//boolean retainAll(Collection<?> c); 两个集合的交集,返回值表示该集合是否发生变化(仅保留此列表中包含在指定集合中的元素)
List l1=new ArrayList();
List l2=new ArrayList();
l1.add("java");
l1.add("c++");
l1.add("python");
l2.add("java");
System.out.println(l1.retainAll(l2));//true
System.out.println(l2.retainAll(l1));//false
System.out.println(l1);//[java]
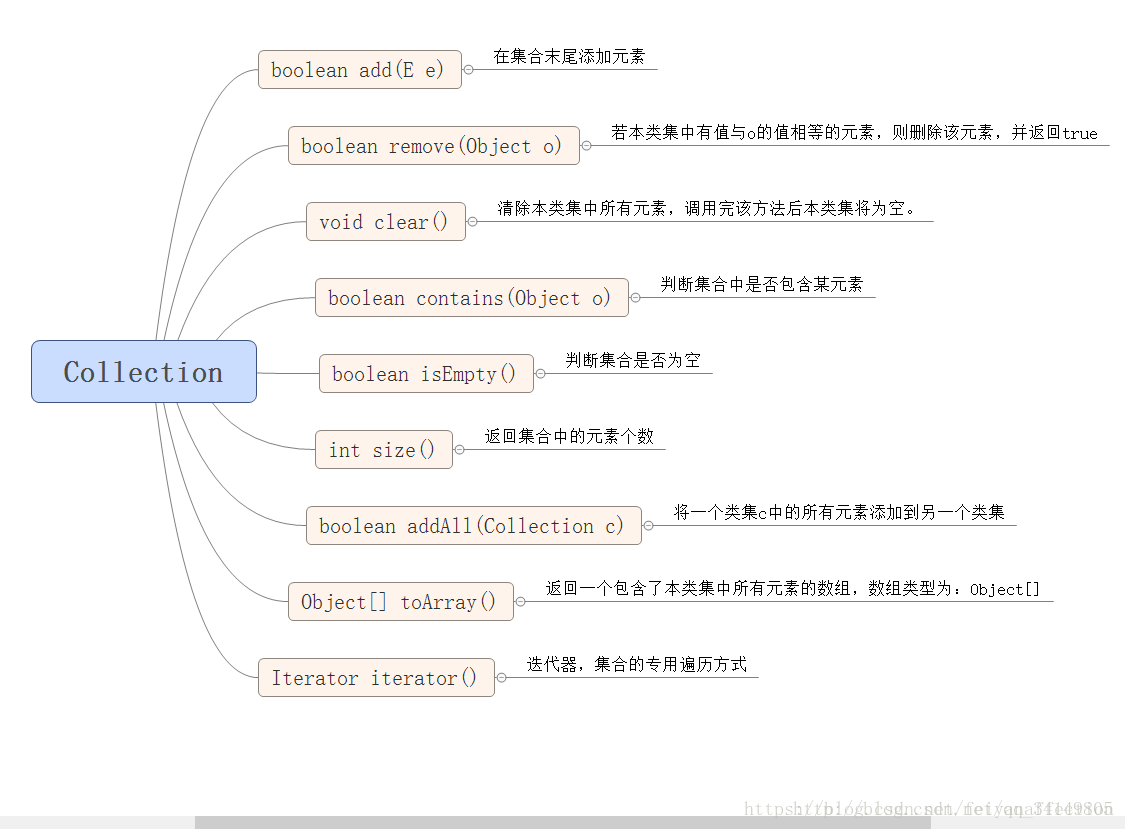
//Iterator<E> iterator(); 迭代器,集合的专用遍历方式
List l1=new ArrayList();
l1.add("java");
l1.add("c++");
l1.add("python");
Iterator iterator = l1.iterator();
while (iterator.hasNext()){//判断是否有下一个元素,如果有,返回true
Object next = iterator.next();//获取元素,并移动到下一位置
System.out.println(next);
}
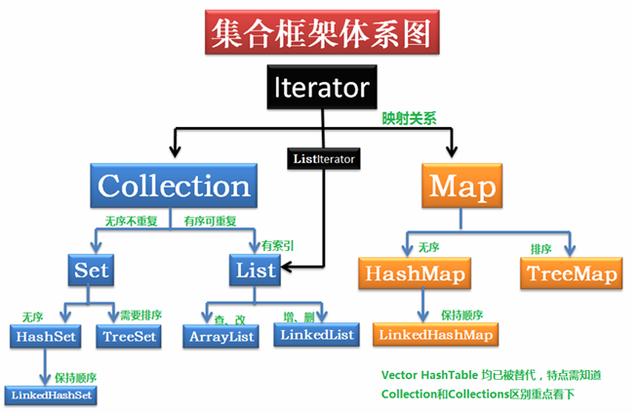
? 有序集合(有序:元素的添加顺序和取出顺序一致),元素可重复
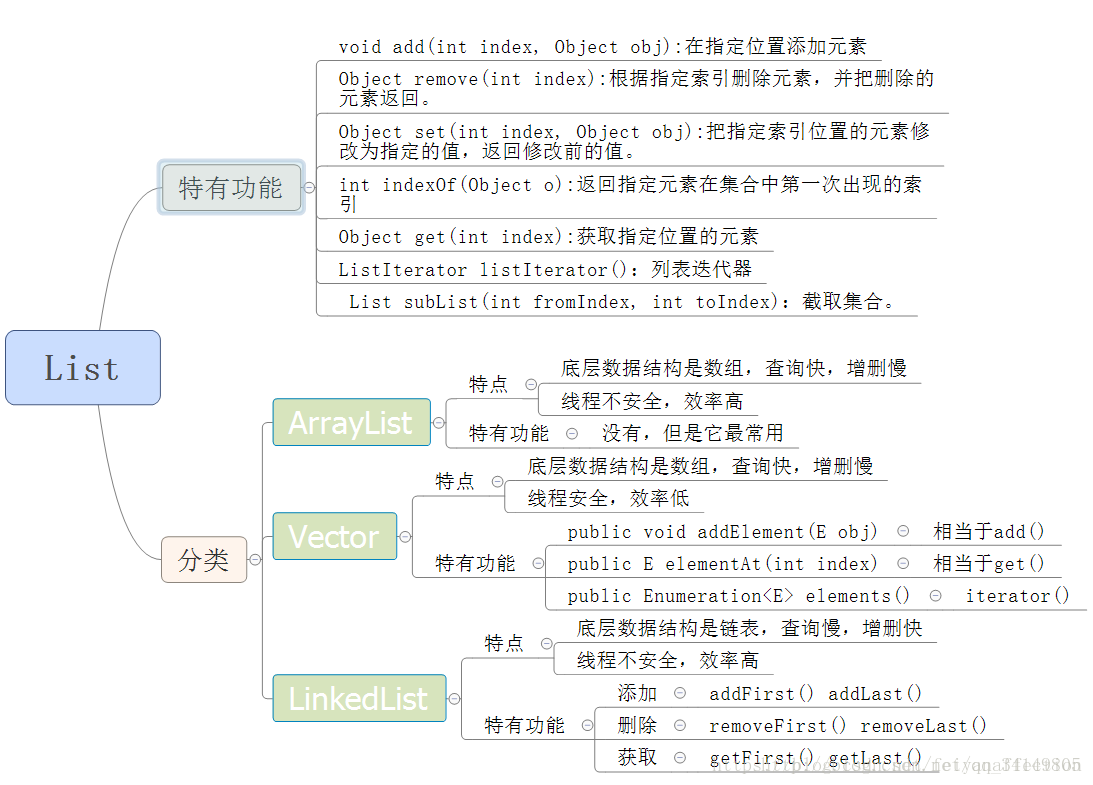
ListIterator<E> listIterator(); 列表迭代器,List专有迭代器
与Iterator()区别:
boolean hasPrevious();判断是否有上一个元素
E previous();获取上一个元素
迭代器使用过程中可能产生的问题:
List list=new ArrayList();
list.add("java");
list.add("c++");
list.add("python");
Iterator it = list.iterator();
while (it.hasNext()){
String str= (String) it.next();
if("python".equals(str)){
list.add("html");
}
}
-----------------------------------------------------------------------------------------
//当方法检测到对象的并发修改,但不允许这种修改时,会抛出该异常
Exception in thread "main" java.util.ConcurrentModificationException<br/>
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:901)<br/>
at java.util.ArrayList$Itr.next(ArrayList.java:851)<br/> at Collection.CollectionTest.main(CollectionTest.java:14)
