第十五周 Spark编程基础
~/spark-2.4.5/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster ~/spark-2.4.5/examples/jars/spark-examples_2.11-2.4.5.jar
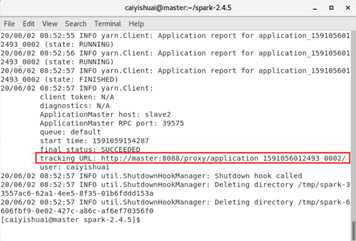
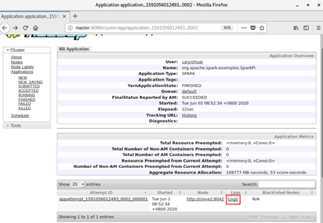
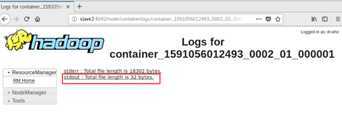
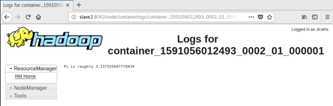
2.1 从文件系统中加载数据创建RDD
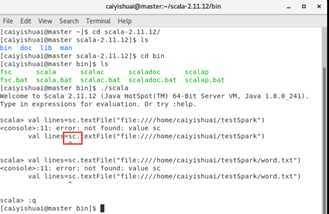
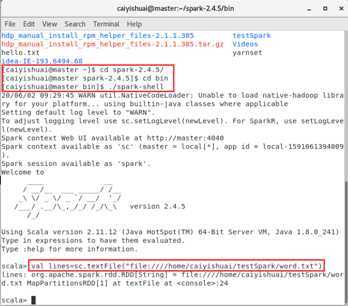
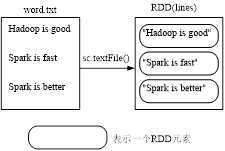
2.1.1 从本地文件系统中加载数据创建RDD
文件中的信息如下图所示:
 、
、
hadoop fs –mkdir testSpark
hadoop fs –put word.txt /testSpark
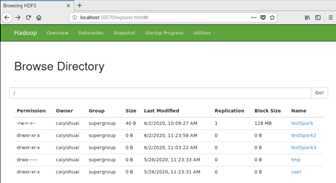
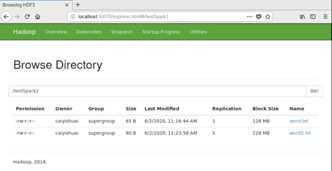
在浏览器中输入master:50070可以查看hdfs详细信息。
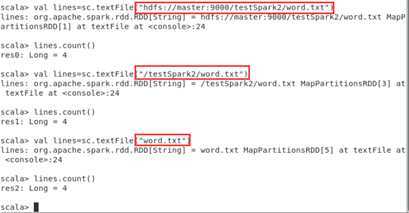
scala> val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
scala> val lines = sc.textFile("/user/hadoop/word.txt")
scala> val lines = sc.textFile("word.txt")
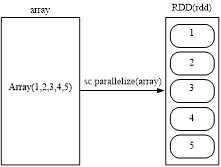
scala>val array = Array(1,2,3,4,5)
scala>val rdd = sc.parallelize(array)
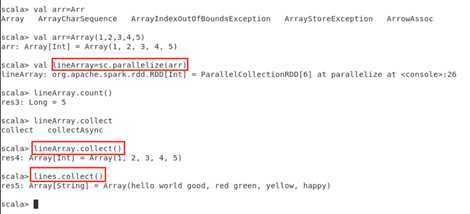
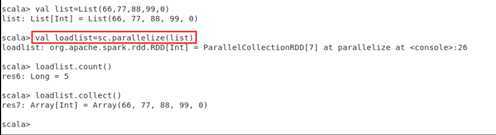
scala>val list = List(1,2,3,4,5)
scala>val rdd = sc.parallelize(list)
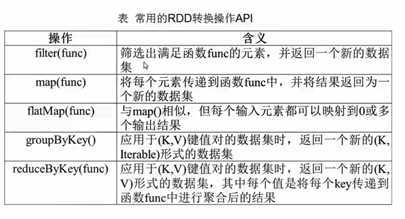
2.3.1 转化操作
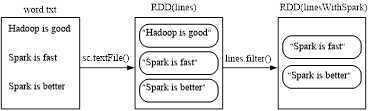
scala> val lines =sc.textFile(file:///usr/local/spark/mycode/rdd/word.txt)
scala> val linesWithSpark=lines.filter(line => line.contains("Spark"))
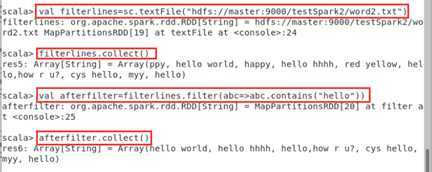
scala>val filterlines=sc.textFile("hdfs://master:9000/testSpark2/word2.txt")
scala>filterlines.collect()
scala> val filterlines=sc.textFile("hdfs://master:9000/testSpark2/word2.txt")
scala> filterlines.collect()
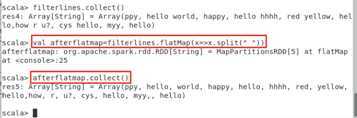
scala> val afterfilter=filterlines.filter(abc=>abc.contains("hello"))
scala> afterfilter.collect()
(2)map(func)
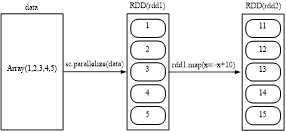
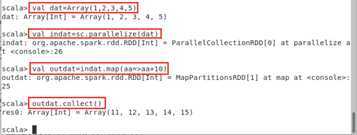
scala> val dat=Array(1,2,3,4,5)
scala> val indat=sc.parallelize(dat)
scala> val outdat=indat.map(aa=>aa+10)
scala> outdat.collect()
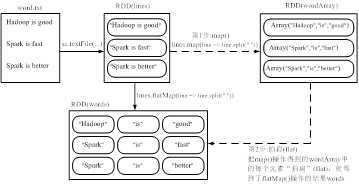
(3)flatMap(func)
scala> filterlines.collect()
scala> val afterflatmap=filterlines.flatMap(x=>x.split(" "))
scala> afterflatmap.collect()
原文:https://www.cnblogs.com/caiyishuai/p/13033842.html