集合,判断元素是否存在,或者删除元素,底层依据的是hashCode方法和equals方法。
它的出现给集合操作提供了更多的功能。这个类不需要创建对象,内部提供的都是静态方法。
静态方法:
Collections.sort(list);//list集合进行元素的自然顺序排序。
Collections.sort(list,new ComparatorByLen());//按指定的比较器方法排序。
class ComparatorByLen implements Comparator<String>{
public int compare(String s1,String s2){
int temp = s1.length()-s2.length();
return temp==0?s1.compareTo(s2):temp;
}
}
Collections.max(list); //返回list中字典顺序最大的元素。
int index = Collections.binarySearch(list,"zz");//二分查找,返回角标。
Collections.reverseOrder();//逆向反转排序。
Collections.shuffle(list);//随机对list中的元素进行位置的置换。
将非同步集合转成同步集合的方法:Collections中的 XXX synchronizedXXX(XXX);
List synchronizedList(list);
Map synchronizedMap(map);
原理:定义一个类,将集合所有的方法加同一把锁后返回。
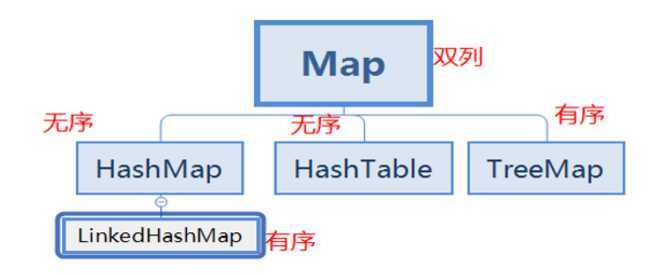
1.存储的是时候是一对一对往里面存储
2.键不能重复
|--Hashtable:底层是哈希表数据结构,是线程同步的。不可以存储null键,null值。
|--HashMap:底层是哈希表数据结构,是线程不同步的。可以存储null键,null值。替代了Hashtable.
|--TreeMap:底层是二叉树结构,可以对map集合中的键进行指定顺序的排序。
HashSet的底层实现依赖HashMap,实际上是将Key作为HashSet的值,使用统一的Value来存储的。
HashMap的底层是数组+链表,在jdk1.8之后 这个链表长度超过8 则转换为红黑树 ,数组和链表中存储的是 Entity<key-value>对象,如果key的hashCode值相同则挂在数组的所指向的链表中。

原文:https://www.cnblogs.com/indexlm/p/13125336.html