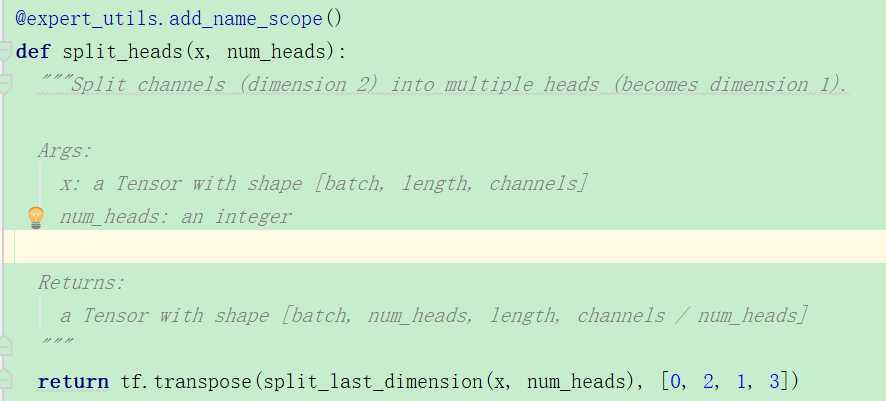
多头注意力,我们可以看到源码中是进行了切割,从return的shape可以看出来。
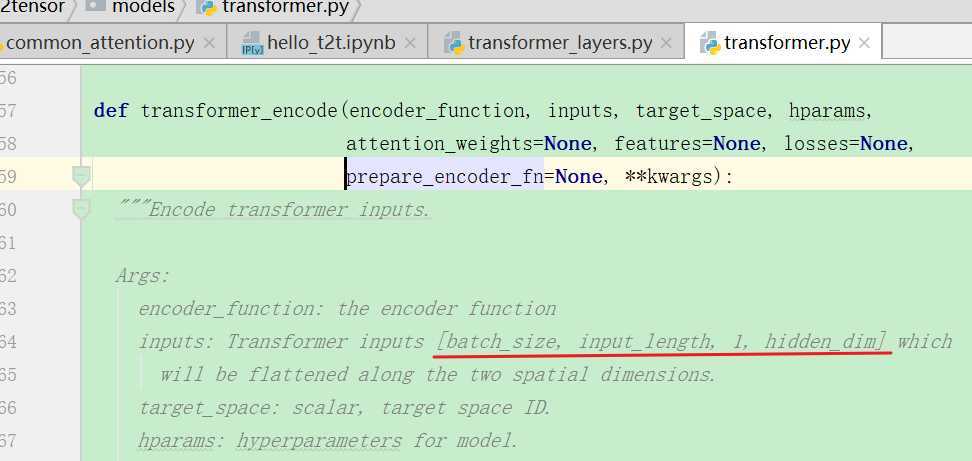
可以看到它的输入就是经过emb和位置编码求和之后的输入。下面是正式使用到的编码函数:
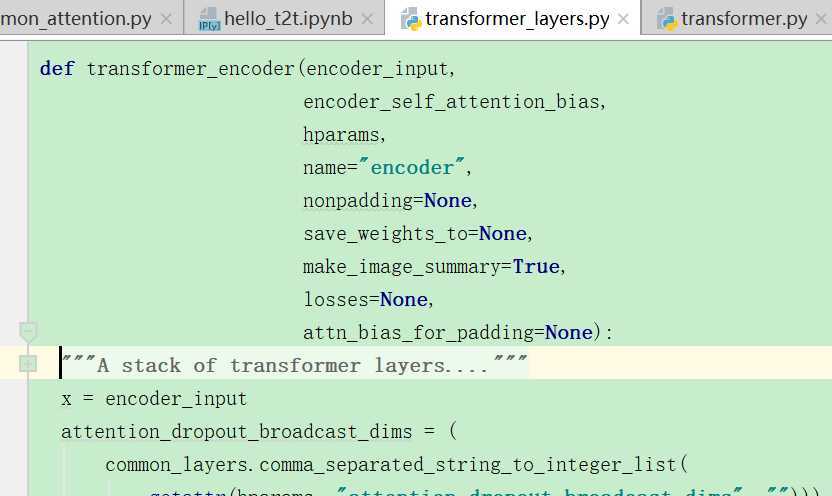
上面的编码函数中,主要调用还是多头注意力这个函数:
调用的语句:

