from urllib import request url = "http://www.baidu.com" res = request.urlopen(url) # 获取相应 print(res.info()) # 响应头 print(res.getcode()) # 状态码 print(res.geturl()) # 返回响应地址
输出结果为:

from urllib import request url = "http://www.baidu.com" res = request.urlopen(url) # 获取相应 html = res.read() html = html.decode("utf-8") print(html)

上面这种方式是最初级的,没有考虑任何反爬机制,换个网站就行不通了
from urllib import request url = "http://www.dianping.com" res = request.urlopen(url) # 获取相应 print(res.info()) # 响应头 print(res.getcode()) # 状态码 print(res.geturl()) # 返回响应地址

最基础的措施为添加header,可以输入F12,在network选项中的Request Headers找到
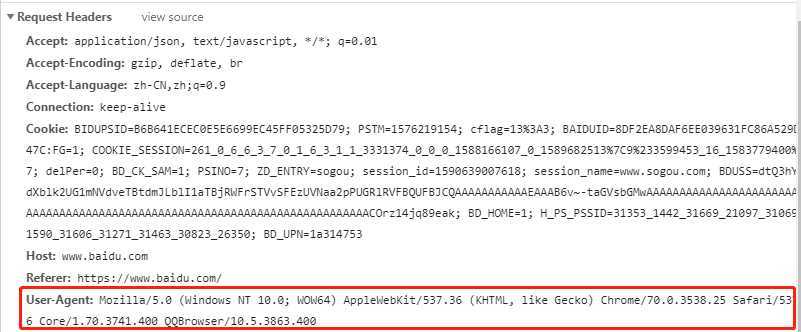
找到后,给User-Agent添加引号,对冒号后面的部分也添加引号,然后写入header变量中
再通过request.Request(url,headers=header)来发送请求
# 添加header信息,这是最基本的反爬措施 url = "http://www.dianping.com" header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400" } req = request.Request(url,headers=header) res = request.urlopen(req) # 获取响应 print(res.info()) # 响应头 print(res.getcode()) # 状态码 print(res.geturl()) # 返回响应地址
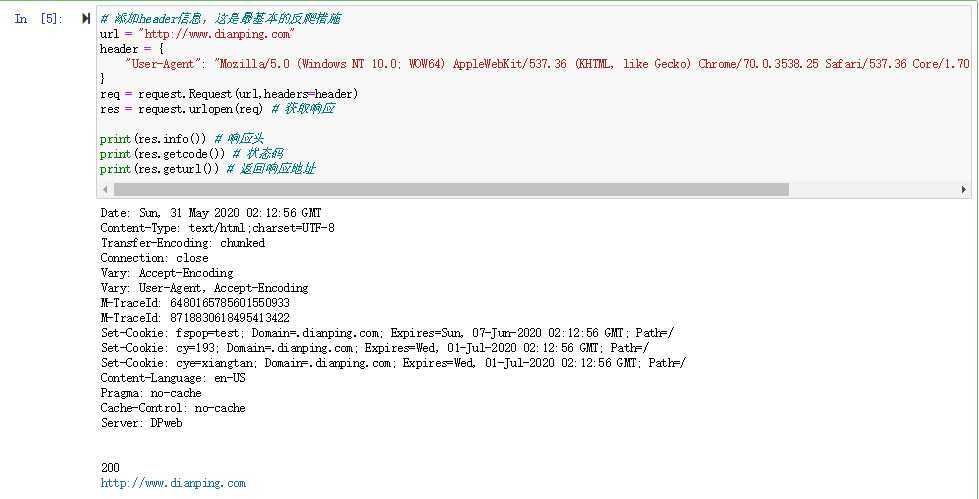
原文:https://www.cnblogs.com/cyx-b/p/12996705.html