
关于 Elaticsearch
对于有搜素需求的公司这个东西应该都不陌生,且他在运维领域也得到了广泛应用,这两年听到的 ELK STACK 中的 E 就是 Elasticsearch,我们一般把他简称为 ES,当然如果你的公司技术还是很古老,但是又有全文检索功能,那么你可能就用到的不是 ES,可能就会是 Lucene。
它是一个功能强大的搜索库,基于 Lucene 开发,在 Lucene 的基础上优化了使用,提供了简单易用的 Restful api 接口,完全开源。同时也是一个分布式文档存储引擎,搜索分析引擎,支持 PB 级数据处理,开箱即用,配置简单。常用于分布式搜索,全文检索,结构化检索,数据分析,对海量数据进行近乎实时处理。而 Lucene 只能单机。
在日常生活中,我们熟知的公司有广泛的应用,如:
百度的搜索,关键字高亮,Github 的搜索,电商网站的商品检索,运维领域的日志收集和分析,很多 BI 数据分析系统等。
在 ES 中有以下常用的概念性东西,作为存储引擎,可以比对着 MySQL 进行理解:
1. Node(节点)和 Cluster(集群),在 ES 集群中会用到,集群名称是集群的唯一标识,Node 名称是节点的唯一标识。
2. Index(索引),相当于 MySQL 中数据库。
3. Type(类型),相当于 MySQL 中表。
4. Document(文档),相当于 MySQL 中数据行。
5. Filed(列),相当于 MySQL 中字段。
至于分片,复制这些概念后面用到的时候再做说明。
单节点 ES 安装
1. 安装准备
准备一台虚拟机:192.168.200.101,系统 CentOS 7.7,关闭防火墙,Selinux。
下载安装包:
但是由于众所周知的原因,下载特别慢,这里推荐使用华为云镜像站:
包括后续的安装包都可以在这里下,速度贼快。同时建议下载 JDK,为了和公司生产统一,我这里就使用 JDK8,ES 其实是自带 JDK 的,且版本还比较新。
项目目录创建:
mkdir -p /data/{logs,packages,services,env-tools}
目录结构说明:

所有内容都存放在 data 目录下,packages 用于存放安装包,logs 存放服务的日志,services 用于作为服务安装目录,env-tools 用于系统环境工具安装目录,如 JDK。
这样规划的好处就是安装的服务文件不会到处放,到时候卸载这些操作的时候比较好处理,更干净整洁。
系统参数优化(必须):为了配置完全生效,需要重启服务器。
echo ‘vm.max_map_count=655360‘ > /etc/sysctl.conf echo ‘DefaultLimitNOFILE=65536 DefaultLimitNPROC=32000 DefaultLimitMEMLOCK=infinity‘ >> /etc/systemd/system.conf
配置 JDK:上传 JDK 包到 /data/packages 下面
# 解压 cd /data/packages tar -zxf jdk-8u45-linux-x64.tar.gz mv jdk1.8.0_45/ /data/env-tools/jdk8 # 添加环境变量并应用 echo ‘# JDK8 ENV export JAVA_HOME=/data/env-tools/jdk8 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH‘ >> /etc/profile source /etc/profile # 查看结果 java -version
2. 安装配置 ES
cd /data/packages tar -zxf elasticsearch-7.7.0-linux-x86_64.tar.gz mv elasticsearch-7.7.0 /data/services/elasticsearch # 创建数据目录 mkdir /data/services/elasticsearch/data cd /data/services/elasticsearch/config ls -l
结果如下:
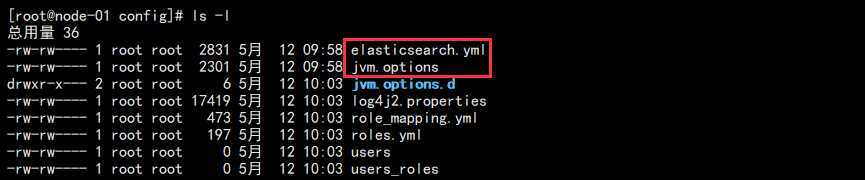
其中 elasticsearch.yml 为主配置文件,jvm.options 为内存配置文件。
配置:elasticsearch.yml