产生的原因:迭代器依赖于集合而存在,当集合发生改变时,迭代器不知道,所以会抛出并发修改异常,迭代器遍历元素的时候,通过集合是不能修改元素的。
解决方法1:迭代器迭代元素,迭代器修改元素
ListIterator it = list.listIterator();
while (it.hasNext()){
String str= (String) it.next();
if("python".equals(str)){
it.add("html");
}
}
解决方法2:集合遍历元素,集合修改元素
for (int i = 0; i < list.size(); i++) {
String sub = (String) list.get(i);
if(sub.equals("java")){
list.add("javaee");
}
System.out.println(sub);
}
无序集合(无序:元素的添加顺序和取出顺序不一致),元素不可重复
HashSet的实现方式大致如下,通过一个HashMap存储元素,元素是存放在HashMap的Key中,而Value统一使用一个Object对象。
private static final Object PRESENT = new Object();
//通过一个HashMap存储元素
public HashSet() {
map = new HashMap<>();
}
//元素是存放在HashMap的Key中,而Value统一使用一个Object对象。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashSet之覆盖hashCode方法和equals方法来保证元素唯一性
通过对象的(利用hash算法生成)hashCode和equals方法来完成对象唯一性的:
->如果对象的hashCode值不同,那么不用判断equals方法,就直接存储到哈希表中。
->如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true:
->如果为true,视为相同元素,不存;如果为false,那么视为不同元素,就进行存储。
记住:如果对象要存储到HashSet集合中,该对象必须覆盖hashCode方法和equals方法,如果不重写这两个方法,则默认使用Object类的hashCode方法和equals方法,每个对象的hashcode值都不相同,所以会直接储存到哈希表中。
? 自然排序
Java常用类中已经实现了Comparable接口的类有以下几个:
? BigDecimal、BigDecimal以及所有数值型对应的包装类:按照它们对应的数值大小进行比较。
public class BigDecimal extends Number implements Comparable<BigDecimal>
? Charchter:按照字符的unicode值进行比较。
? Boolean:true对应的包装类实例大于false对应的包装类实例。
? String:按照字符串中的字符的unicode值进行比较。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
? Date、Time:后面的时间、日期比前面的时间、日期大。
? 定制排序
