反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie在本地,之后请求地址url2,带上了之前的cookie,代码中也可以这样去实现。
很多时候,爬虫中携带的headers字段,cookie字段,url参数,post的参数很多,不清楚哪些有用,哪些没用的情况下,只能够去尝试,因为每个网站都是不相同的。当然在盲目尝试之前,可以参考别人的思路,我们自己也应该有一套尝试的流程。
通过User-Agent字段反爬的话,只需要给他在请求之前添加User-Agent即可,更好的方式是使用User-Agent池来解决,我们可以考虑收集一堆User-Agent的方式,或者是随机生成User-Agent
该字段的值都是上一级网站的url,检测来源的合法性,可以知道通过某某url路径过来的,那么就可以判断来源是否合法,如果异常的话就可以做拦截请求等等,例如豆瓣电视剧中,通过referer字段来反爬,我们只需要添加上即可
如果目标网站不需要登录 每次请求带上前一次返回的cookie,比如requests模块的session
如果目标网站需要登录 准备多个账号,通过一个程序获取账号对应的cookie,组成cookie池,其他程序使用这些cookie
在请求目标网站的时候,我们看到的似乎就请求了一个网站,然而实际上在成功请求目标网站之前,中间可能有通过js实现的跳转,我们肉眼不可见,这个时候可以通过点击perserve log按钮实现观察页面跳转情况
在这些请求中,如果请求数量很多,一般来讲,只有那些response中带cookie字段的请求是有用的,意味着通过这个请求,对方服务器有设置cookie到本地
对应的需要分析js,可采用selenium去实现,会变得比较容易。
对应的需要分析js,可采用selenium去实现,会变得比较容易。
通过打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐。列举常见的验证码的种类:
这是验证码里面非常简单的一种类型,对应的只需要获取验证码的地址,然后请求,通过打码平台识别即可
这种验证码的类型是更加常见的一种类型,对于这种验证码,大家需要思考:
在登录的过程中,假设我输入的验证码是对的,对方服务器是如何判断当前我输入的验证码是显示在我屏幕上的验证码,而不是其他的验证码呢?
在获取网页的时候,请求验证码,以及提交验证码的时候,对方服务器肯定通过了某种手段验证我之前获取的验证码和最后提交的验证码是同一个验证码,那这个手段是什么手段呢?
很明显,就是通过cookie来实现的,所以对应的,在请求页面,请求验证码,提交验证码的到时候需要保证cookie的一致性,对此可以使用requests.session来解决
同一个ip大量请求了对方服务器,有更大的可能性会被识别为爬虫,对应的通过购买高质量的ip的方式,去维护一个ip池可以高效的解决。
利用自定义的字符编码与字体文件的映射呈现文字的一种反爬措施,前端加载时,再利用自定义字体去进行解析。
下图来自猫眼电影电脑版
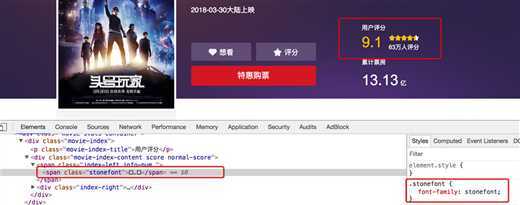
解决思路:切换到手机版或者获取到编码方式
1、网站中,页面正常显示,但是源代码中却找不到的正确展示信息,对应的标签中的信息是错误的,仔细可以看出开发者们在CSS样式动了手脚。
2、css偏移反爬虫,在反爬技术中也用得比较多的,都是为阻止爬虫工程师采集页面的数据,它的特点在于计算。源代码中,它们的数据错乱不堪,但是前端工程师则通过css排版,将源代码中的数据显示在页面中,如果爬虫程序想正确的得到页面数据,则要计算出css数据排版规律。
下图来自猫眼去哪儿电脑版
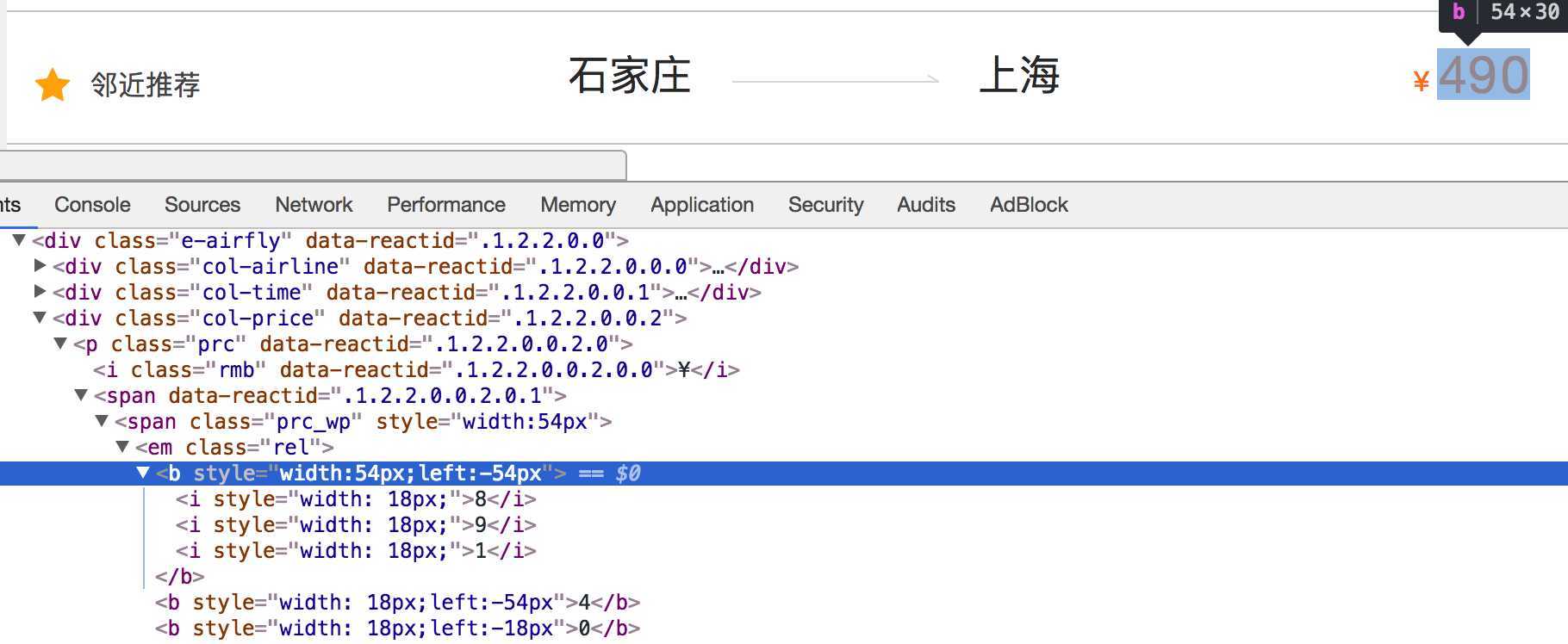
解决思路:计算css的偏移
原文:https://www.cnblogs.com/caijunchao/p/13096447.html