# 集群名称,虽然现在只有单机,但是并不影响,该名称用于区分不同集群,所以要唯一 cluster.name: ELK-Cluster # 节点名称,用于区分集群内节点,要求唯一 node.name: ELK-Node-01 # 数据目录,刚刚创建的 path.data: /data/services/elasticsearch/data # 日志目录 path.logs: /data/services/elasticsearch/logs # 是否内存锁定,建议开启,这样其它服务不会抢占分配给 ES 的内存 bootstrap.memory_lock: true # 本机IP network.host: 192.168.200.101 # 端口 http.port: 9200 # 集群内的主机 discovery.seed_hosts: ["192.168.200.101"] # 集群初始化节点 cluster.initial_master_nodes: ["ELK-Node-01"] # 跨域访问和用户认证,用于提供给其它服务使用 http.cors.enabled: true http.cors.allow-origin: "*" http.cors.allow-headers: "*" xpack.security.enabled: true xpack.security.transport.ssl.enabled: true
配置:jvm.options
-Xms1g
-Xmx1g
根据自己实际情况分片响应的内存,这里测试就给默认的 1G。注意最大最小要一致。
建议最大的内存分配不要超过 32G,据官方所说,超过 32G 反而影响性能。
3. 配置启动 ES
由于 ES 默认不支持 root 用户启动,所以这里新建一个用户用于管理 ES:
useradd elk
chown -R elk.elk /data/services/elasticsearch
配置 systemd 管理 ES,这样就不用每次启动都切换用户:
echo ‘[Unit] Description=Elasticsearch Documentation=http://www.elastic.co Wants=network-online.target After=network-online.target [Service] Type=simple User=elk Group=elk LimitNOFILE=100000 LimitNPROC=100000 Restart=no ExecStart=/data/services/elasticsearch/bin/elasticsearch PrivateTmp=true [Install] WantedBy=multi-user.target‘ > /usr/lib/systemd/system/elasticsearch.service
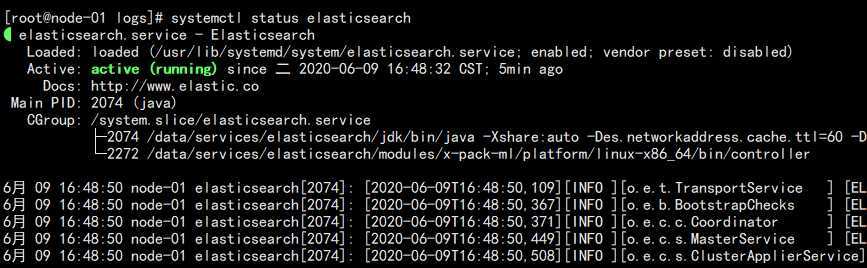
启动 ES:
systemctl daemon-reload
systemctl start elasticsearch
systemctl status elasticsearch
systemctl enable elasticsearch
结果如下:
4. 用户认证配置:
在公有云环境中经常出现 ES 被攻击导致数据泄露,和 redis 一样,服务如果直接暴露在外网,过不了多久机器就会被挖矿。所以为了安全起见,可以采取以下手段:
1. 设置用户密码。
2. 禁止该服务外网访问。
3. 安全组不打开相关的端口(9200/9300)
这里以配置用户为例,由于之前配置文件中已经添加了用户认证的配置,所以直接添加用户即可:
/data/services/elasticsearch/bin/elasticsearch-setup-passwords interactive
这里我设置的都是 123456,包括很多组件连接的密码,效果如图:
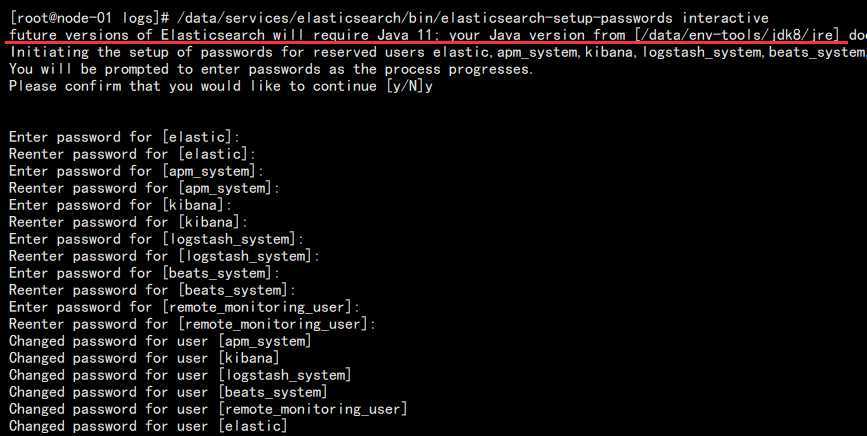
红色部分的提示不用管,只是告诉我们 JDK 版本低了,不影响使用。
5. 访问查看:http://192.168.200.101:9200/
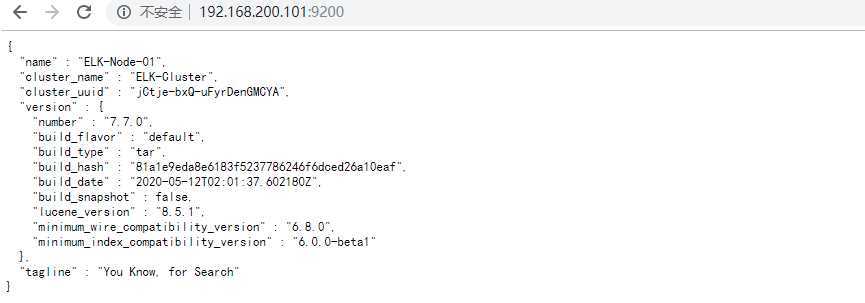
用户名密码就是之前我们设置的:elastic / 123456
原文:https://www.cnblogs.com/Dy1an/p/13073840.html