想要实现定制排序,需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,TreeSet会优先按照Comparator中的compare()方法排序,compare方法中有两个参数,第一个是调用该方法的对象,第二个值集合中已经存入的对象。
TreeSet<User> integers = new TreeSet<>(new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
return 0;
}
});
综上:自然排序实现的是Comparable接口中的compareTo方法,定制排序实现的是Comparator接口中的compare()方法。
Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。
Map集合遍历
方式1: 根据键找值
HashMap<String, String> map = new HashMap<>();
map.put("it001","num1");
map.put("it002","num2");
map.put("it003","num3");
map.put("it004","num4");
//遍历
Set<String> strings = map.keySet();
for (String string : strings) {
String s = map.get(string);
System.out.println(s);
}
方式2:根据键值对对象找键和值
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
由于LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能,但在迭代访问Map里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
TreeMap 是一个有序的key-value集合,非同步,基于红黑树(Red-Black tree)实现,每一个key-value节点作为红黑树的一个节点。TreeMap存储时会进行排序的,会根据key来对key-value键值对进行排序,其中排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法。
自然排序:TreeMap中所有的key必须实现Comparable接口,并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
定制排序:定义TreeMap时,创建一个comparator对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。
TreeMap判断两个元素相等的标准:两个key通过compareTo()方法返回0,则认为这两个key相等。
如果使用自定义的类来作为TreeMap中的key值,且想让TreeMap能够良好的工作,则必须重写自定义类中的equals()方法,TreeMap中判断相等的标准是:两个key通过equals()方法返回为true,并且通过compareTo()方法比较应该返回为0。
原文:https://www.cnblogs.com/lzhya/p/13125409.html