//注意,这里每次调用的时候第二个参数,也就是memory都是None,也就是query=momery。
可以看到下面的query_antecedent就是经过预处理之后的输入,memory一开始是为None的。
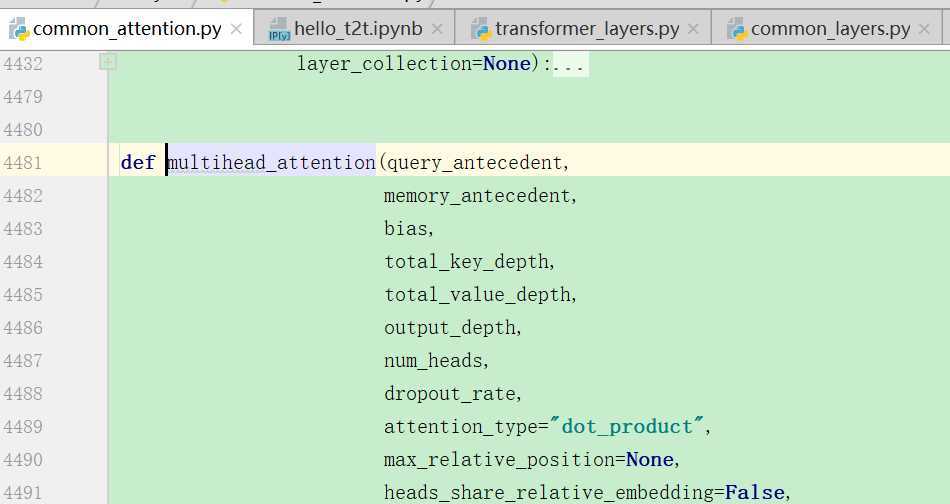
进入上面的函数后,因为一开始的时候memory是None,那么就调用计算qkv的函数:

首先是对Q的计算:

看起来这个过程也非常地简单,就是之前输入的变换*一个var(服从正态分布的随机取样的矩阵),Q=pre_process(input)*var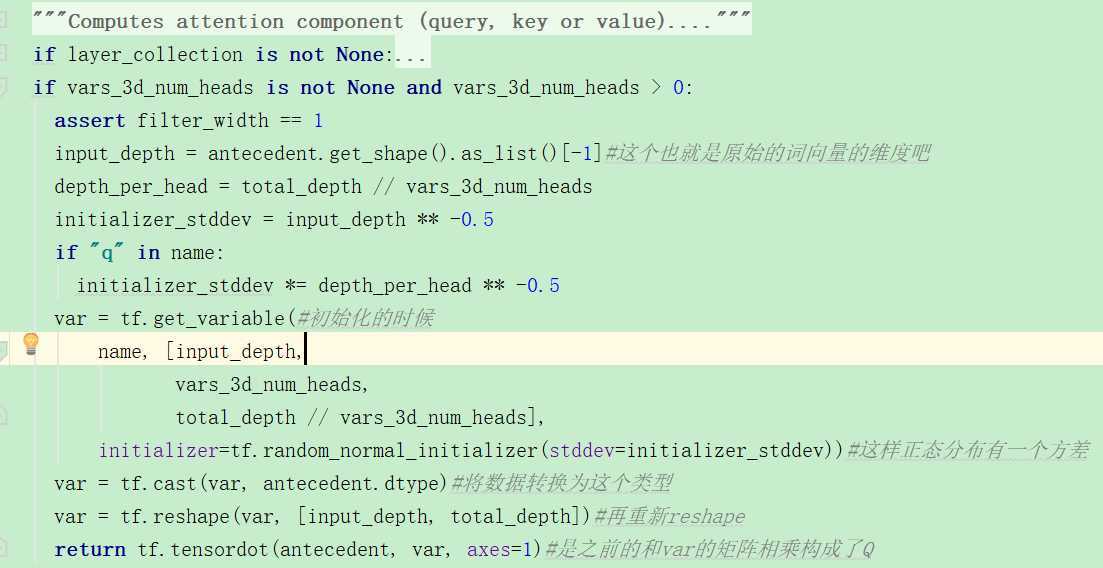
计算KV也是调用同样的函数,但是所用的ante不同,kv需要的是memory,但是此时因为memory是None,

compute一开始将query赋值给了memory:
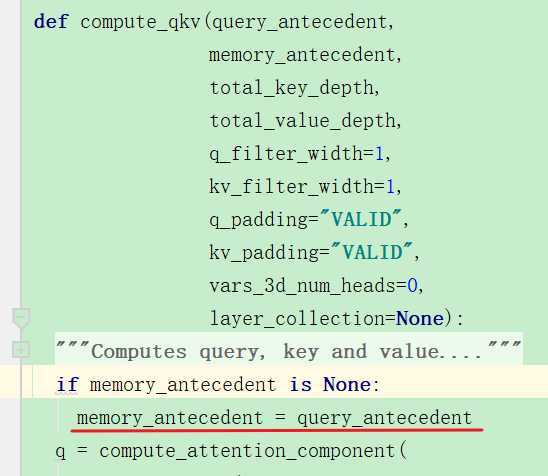
然后把qkv切成了8个部分进行之后的

下面进行attention操作:

具体的公式操作的部分标注出来:
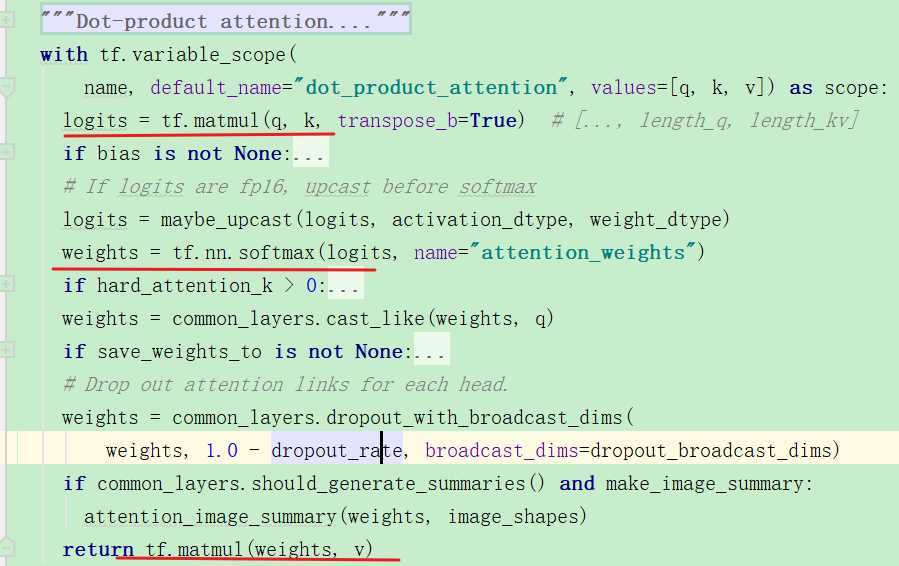
上面计算完attention之后,又有了一个o:

但是我不太明白这个o是干嘛用的,也许它只是用来做一个变换。
在transformer_layers.py文件中,在调用了common_attention.multihead_attention:
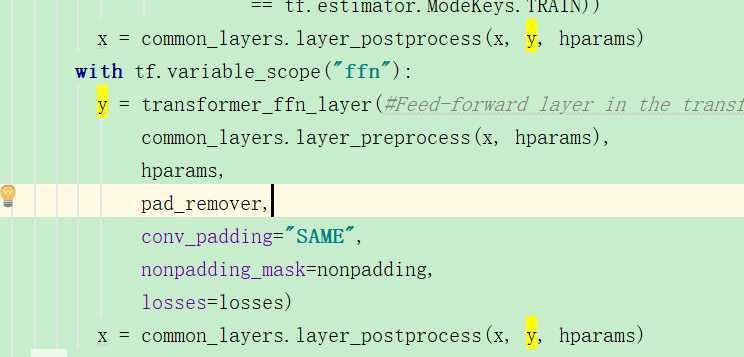
可以看到返回y之后,然后进行了后处理得到x,之后又进行了全连接层,之后又后处理,然后有一个for循环,共有几层,encoder应该是6层,那么就是6次循环了。这样就获取到了encoder的输出:

之后就返回到了这里?encoder输出结果。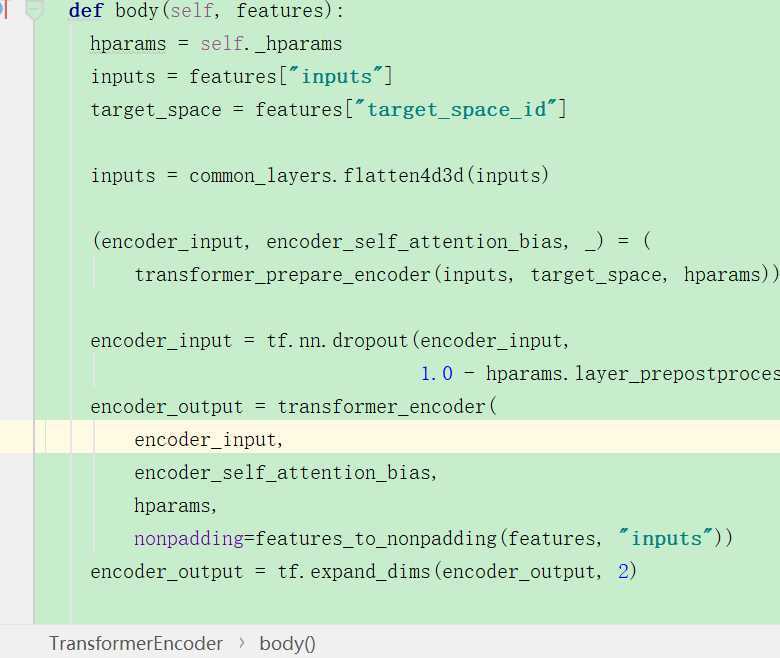
原文:https://www.cnblogs.com/BlueBlueSea/p/13055916.html